本文基于教材《大数据挖掘与应用》王振武,出于期末复习目的,对部分算法利用python进行实现,顺便学习numpy构建思维导图,帮助理解。
所有代码、结果都以jupyter的形式放在了github上。
题型
选择题和判断题可能从里面出,题目与答案的word版同样放入了github中。
第1章 大数据简介
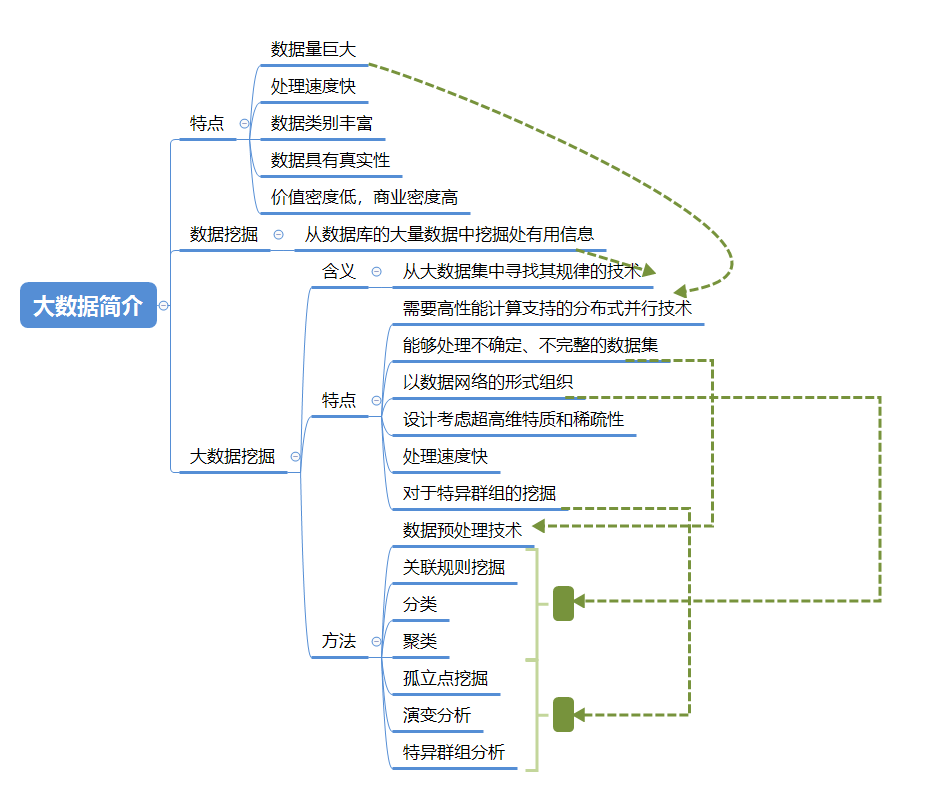
本章主要考填空题:
数据规律化
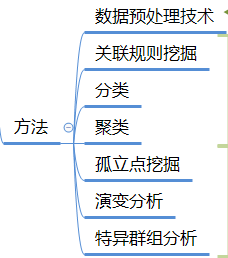
分类结果评价
混淆矩阵:运用于二分类问题
| (真实)/(预测) | 0 | 1 | 总计 |
|---|---|---|---|
| 0 | 预测0正确(TN) | 预测0错误(FP) | P(YES) |
| 1 | 预测1错误(FN) | 预测1正确(TP) | N(NO) |
| 总计 | P' | N' | P+N |
批量(评价)指标
- 批量指标
书里没有、PPT没有、上课没听=全靠谷歌
谷歌只找到AML,批量预测是指,当您想要一次性为一组观察生成预测,然后对特定百分比或特定数量的观察采取操作时,批量预测非常有用。通常情况下,您对于此类应用程序没有低延迟要求。例如,当您想要决定将哪些客户作为某个产品广告活动目标的一部分时,您可以获得所有客户的预测分数,排序模型预测来确定哪些客户最有可能购买,然后可以定位最可能购买客户的前 5%。
批量预测指标是指,用户创建批量预测后,它会提供两个指标:Records seen 和 Records failed to process。Records seen 说明 Amazon ML 在运行您的批量预测时查看多少条记录。Records failed to process 说明 Amazon ML 无法处理多少条记录。 - 评价指标
查重率(查全率)与查准率
- 查重率
一般指论文中与现有论文中的重合度,这里可能是指预测出的模型之间的相似度? - 查全率
查全率 = 召回率 = 正确识别的正样本总数 / 测试集中存在的正样本总数 = ({frac {TP} {TP+FN}}) - 查准率
查准率 = 精准率 = 正确识别的正样本总数 / 识别为正样本的个体总数 = ({frac {TP} {TP+FP}})
注意查准率与准确率的区别,准确率 = 正确识别为正+负样本的个体总数/测试集中样本总是 =({frac {TP+TN}{TP+FN+FP+TN}})
第2章 数据预处理技术
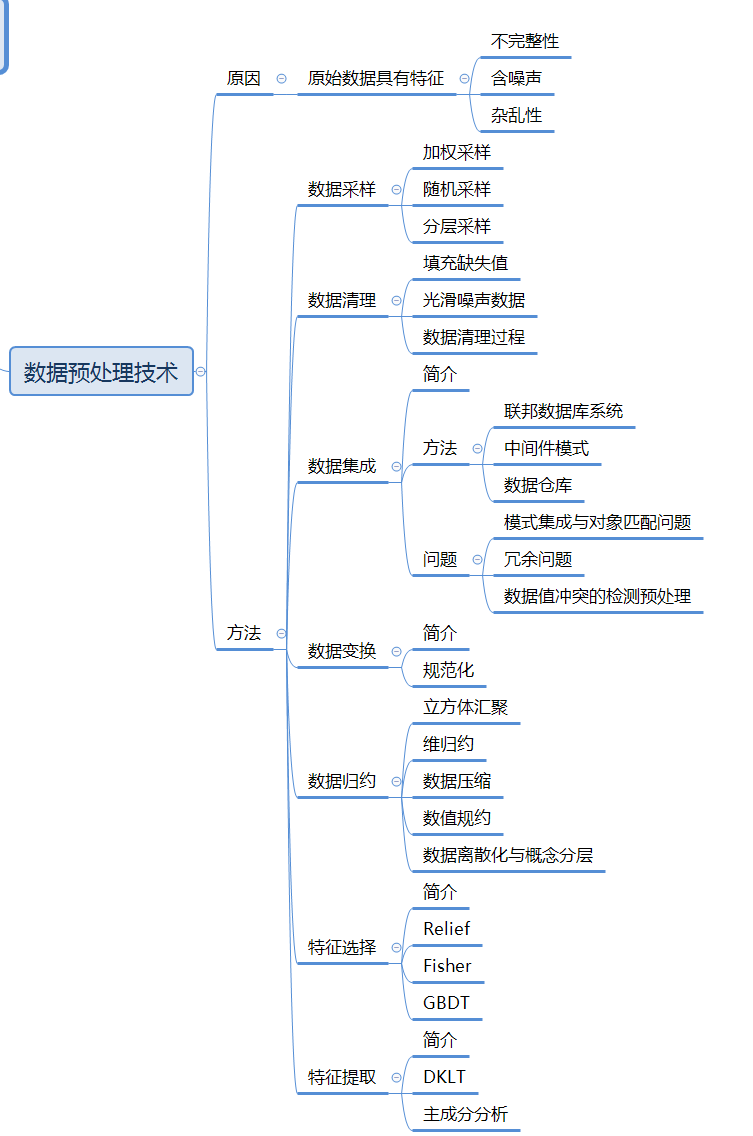
数据集成
定义:合并多个数据源中的数据,存放在一个一致的数据储存(如数据仓库)中。
数据变换
定义:将数据转换或统一成适合于挖掘的形式。
轮廓加权
修正系数=(w_{nr}=w_d * {frac N {n_r}}={frac N n}*{frac n {n_r}})
统计表:

修正后统计表:

修正后比例:

分箱
利用np.split对数组分割

平均值平滑
对每一行设为其行平均值边界平滑
对每一行设为其round(({frac {索引} {每行元素个数}}))向上取整的值
规范化
d = np.array([200,300,400,600,1000])
最小-最大规范化
令(min=0,max=1),(d.max() - d) / (d.min() - d) * (1.0 - 0.0)
z-score规范化
({frac {{原值}-{均值}} {标准差}})(d - np.average(d)) / np.std(d)
z-score规范化2
({frac {{原值}-{均值}} {平均绝对偏差}})(d - np.average(d)) / np.mean(np.absolute(d - np.mean(d)))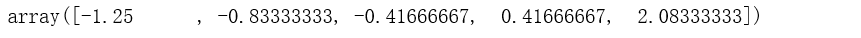
小数定标规范化
({frac {原值}{数组绝对值后的最大值对10求导向上取整再对10求幂}})
import math
d / math.pow(10, math.ceil(math.log(np.max(np.abs(d)), 10)))
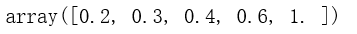
数据规约
主要考名词解释
数据压缩
数据压缩是指使用数据编码或变换以便将原始数据集合成一个较小的数据集合。
数值规约
数值规约是指选择替代的、“较小的”数据表示形式减少数据量。
特征选择与特征提取
- 区别:特征选择是指从一组数量为N的特征中选择出一组数量为M的最优特征(N>M),特征值不会被改变;特征提取则是利用已有特征参数构造一个较低维数的特征空间,将原始特征中蕴含的有用信息映射到少数几个特征上,特征值会发生改变。
- 联系:两者都是用来获取对分类识别具有重要作用的特征的方法。
