这篇文章做了啥
这是一篇比较早的文章,做的是分割的任务,论文的架构比较清晰,主要是分析了一些现在的分割的网络存在不能够获取global信息的问题,针对这些存在的问题,作者提出了pyramid scene parsing network(PSPNet)金字塔场景解析网络,PSPnet能够extent pixel level的feature到global的feature,local和global一起能够使得预测的结果更加reliable。同时作者也提出了一个附加的loss,能更好的优化网络。
前有方法的缺点
作者首先观察到了几种状况,比如语义相关性,并且作者举了一个例子,如下图
作者说,有的方法竟然把水上的船分解为一个汽车,如果仅仅从外观上来看的话,确实会有这种情况,但是结合全局信息的话,应该不会说会存在水上有一个汽车这种情况,这里就涉及到了global信息的获取,缺少语境的话,确实容易把类别给分错。再比如,第二行里面的方框应该是摩天大楼或者是building,而不是一部分是摩天大楼和一部分是building,这个问题应该可以用用不同类别之间的关系去解决。
另外一个问题是不显然的类别,过大或者过小的类别网络的预测都会出问题,比如床上的枕头和床有相似的外观,但是分类的话,就容易分错。 网络应该对那些包含不起眼的小类别的的子区域更加关注。总的来讲,现有的方法的分类错误大都是和对不同感受野的语境关系和全局信息有关。所以作者提出了他们的金字塔pooling模型。
pyramid pooling module
在深度网络中,感受野的尺寸可以直接表明我们使用了多少语义信息。尽管理论上来说resnet的感受野已经比输入的图像大了,但是文献42中指出,经验感受越野比理论感受野小多了。尤其是对于high-level的信息。这会让网络不能够充分incorporate重大的全局场景先验。为了解决这个问题,我们提出了effective 全局先验表示。
global average pooling已经提出了利用全局语境先验,在图像分类和语义分割中都有重要的应用。尽管这样,对于ADE20K中的复杂场景,他们都没有足够的获取必要信息的能力。这些场景图中的有很多stuff和objects,如果直接用global pooling并且得到一个vector的话,可能会lose空间相关性。sub-region context上的全局语义信息对于区分不同的类别非常有帮助。由此,作者引出一个更加强大的可以在不同sub-regions上融合信息的的网络。
文献12已经提出来了通过pyramid pooling进行图像的分类,这种设计可以使得输入的图片不必是固定的尺寸,但是最后为了输入全连接层,他们不得不flatten feature map。为了减少不同sub-region的context信息的损失,作者提出了了一个有等级先验知识的,包含不同尺度的全局信息的模块。称为pyramid pooling module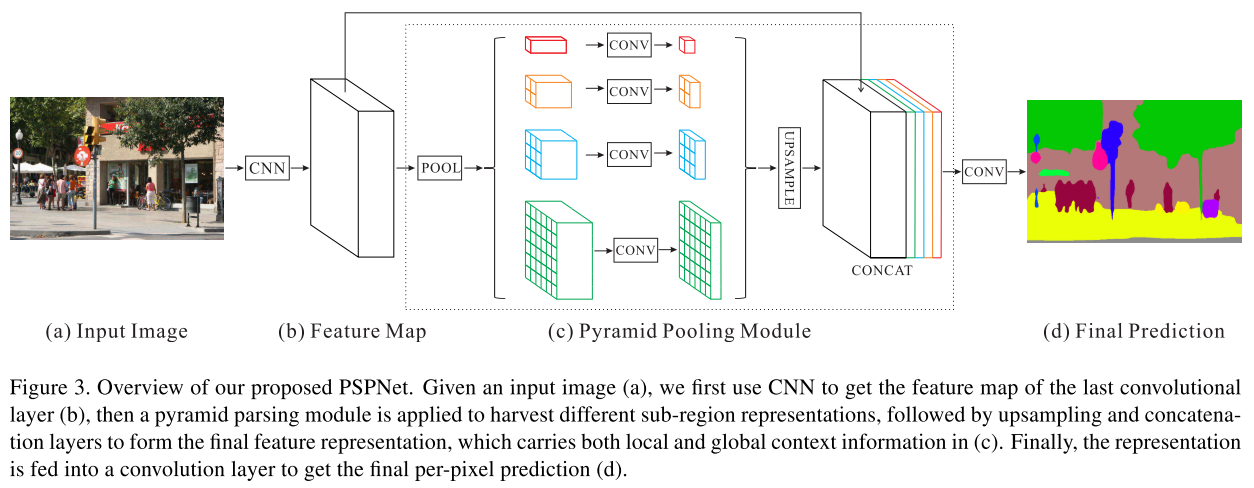
