摘要:
XPath是在使用Selenium自动测试Web UI的过程中查找页面元素的常用方法。然而,当我们想快速验证修补的XPath语句的正确性时,我们应该怎么做,因为某些元素的XPath路径太复杂了?在浏览器中打开开发人员工具,并按以下格式在Console列中输入。括号中的XPath语句是要验证的内容。输入后,将显示XPath语句定位的结果信息。将鼠标移动到结果信息,相应的Web元素可以标记在页面上。以上,通过浏览器快速验证XPath语句的目标已经实现。
在使用Selenium做Web UI自动化测试的过程中,XPath是一种定位页面元素的常用方式。然而,面对某些元素的XPath路径过于复杂,我们想快速验证拼凑的Xpath语句是否正确时,该怎么办呢?这里给大家提供一个简单的解决方法。
下面以百度页面举例,定位"百度一下"按钮。打开浏览器中的开发者工具(F12),在Console栏中按以下格式输入,其中括号中的XPath语句即为待验证的内容。
$x('XPath...')按照上述格式,我们输入了$x('//input[@id="su"]'),结果如下图所示。输入完成后,出现了XPath语句定位的结果信息,鼠标移动到该结果信息,能够在页面中标记出对应的Web元素。
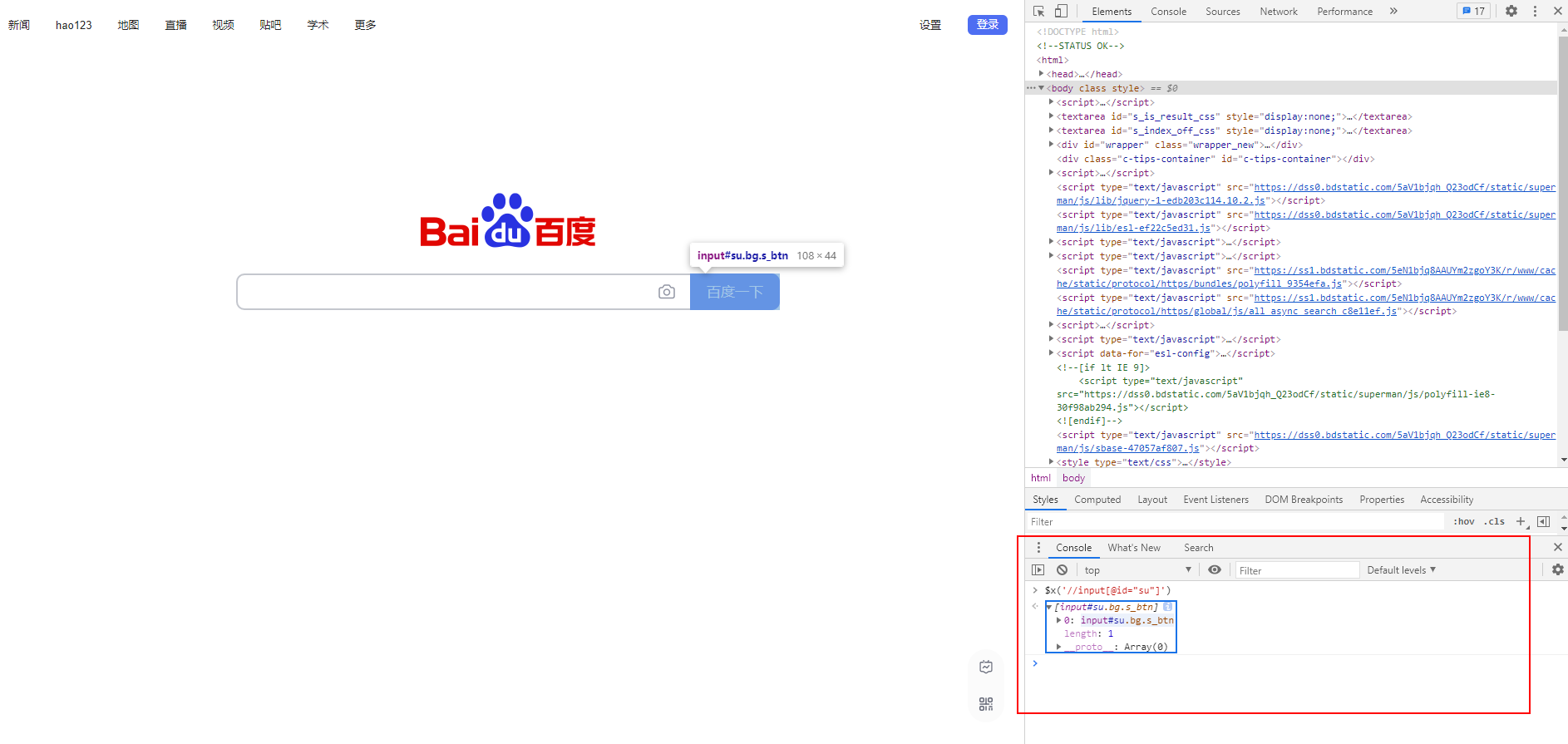
以上,实现了通过浏览器快速验证XPath语句的目标。