第3章 关联规则挖掘
概念
- 对于关联规则挖掘,举个最简单的例子:
某超市查看销售记录后发现,购买肥宅快乐水的人有很大几率购买薯片。 - 错误理解:关联规则挖掘过程是发现满足最小支持度的所有项集代表的规则。
正确理解:关联规则挖掘过程是发现满足最小支持度的所有项集代表,再利用代表生成生成需要的关联规则,根据用户设定的最小置信度进行取舍,最后得到强关联规则。 - 对于给定频繁项集,生成关联规则
定义指出频繁项集的所有非空子集也一定是频繁项集。
例题:设(X={1,2,3})是频繁项集,则可由X产生()个关联规则- 对于频繁项集X,产生X的所有非空子集;
- 对于X的每个非空子集s,如果({frac {sup(X)} {sup(s)}} ge {minsup}),则生成关联规则$s Longrightarrow X-s $
- 对于本题,生成非空子集({1},{2},{3},{1,2},{2,3},{1,3})(不包括自身),可生成6个关联规则
({1} Longrightarrow {2, 3})
({2} Longrightarrow {1, 3})
({3} Longrightarrow {1, 2})
({1, 2} Longrightarrow {3})
({1, 3} Longrightarrow {2})
({2, 3} Longrightarrow {1})
Apriori
原理书上说的很明白了,直接通过例题理解。
例题
利用Apriori算法计算频繁项集可以有效降低计算频繁集的时间复杂度。在以下的购物篮中产生支持度不小于3的候选3-项集,在候选2-项集中需要剪枝的是()
ID 项集
1 面包、牛奶
2 面包、尿布、啤酒、鸡蛋
3 牛奶、尿布、啤酒、可乐
4 面包、牛奶、尿布、啤酒
5 面包、牛奶、尿布、可乐
A、啤酒、尿布
B、啤酒、面包
C、面包、尿布
D、啤酒、牛奶
- 导入数据:
import numpy as np
data = np.array([['面包','牛奶'],
['面包','尿布','啤酒','鸡蛋'],
['牛奶','尿布','啤酒','可乐'],
['面包','牛奶','尿布','啤酒'],
['面包','牛奶','尿布','可乐']])
min_support = 3
data
- 第一次扫描:
- 生成候选1-项集:
C1 = set()
for t in data:
for item in t:
item_set = frozenset([item])
C1.add(item_set)
C1

* 计算支持度计数:
item_count = {}
for t in data:
for item in C1:
if item.issubset(t):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
for item in item_count:
print(item,item_count[item])

* 根据支持度计数生成频繁1-项集
for item in item_count:
if(item_count[item]<min_support):
C1.remove(item)
C1
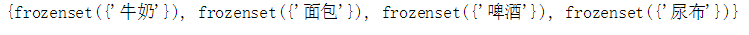
- 第二次扫描:
- 生成C1的笛卡儿积并减枝:
减枝:对于数据集L与生成的项集S,如果L-S不在L中,则认为S不是频繁项集。
- 生成C1的笛卡儿积并减枝:
Clist = list(C1)
C2 = set()
for i in range(len(Clist)):
for j in range(i+1,len(Clist)):
Ctmp = Clist[i]|Clist[j]
# 检查是否是频繁项集
check = 1
for item in Ctmp:
sub_Ck = Ctmp - frozenset([item])
if sub_Ck not in Clist:
check = 0
if check:
C2.add(Ctmp)
C2

- 根据支持度计数生成频繁2-项集
item_count = {}
for t in data:
for item in C2:
if item.issubset(t):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
for item in item_count:
print(item,item_count[item])
for item in item_count:
if(item_count[item]<min_support):
C2.remove(item)
C2

减去的是BD。
- 重复以上过程,直到不存在频繁项集。
第4章 逻辑回归
说到逻辑回归,昨天刷V2的时候才看到一个帖子工作两年的同事不知道逻辑回归是什么,这个正常吗?