作者在这里分析还是很缜密的,比如他提出了之前的有利用global average pooling被用来做分割,但是只是有一个global模块,不能够处理很多复杂的场景。直接进行融合能够丢失信息。还有用不同pyramid pooling用图像分类的,但是这种直接flatten能够损失语义信息。
没有接触过分割,但是现在的用backbone做信息提取,然后再用不同的part做东西,感觉适用于任何dense prediction,比如单目深度估计,或者是法向量估计,或者是风格迁移啥的。但其实说到单目深度估计看过那么多paper,不太确定他们是否有使用过这种结构,一个backbone+一部分自己的东西,是否能够提高点,最简单的一个部分就是用resnet50+一部分处理,是否能够超越现有的网络,我感觉这个是一个很强的baseline。
作者提出的pyramid pooling module在四个尺度下进行信息的融合。信息损失最多的就是进行global pooling,直接输出一个数据。如上图接下来的三个部分,将输入图分成不同的sub region然后进行pool操作。不同level的输出包含不同尺寸的特征。为了maintain global feature map的权重,作者使用了11的卷积,大概是为了减少channe的数目,然后作者通过双线性插值直接unsample输入的feature。作者还在这里说,四个level的pooling的size是可以改变的,作者这里使用的pooing使得最终输出的feature map的尺寸为11,22,33,6*6
网络结构
不知道分割的套路,作者用了一个pretrained的resnet,最后输出的feature map是输入图片的1/8。然后作者用提出的pyramid pooling进行操作。将pyramid pooling处理之后的feature map和原图的feature map一起concate起来,进行上采样,最后输出分割结果。而且pspnet并不增加多少计算量,可以和网络其他部分一起优化。
实验
我没有做过分割相关的项目,所以不知道一般的评测数据集合都有哪些。作者说他们在三个不同的数据集合上进行试验,一个是imagenet scene parsing challenge2016, PASCAL VOC 2012和Cityscapes。
implementation details的话,作者在data augmentation方面上,采用了random mirror和random resize,同时,random rotation在-10到10度之间,以及添加了一些gaussian blur。说到这里,其实所有的data augmentation都是为了在test数据集合上涨点,比如,假设存在一种data augmentation的话,是真实的场景中存在的,但是测试数据集合上没有这种数据,实际上做这种data augmentation意义是不大的,当然,如果是新问题的话,那就是另外一种情况了。
在imagenet scene parsing challenge2016的结果