由于本章不考应用题,仅罗列概念。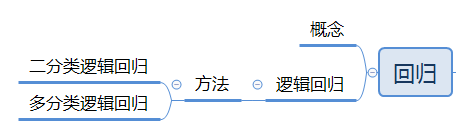
注意:分类和回归都可用于预测,分类的输出是离散的类别值,而回归的输出是连续数值。
回归
回归是指研究一组随机变量和另一组变量之间关系的统计方法,又称多重回归分析。
线性回归
线性回归是指利用称为线性回归方程的最小平方函数对一个或多个自变量与因变量之间关系进行建模的一种回归分析。
逻辑回归
- 二分类逻辑回归
逻辑回归的本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用逻辑回归函数(g(z))作为最终假设函数预测。 - 多分类逻辑回归
第5章 KNN算法
概念
KNN算法又称K-最近邻算法,根据距离函数计算待分类样本X和每个训练样本之间的距离(作为相似度),选择与待分类样本距离最小的K个样本作为X的K个最近邻,最后以X的K个最近邻中的大多数样本所属的类别作为X的类别。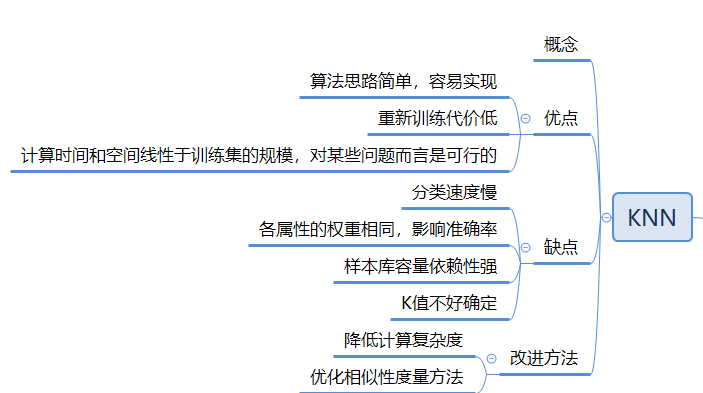
注意:
- KNN不是基于全局信息进行预测的,只基于最近邻的信息。
- KNN能够较好地避免样本的不平衡问题。
- KNN最近邻在样本较少但典型性好的情况下效果较好
例题1
有下列数据集,对于测试样本(T={18,8}),求所属类别
| 序号 | 特征1 | 特征2 | 类别 |
|---|---|---|---|
| T1 | 2 | 4 | L1 |
| T1 | 4 | 3 | L2 |
| T1 | 10 | 6 | L3 |
| T1 | 12 | 9 | L2 |
| T1 | 3 | 11 | L3 |
| T1 | 20 | 7 | L2 |
| T1 | 22 | 5 | L2 |
| T1 | 21 | 10 | L1 |
| T1 | 11 | 2 | L3 |
| T1 | 24 | 1 | L1 |
- 求欧几里得距离:
import numpy as np
data = np.array([[2,4],[4,3],[10,6],[12,9],[3,11],[20,7],[22,5],[21,10],[11,2],[24,1]])
f = np.array([1,2,3,2,3,2,2,1,3,1])
T = np.array([18,8])
np.linalg.norm(T-data,ord=2,axis=1)

- 令K=4,求最近样本
k = 4
s = np.argsort(np.linalg.norm(T-data,ord=2,axis=1))[:k]
s
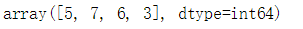
- 查看样本标签
f[s]
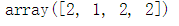
- 出现最多的标签
np.argmax(np.bincount(f[s]))
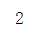
例题2
k=5,数据集如下,对(x=(1,2))分类
通过np.random()随机生成数据:
n = 40
x = np.random.rand(n, 2) * 2
y = np.random.randint(1,4,size=n)
for i in range(len(x)):
print("| $T_{"+str(i+1)+"}$ |",x[i][0],"|",x[i][1],"|",y[i],"|")
| 实例 | 横坐标 | 纵坐标 | 类别 |
|---|---|---|---|
| (T_{1}) | 1.6786053339467983 | 0.15487473902042592 | 3 |
| (T_{2}) | 1.903750045541173 | 1.6775903335564164 | 2 |
| (T_{3}) | 0.15144619402840243 | 1.543485488927614 | 1 |
| (T_{4}) | 1.7015965993474789 | 1.552612092889784 | 3 |
| (T_{5}) | 1.9723048073918905 | 1.8052157775896671 | 3 |
| (T_{6}) | 0.7477259494384572 | 1.433438461194146 | 1 |
| (T_{7}) | 1.9302135013005466 | 1.9269776190658305 | 1 |
| (T_{8}) | 0.24207606669714932 | 1.894010458348885 | 2 |
| (T_{9}) | 0.21842554513045265 | 1.9478022428563655 | 1 |
| (T_{10}) | 1.7494723363303561 | 0.7672192141953507 | 3 |
| (T_{11}) | 1.9906629300385918 | 1.0869545317058076 | 1 |
| (T_{12}) | 1.63510361868541 | 0.8617001535631279 | 3 |
| (T_{13}) | 0.6459535122987747 | 1.0827522985620026 | 2 |
| (T_{14}) | 0.3144944541356516 | 1.9091634904941777 | 1 |
| (T_{15}) | 1.5689608732625806 | 0.39157113233171503 | 2 |
| (T_{16}) | 1.8363603823958718 | 1.2276694755874005 | 2 |
| (T_{17}) | 1.4337847229694787 | 1.8034165435084824 | 1 |
| (T_{18}) | 0.45600475381462724 | 0.3148736825002354 | 1 |
| (T_{19}) | 0.42574632497710296 | 0.5997987868811052 | 2 |
| (T_{20}) | 1.1773573959790524 | 1.748304458676117 | 2 |
| (T_{21}) | 1.6423369352181407 | 0.37773395675275623 | 1 |
| (T_{22}) | 1.7097476306439856 | 1.9885829599019398 | 3 |
| (T_{23}) | 0.24618239172597223 | 0.07728932157603396 | 2 |
| (T_{24}) | 1.7603811296081917 | 1.748070452804373 | 2 |
| (T_{25}) | 0.002840121920356653 | 1.2658785281393257 | 3 |
| (T_{26}) | 1.8250450796924662 | 0.9212481743931855 | 3 |
| (T_{27}) | 0.27403996814324993 | 1.5629091001024709 | 1 |
| (T_{28}) | 0.4159278127296058 | 0.8888387282888994 | 2 |
| (T_{29}) | 1.7620478294700856 | 1.2516409761386298 | 3 |
| (T_{30}) | 0.4351390216463453 | 0.03836283116041028 | 3 |
| (T_{31}) | 1.1043330594244645 | 0.8946100006511641 | 1 |
| (T_{32}) | 1.2059961685894143 | 1.891497200080938 | 3 |
| (T_{33}) | 0.6245753790375235 | 1.6229014671236641 | 2 |
| (T_{34}) | 0.7155919663569039 | 0.7721262392930481 | 1 |
| (T_{35}) | 0.9074113329307563 | 0.12869596969464703 | 1 |
| (T_{36}) | 0.85636723383494 | 0.8891063898237037 | 1 |
| (T_{37}) | 0.375263657366401 | 0.3075941820847998 | 1 |
| (T_{38}) | 1.2824196407500417 | 0.8380355595664228 | 2 |
| (T_{39}) | 0.9577673955193708 | 1.4249046312912836 | 3 |
| (T_{40}) | 0.14893382442377834 | 1.783124207544456 | 1 |
- 分类结果:
k = 5
T = (1,2)
s = np.argsort(np.linalg.norm(T-x,ord=2,axis=1))[:k]
np.bincount(y[s])
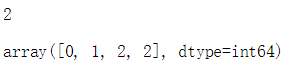
第6章 朴素贝叶斯
概念
贝叶斯方法是一种研究不确定性的推理方法,不确定性常用贝叶斯概率表示,它是一种主观概率
- 注意:
- Bayes法是一种在已知先验概率与类条件概率的情况下的模式分类方法,待分样本的分类结果取决于各类域中样本的全体。
- Bayes法不是基于规则的,而是基于概率的分类方法。
- Bayes法不能避免样本中不平衡的问题。
Bayes
朴素贝叶斯可以被认为概率统计中事件A发生的前提下B发生的概率,即(P(B|A)={frac {P(A)∗P(B|A)} {P(B)}})
| 序号 | 家庭经济状况 | 月收入 | 购买汽车 |
|---|---|---|---|
| 1 | 一般 | 优秀 | 10 |
| 2 | 好 | 优秀 | 12 |
| 3 | 一般 | 优秀 | 6 |
| 4 | 一般 | 良好 | 8.5 |
| 5 | 一般 | 良好 | 9 |
| 6 | 一般 | 优秀 | 7.5 |
| 7 | 好 | 一般 | 22 |
| 8 | 一般 | 一般 | 9.5 |
| 9 | 一般 | 良好 | 7 |
| 10 | 好 | 良好 | 12.5 |
- 导入数据
import numpy as np
data = np.array([['一般', '优秀', 10, 1],
['好', '优秀', 12, '1'],
['一般', '优秀', 6, '1'],
['一般', '良好', 8.5, '0'],
['一般', '良好', 9, '0'],
['一般', '优秀', 7.5, '1'],
['好', '一般', 22, '1'],
['一般', '一般', 9.5, '0'],
['一般', '良好', 7, '1'],
['好', '良好', 12.5, '1']])
data
- 计算先演概率
p_1 = np.sum(data=='1')/len(data)
p_0 = np.sum(data=='0')/len(data)
p_1,p_0
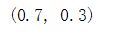
- 计算条件概率
X = np.array(['一般','优秀','12'])
p_1_s = 1
p_0_s = 1
data_1 = data[data[:,3]=='1'] # 购买汽车的训练数据
data_0 = data[data[:,3]=='0'] # 不买汽车的训练数据
for i,x in enumerate(X):
print(x, np.sum(data_1==x),np.sum(data_0==x))
p_1_s *= np.sum(data_1==x)/len(data)
p_0_s *= np.sum(data_0==x)/len(data)
p_1_s*p_1,p_0_s*p_0
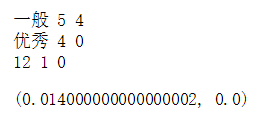
认为该测试样本的预测结果为1。
第7章 随机森林算法
7酱昨天没上场
概念
随机森林方法是一种统计学习理论,它利用bootstrap重抽样方法从原始样本中抽取多个样本,对每个bootstrap样本进行决策树建模,然后组合多棵决策树的预测,通过投票得出最终预测结果。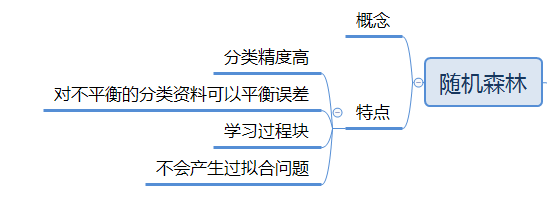
考完补足随机森林算法可视化例子
第8章 支持向量机(SVM)
看到名字就想到AC自动机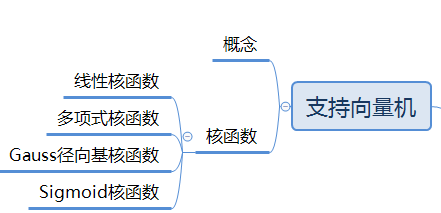
概念
支持向量机根据有限的样本信息在模型的复杂性和学习能力间寻求最佳折中,以期获得最好的推广能力。
wiki上的解释比书上好懂多了。
- svm不能避免样本之间的不平衡问题
- 对于SVM分类算法,待分样本集中的大部分样本不是支持向量,移去或者减少这些样本对分类结果没有影响。(因为这些向量距离最大间隔超平面较远)
- SVM是这样一个分类器,他寻找具有最大边缘的超平面,因此它也经常被称为最小边缘分类器3
- logistic核函数不是SVM的核函数
- 样本->支持向量
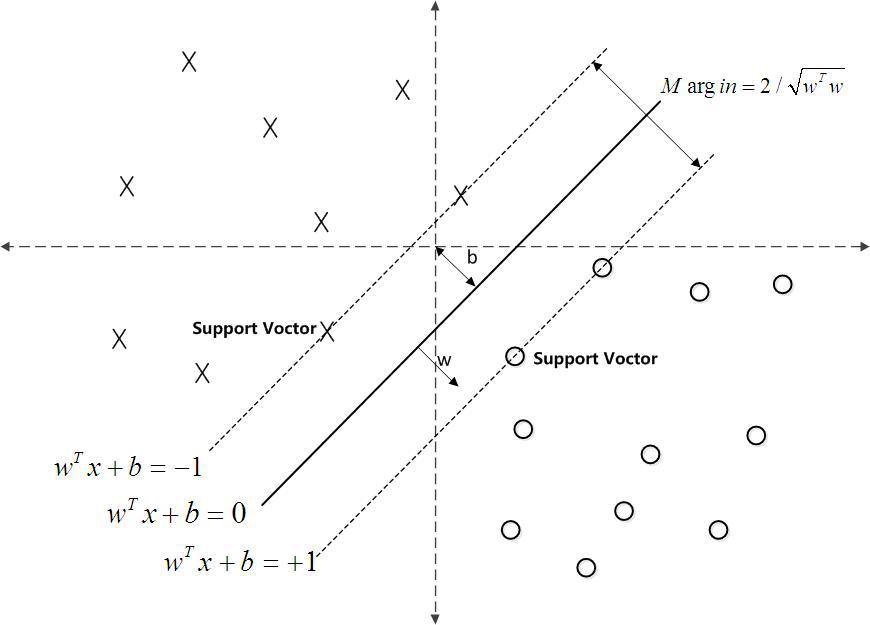
对于n点测试集((overrightarrow{x_1},y_1),dotso,(overrightarrow{x_n},y_n)),其中(y_i)的取值是1或-1,为了把(y_i= 1)与(y_i= -1)的点分开,找到一条函数为(overrightarrow x * overrightarrow w +b=0)的线,由它生成的超平面满足所有的点离该超平面足够远。
如果这些训练数据是线性可分的,可以选择分离两类数据的两个平行超平面,使得它们之间的距离尽可能大。在这两个超平面之间的区域被称为“间隔”,最大间隔超平面是位于它们正中间的超平面。
这些超平面可以由方程族:({ {vec {w}}cdot {vec {x}}-b=1\,})({ {vec {w}}cdot {vec {x}}-b=-1\,})表示。
这超平面之间的距离是 ({ { frac {2}{|{vec {w}}|}}}),要使间隔最大,({ |{vec {w}}|})应当尽可能的小。同时为了使得样本数据都在超平面的间隔区之外,对于所有的 ({ i}) 应满足:
({ {vec {w}}cdot {vec {x}}_{i}-bgeq 1,}) 若 ({ y_{i}=1}),
或({ {vec {w}}cdot {vec {x}}_{i}-bleq -1,}) 若 ({ y_{i}=-1.})
这些约束约束条件表明每个数据点都必须位于间隔的正确一侧。
这两个式子也可以写作:({ y_{i}({vec {w}}cdot {vec {x}}_{i}-b)geq 1,quad { ext{ for all }}1leq ileq n.qquad qquad (1)})