貌似是这个challenge用的是ADE20k的的数据集,包含150个类别,20k用于训练,2k用于验证,2k用于测试。pixel-wise acc和mean iou用来做指标。
作者首先做了一个ablation sduty, 比如,max pooling还是average pooling。然后仅仅有global pooling还是用金字塔结构的pooling,在金字塔结构是否做dimension reduction等,如下表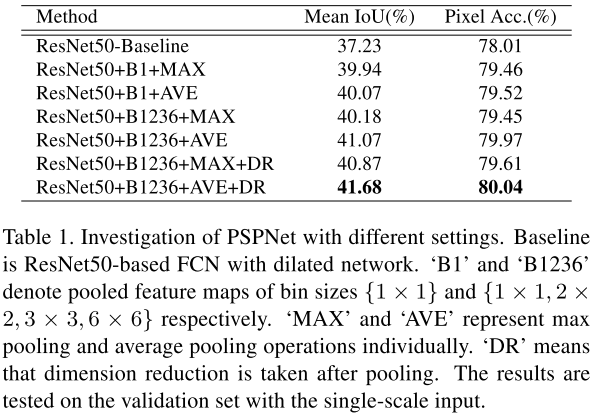
此外, 作者还对auxiliary loss进行了一个ablation,如下表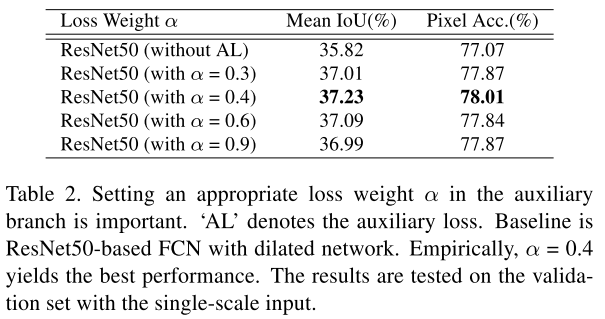
能够看出,不同的系数,对实验结果影响很大。
然后作者又对于pretrained model做了一个试验。作者试了不同的backbone,比如resnet50,101,152,269等。如下图所示,网络结构深的话,确实精度能够有所提升
作者还做了更加详细的分析,比如,da, al, psp,ms对试验结果的影响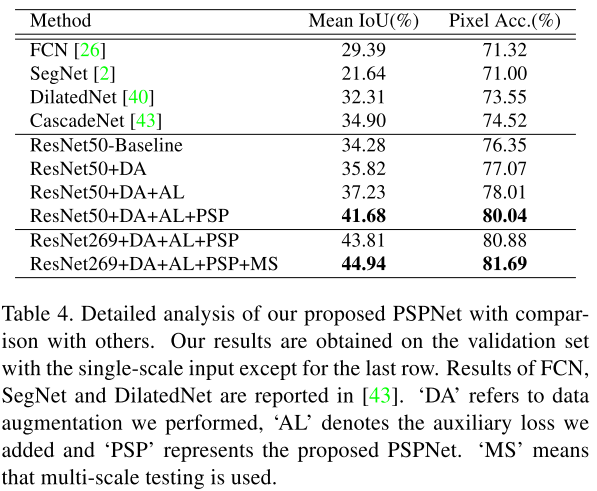
然后作者又说他们的方法在challenge2016上取得了第一名的成绩
在pascal voc 2012上的成绩
pascal voc2012上有20个类别,10582用来做训练,1449用来做验证,1456用来做测试。无论是否在MS-COCO上做finetune,我们的方法都取得了sota的结果。作者还在voc上进行了一些例子的可视化,如下图
可以看出,作者的方法能够分割出更加细致的结果
在cityspaces上的实验结果
cityspaces包含2975张训练样本,500张验证图片,和1525张测试图片,它包含19类,同时提供20000张corasely标记的图片。可以用coarse标记的图片用来做训练,但是比较的方式要公平。作者的方法也达到了sota的效果。
读后感
总的来讲,作者的主要的贡献就是提出的是一个不同尺度pooling的模块,来获取不同尺度的信息,这样对于分割获取pixel -wise或者是global的信息都是有巨大帮助的。最近在看从raw-image的论文,eth有一篇介绍了如何获取local和global信息的文章,但觉很多论文都是在围绕global和local的问题在展开。
同时作者在introduction中也说到,pyramid scene parsing module不仅仅可以用于分割,可以用于stereo matching或者是光流估计都有很大的应用,感觉这个可以试一试。
说白了其实分割就是一个dense prediction的问题,那么对于很多low-level vision的问题,也有用到resnet backbone的情况,比如deblur gan,或者是主流的pixel2pixel,都会用到这种backbone。之前也看过一些去雨或者去雾,不过都没有留意他们的backbone究竟是怎么样子的,尽管这样,好像residual block已经成为一个提取特征的公认选择。