也就是说,当({ y_{i}({vec {w}}cdot {vec {x_{i}}}-b)geq 1})时,最小化 ({ |{vec {w}}|}),对于 ({ i=1,\,ldots ,\,n})
该方程的解 (vec w) 与 (b) 决定了分类器 ({ {vec {x}}mapsto operatorname {sgn}({vec {w}}cdot {vec {x}}-b)})。
由此可见,最大间隔超平面是由最靠近它的 ({ {vec {x}}_{i}})确定的。这些 ({ {vec {x}}_{i}})叫做支持向量。
第9章 人工神经网络算法(BP)
概念
人工神经网络是一种模仿生物神经网络的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。这里仅对反向传播算法(BP)进行说明
算法分为两个阶段
- 第一阶段输入信息从输入层经隐含层计算各单元的输出值。
- 第二阶段输出误差逐层向前算出各隐含各单元的误差,并由此误差修正权值。
- 输入层-隐含层-输出层公式:
输入层(O_i=x_i,i=0,1,2,...,I-1),
隐含层({net}_j={sum_{i=0}^{I}{v_{ij}O_i}})
相比WIKI,知乎上讲的比较好。
例9.2
| (x_1) | (x_2) | (x_31) | (x_{14}) | (x_{15}) | (x_{24}) | (x_{25}) | (x_{34}) | (x_{35}) | (x_{46}) | (x_{56}) | ( heta_4) | ( heta_5) | ( heta_6) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 0.2 | -0.3 | 0.4 | 0.1 | -0.5 | 0.2 | -0.3 | -0.2 | -0.4 | 0.2 | 0.1 |
- 计算各隐含层以及输出层的输入、输出值
公式- 输入层:(O_i=x_o,(i=0,1,2,...,I-1))
- 隐含层:
输入为(x_j = net_j=sum_{i=0}^I{v_{ij}*O_i}+ heta_j),
输出为(O_j=f(net_j))
取单极Sigmoid函数作为f
则输出为(O_j=f(net_j)=frac{1}{1+e^{-net_j}}) - 输出层与隐含层同理。
对本题进行解析:
| 结点 | 网格输入值 | 输出值 |
|---|---|---|
| 4 | (x_1*x_{14}+x_2*x_{24}+x_3*x_{34}+ heta_4=1*0.2+0*0.4+1*-0.5-0.4=-0.7) | $frac {1} {1+e^{0.7}}=0.332 $ |
| 5 | (x_1*x_{15}+x_2*x_{25}+x_3*x_{35}+ heta_5=1*-0.3+0*0.1+1*0.2+0.2=0.1) | $frac {1} {1+e^{-0.1}}=0.1 $ |
| 6 | (o_4*x_{46}+o_5*x_{56}+ heta_6=-0.3*0.332+-0.2*0.525+0.1=-0.105) | (frac {1} {1+e^{0.105}}) |
- 反推各层修正系数
首先对(f(net_j)=frac{1}{1+e^{-net_j}})(求导)[https://zs.symbolab.com/solver/derivative-calculator/frac{d}{dx}left(frac{1}{1%2Be^{-x}} ight)?or=sug]
化简后(=frac{1}{1+e^{-net_j}}*frac{e^{-net_j}}{1+e^{-net_j}}=frac{1}{1+e^{-net_j}}*(1-frac{1}{1+e^{-net_j}})=f(net_j)*(1-f(net_j)))
计算误差对权重 {displaystyle w_{ij}} w_{{ij}} 的偏导数是两次使用链式法则得到的:
({frac {partial E}{partial w_{{ij}}}}={frac {partial E}{partial o_{j}}}{frac {partial o_{j}}{partial {mathrm {net_{j}}}}}{frac {partial {mathrm {net_{j}}}}{partial w_{{ij}}}})
在右边的最后一项中,只有加权和({displaystyle mathrm {net_{j}} })取决于${displaystyle w_{ij}} (,因此 ){displaystyle {frac {partial mathrm {net_{j}} }{partial w_{ij}}}={frac {partial }{partial w_{ij}}}left(sum {k=1}^{n}w{kj}o_{k} ight)=o_{i}}$.
神经元 ({displaystyle j})的输出对其输入的导数就是激活函数的偏导数
({frac {partial o_{j}}{partial {mathrm {net_{j}}}}}={frac {partial }{partial {mathrm {net_{j}}}}}varphi ({mathrm {net_{j}}})=varphi ({mathrm {net_{j}}})(1-varphi ({mathrm {net_{j}}})))
误差函数:(delta=f'(net_j)sum_{k=0}^{K-1}delta_k*w_{jk})
输出层:(varDelta w_{jk}=eta O_j(d_k-O_k)f'(net_j)=eta O_j(d_k-O_k)*O_k(1-O_k))
隐含层:(varDelta v_{jk}=eta *f'(net_j)sum_{k=0}^{K-1}delta_kw_{jk}*O_i)
| 结点 | 系数修正 | 权系数变化值 |
|---|---|---|
| 6 | (eta=f'(net_6)*E=O_6*(1-O_6)*(1-O_6)) | 0.1311 |
| 5 | (varDelta 5=eta f'(net_5)*x_{56}=eta O_5*(1-O_5)*{w_56}) | -0.0065 |
| 4 | (varDelta 4=eta f'(net_4)*x_{46}=eta O_4*(1-O_4)*{w_46}) | -0.0087 |
- 新系数
举例:(w_{46}=x_{46}+0.9*eta*O_4)
( heta_4 = heta_4+0.9*varDelta 4)
习题
输入样本(x_1=1,x_2=0) 输出结点的期望输出为1,对于第k次学习得到的权值为(w_{11}(k)=0,w_{12}(k)=2,w_{21}(k)=1,w_{22}=1,T_1(k)=1,T_2(k)=1),求(z(k),z(k+1))
求正向传导
隐含层:(net_i = sum_{(j=1)}^k w_{ji} x_j+θ_i)
输出层:(net_z = ∑_{(j=1)}^2 w_{jz} y_j^1+θ_z)
(y_1(k)=x_1*w_{11}(k)+x_2*w_{21}(k)=1*0+0*2=0<1 f(net_1)=1)
(y_2(k)=x_1*w_{12}(k)+x_2*w_{22}(k)=1*2+0*2=2>=1 f(net_2)=2)
(z(k)=T_1(k)*f(net_1)+T_2(k)*f(net_2)=1*1+2*1=3)反向求修正系数
输出层:(δ_z^k=y_z^k (d_z^1-y_z^k)(1-y_z^k))
隐含层:(δ_i^k=δ_z^k w_iz (k)y_i^k (1-y_i^k))
(delta_{k} = riangle z(k) = f'(net_3)*(E-z(k))=(1-3)*3*(1-3)=2*3*2=12)
(varDelta y_1 = fprime(net_1) *delta_{k} * net_1 = 1*(1-1)*12*1 =0)
(varDelta y_2 = fprime(net_2) *delta_{k} * net_2 = 2*(1-2)*12*2 =-24)通过修正系数求修正值
(w_{iz}(k+1)=w_{iz} (k)+ηδ_z^k y_i^k)
(T_1(k+1) = T_1(k) + delta_{k} * eta * f(net_1)_k =1+12*1*1 = 13)
(T_2(k+1) = T_2(k) + delta_{k} * eta * f(net_2)_k=1+12*1*2 = 25)
(w_{11}(k+1) = w_{11}(k) +varDelta y_1*eta*x_{1} =0 + 12*1*0 = 0)
(w_{12}(k+1) = w_{12}(k) +varDelta y_2*eta*x_{1} =2 -24*1*1 = -22)
(w_{21}(k+1) = w_{21}(k) +varDelta y_1*eta*x_{2} =2 + 12*1*0 = 2)
(w_{22}(k+1) = w_{22}(k) +varDelta y_2*eta*x_{2} =1 -24*1*0 = 1)求第k+1次的正向传导输出值
(y_1(k+1)=x_1*w_{11}(k+1)+x_2*w_{21}(k+1)=1*0+0*2=0<1 f(net_1)=1)
(y_2(k+1)=x_1*w_{12}(k+1)+x_2*w_{22}(k+1)=1*(-22)+0*2=-22<=1 f(net_2)=1)
(z(k+1)=T_1(k+1)*f(net_1)+T_2(k+1)*f(net_2)=1*13+1*25=38)
第10章 决策树分类算法
概念
从数据中生成分类器的一个特别有效的方法是生成一棵决策树。决策树表示方法是应用最广泛的逻辑方法之一,它从一组无次序、无规则的事例中推理出决策树表示形式的分类准则。
ID3
- 随机生成数据:
import numpy as np
import random
outlook = [
'sunny',
'overcast',
'rainy'
]
temperature = [
'hot',
'mild',
'cool'
]
humidity = [
'high',
'normal',
]
windy = [
'false',
'true'
]
play = [
'no',
'Yes'
]
data = []
for i in range(20):
data.append([outlook[random.randint(0,len(outlook)-1)],
temperature[random.randint(0,len(temperature)-1)],
humidity[random.randint(0,len(humidity)-1)],
windy[random.randint(0,len(windy)-1)],
play[random.randint(0,len(play)-1)]])
data = np.array(data)
data
| 编号 | outlook | temperature | humidity | windy | play |
|---|---|---|---|---|---|
| 1 | rainy | mild | high | true | Yes |
| 2 | overcast | hot | normal | false | no |
| 3 | sunny | hot | normal | true | no |
| 4 | sunny | cool | normal | false | no |
| 5 | rainy | hot | high | false | no |
| 6 | sunny | mild | high | true | no |
| 7 | overcast | mild | high | true | Yes |
| 8 | rainy | cool | normal | false | Yes |
| 9 | sunny | cool | normal | true | no |
| 10 | sunny | mild | high | true | Yes |
| 11 | overcast | cool | high | false | Yes |
| 12 | rainy | cool | high | false | Yes |
| 13 | sunny | mild | high | false | Yes |
| 14 | overcast | cool | normal | true | Yes |
| 15 | rainy | hot | normal | false | Yes |
| 16 | overcast | mild | normal | false | Yes |
| 17 | sunny | hot | normal | false | Yes |
| 18 | sunny | cool | normal | true | no |
| 19 | rainy | mild | normal | false | no |
| 20 | rainy | cool | normal | true | no |
- 首先算出初始熵值(entropy(S)=-sum_{i=0}^{n}{p_i log_2 p_i})
import math
def entropy(a,b):
return 0.0-a/(a+b)*math.log(a/(a+b),2)-b/(a+b)*math.log(b/(a+b),2)
entropy(np.sum(data=='Yes'),np.sum(data=='no'))
(entropy(S)=-sum_{i=0}^{n}{p_i log_2 p_i}=0.9927744539878084)
- 计算outlook的熵
ans = 0
for o in outlook:
pos = np.sum(np.where(data[np.where(data=='Yes')[0]]==o))
neg = np.sum(np.where(data[np.where(data=='no')[0]]==o))
print('| $entropy(S_{'+o+'})$ | $-\frac {'+
str(pos)+"} {"+str(neg+pos)+"} \log_2\frac {"+
str(pos)+"} {"+str(neg+pos)+"} -\frac {"+
str(neg)+"} {"+str(neg+pos)+"} \log_2\frac {"+
str(neg)+"} {"+str(neg+pos)+"} $ | "
,str(entropy(pos,neg))," |"
)
ans = ans + len(np.where(data == o)[0])/ len(data) *entropy(pos,neg)
ans
| 期望信息 | 公式 | 结果 |
|---|---|---|
| (entropy(S_{sunny})) | $-frac {3} {8} log_2frac {3} {8} -frac {5} {8} log_2frac {5} {8} $ | 0.9544340029249649 |
| (entropy(S_{overcast})) | $-frac {4} {5} log_2frac {4} {5} -frac {1} {5} log_2frac {1} {5} $ | 0.7219280948873623 |
| (entropy(S_{rainy})) | $-frac {4} {7} log_2frac {4} {7} -frac {3} {7} log_2frac {3} {7} $ | 0.9852281360342516 |
(gain(S,outlook)=0.08568898148399373)
同理可得,(gain(S,temperature)=0.0008495469303535508),(gain(S,humidity)=0.3658730455992085),(gain(S,windy)=0.3654369784855406)
属性humidity的信息增量更大,选取humidity作为根结点的测试属性。
- 利用sklearn来生成决策树:
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion="entropy",class_weight="balanced",min_samples_split=2)
from sklearn import preprocessing
feature = ['outlook','temperature','humdity','windy']
le = preprocessing.LabelEncoder()
data_sk = data.copy()
for i in range(5):
data_sk[:,i] = le.fit_transform(data_sk[:,i])
clf = clf.fit(data_sk[:,:4],data_sk[:,4])
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None,feature_names=feature,class_names=np.array(['Yes','no']),filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph
sklearn运用的是cart算法,只能生成二叉树: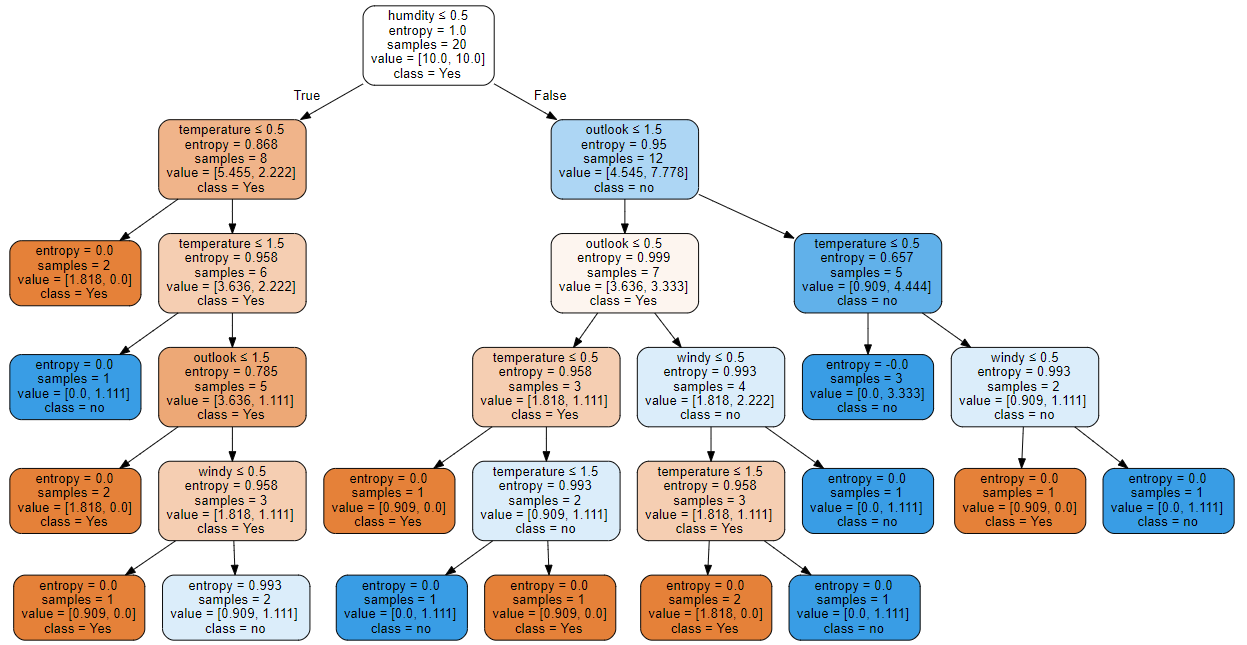
- 用ID3-python来生成多叉树:
from sklearn.datasets import load_breast_cancer
from id3 import Id3Estimator
from id3 import export_graphviz
bunch = load_breast_cancer()
estimator = Id3Estimator()
data = []
for i in range(20):
data.append([outlook[random.randint(0,len(outlook)-1)],
temperature[random.randint(0,len(temperature)-1)],
humidity[random.randint(0,len(humidity)-1)],
windy[random.randint(0,len(windy)-1)],
play[random.randint(0,len(play)-1)]])
data = np.array(data)
estimator.fit(data[:,:4],data[:,4], check_input=True)
export_graphviz(estimator.tree_, 'tree.dot', feature)
from subprocess import check_call
check_call(['dot', '-Tpng', 'tree.dot', '-o', 'tree.png'])
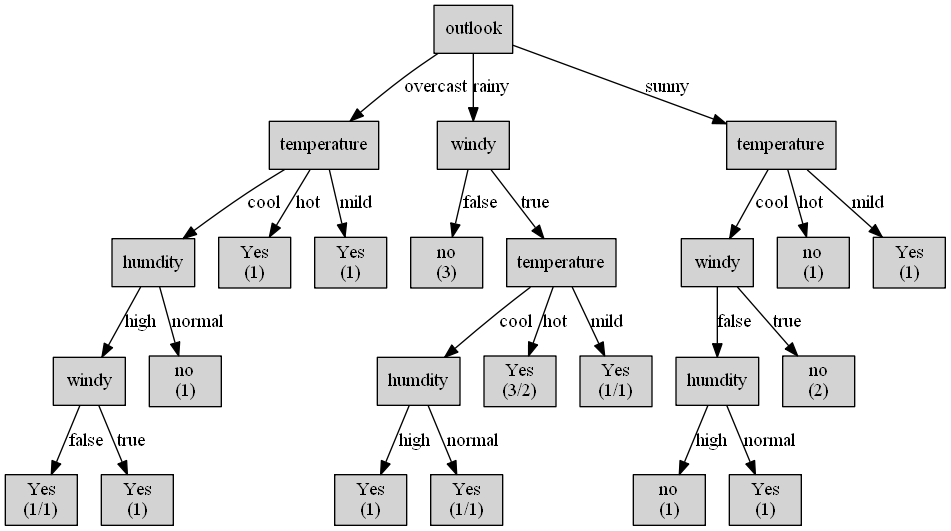
C4.5
C4.5是ID3的一种改进算法,用信息增益比代替了信息增熵进行分支。
- 对outlook属性求信息增益比
ans = 0
for o in outlook:
pos = np.sum(np.where(data[np.where(data=='Yes')[0]]==o))
neg = np.sum(np.where(data[np.where(data=='no')[0]]==o))
ans = ans + len(np.where(data == o)[0])/ len(data) *entropy(pos,neg)
ans2 = 0
def entropy2(a,b):
return 0.0-a/b*math.log(a/b,2)
for o in outlook:
ans2 = ans + entropy2(len(np.where(data==o)[0]),len(data))
ans/ans2
| 期望信息 | 公式 | 结果 |
|---|---|---|
| (entropy(S_{sunny})) | $-frac {3} {8} log_2frac {3} {8} -frac {5} {8} log_2frac {5} {8} $ | 0.9544340029249649 |
| (entropy(S_{overcast})) | $-frac {4} {5} log_2frac {4} {5} -frac {1} {5} log_2frac {1} {5} $ | 0.7219280948873623 |
| (entropy(S_{rainy})) | $-frac {4} {7} log_2frac {4} {7} -frac {3} {7} log_2frac {3} {7} $ | 0.9852281360342516 |
$entropy(overlook)= 0.9070854725038147 ( )gain(overlook) =entropy(play)-entropy(overlook)= 0.08568898148399373 ( )splitInfo(overlook)=-frac{8} {20}log_2(frac{8} {20})-frac{5} {20}log_2(frac{5} {20})-frac{7} {20}*log_2(frac{7} {20})(=1.4371860829942302 )gainratio(overlook)=frac {gain(overlook)}{splitInfo(overlook)}= 0.6311538103778426 ( )gainratio(windy)=frac {gain(windy)}{splitInfo(windy)}= 0.6457015657437329 ( )gainratio(humidity)=frac {gain(humidity)}{splitInfo(humidity)}= 0.6325210109574498 ( )gainratio(temperature)=frac {gain(temperature)}{splitInfo(temperature)}=0.6405928106112709 $
显然windy最大,根据windy构建决策树。
第11章 K均值算法(k-means)
概念
k-means把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。
与KNN区别
| k-means | KNN |
|---|---|
| 聚类问题 | 分类问题 |
| 训练集无特征 | 训练集有特征 |
| 具有先验过程 | 没有先验过程 |
应用
以作业第三题为例:
分别取k=2和3,利用K-means聚类算法对以下的点聚类,(2, 1), (1, 2), (2, 2), (3, 2), (2, 3), (3, 3), (2, 4), (3, 5), (4, 4), (5, 3),并讨论k值以及初始聚类中心对聚类结果的影响。
- 当k=2时:
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[2, 1], [1, 2], [2, 2], [3, 2], [2, 3], [3, 3], [2, 4], [3, 5], [4, 4], [5, 3]])
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
print(X)
使用题中数据,画出散点图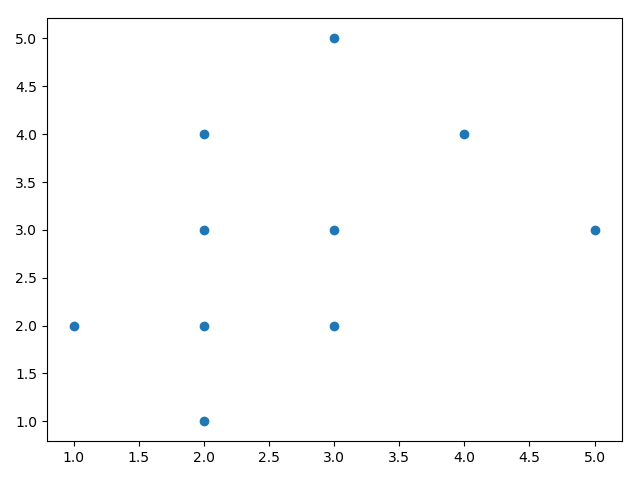
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[2, 1], [1, 2], [2, 2], [3, 2], [2, 3], [3, 3], [2, 4], [3, 5], [4, 4], [5, 3]])
from sklearn.cluster import KMeans
x_init = np.array([[2, 1], [1, 2]]) # 将前2个点设为初始聚类中心,迭代次数为1次
y_pred = KMeans(n_clusters=2, max_iter=1, init=x_init).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
第一次迭代结果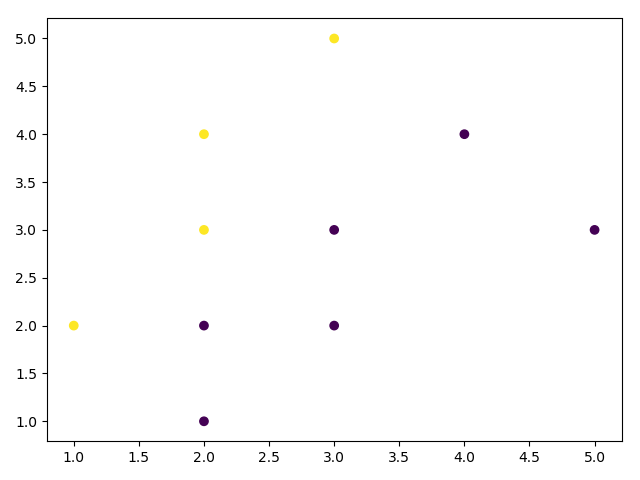
使用第一次迭代结果的质心作为聚类中心
x_init = np.array([[3.16, 2.5], [2, 3.5]]) # 将第一次分类结果的质心设为初始聚类中心,迭代次数为1次
y_pred = KMeans(n_clusters=2, max_iter=1, init=x_init).fit_predict(X)
print(y_pred)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
结果与第一次一样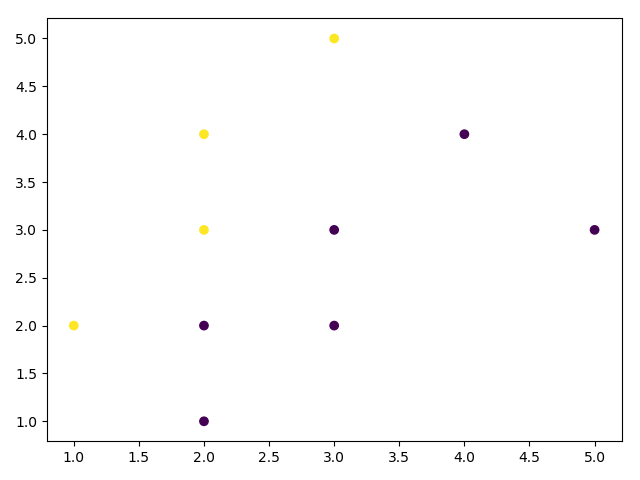
计算矩阵:
import math
m1_x = 0.0
m1_y = 0.0
m2_x = 0.0
m2_y = 0.0
for i, y in enumerate(y_pred):
if not y:
m1_x += X[i][0]
m1_y += X[i][1]
else:
m2_x += X[i][0]
m2_y += X[i][1]
m1_x = m1_x / y_pred[y_pred == 0].size
m1_y = m1_y / y_pred[y_pred == 0].size
m2_x = m2_x / y_pred[y_pred == 1].size
m2_y = m2_y / y_pred[y_pred == 1].size
print("M1':" , m1_x, m1_y, "M2':" , m2_x, m2_y)
for i, x in enumerate(X):
print(math.sqrt(math.pow(x[0] - m1_x, 2) + math.pow(x[1] - m1_y, 2)),
math.sqrt(math.pow(x[0] - m2_x, 2) + math.pow(x[1] - m2_y, 2)))
结果: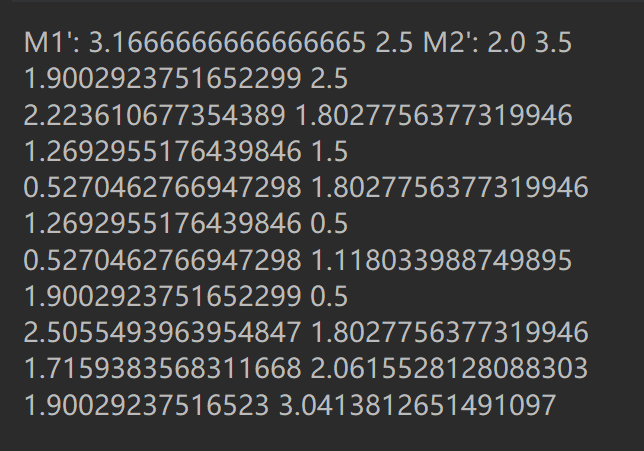
- 当k=3时:
- 第一次迭代结果:
# 当k=3时
x_init = np.array([[2, 1], [1, 2], [2, 2]]) # 将前3个点设为初始聚类中心,迭代次数为1次
y_pred = KMeans(n_clusters=3, max_iter=1, init=x_init).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
print(y_pred)
m1 = np.mean(X[np.where(y_pred == 0)], axis=0) # axis==0 计算每一列均值
m2 = np.mean(X[np.where(y_pred == 1)], axis=0)
m3 = np.mean(X[np.where(y_pred == 2)], axis=0)
print("M1':", m1, "M2':", m2, "M3':", m3)
结果: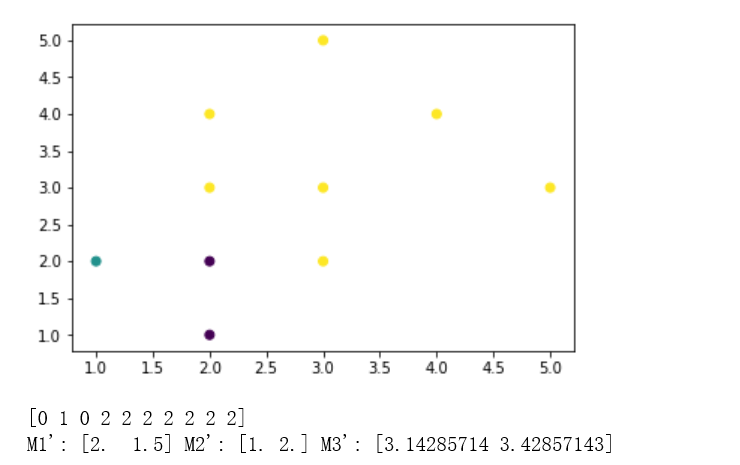
- 第二次迭代结果:
y_pred = KMeans(n_clusters=3, max_iter=2, init=x_init).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
m1 = np.mean(X[np.where(y_pred == 0)], axis=0) # axis==0 计算每一列均值
m2 = np.mean(X[np.where(y_pred == 1)], axis=0)
m3 = np.mean(X[np.where(y_pred == 2)], axis=0)
print("M1':", m1, "M2':", m2, "M3':", m3)
结果: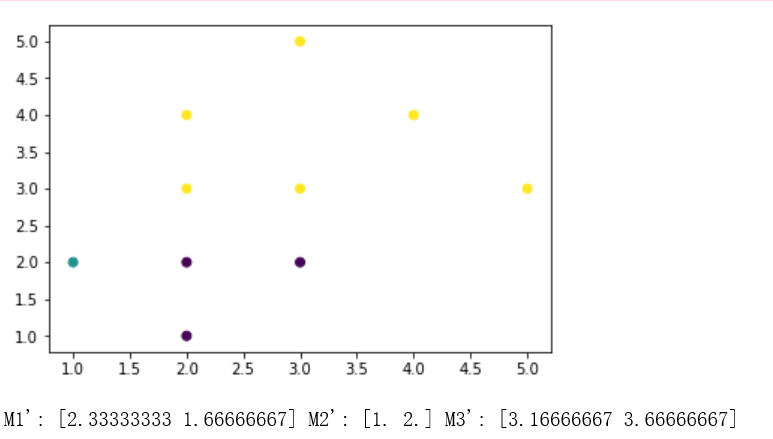
- 第三次迭代结果:
y_pred = KMeans(n_clusters=3, max_iter=3, init=x_init).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
m1 = np.mean(X[np.where(y_pred == 0)], axis=0) # axis==0 计算每一列均值
m2 = np.mean(X[np.where(y_pred == 1)], axis=0)
m3 = np.mean(X[np.where(y_pred == 2)], axis=0)
print("M1':", m1, "M2':", m2, "M3':", m3)
与第二次一样: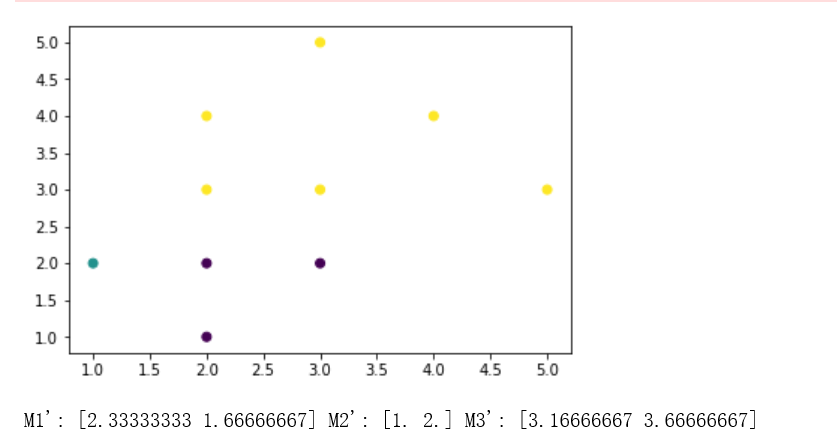
影响
k值的影响
在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。K值过小,类内相似性变小,聚类结果将无法满足应用需要;K值过大,类间间距变小,意味着应用中将会增加成本。这也是 K-means 算法的一个不足。
初始聚类中心选择的影响
初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,甚至如果选到噪声数据和孤立点,将使算法的迭代次数增多,算法的时间性能变差,另外,受噪声数据和孤立点的影响算法还容易陷入局部极值。如果这也成为 K-means算法的一个主要问题。
第12章 k中心点聚类算法(K-medoids)
除了中心点选取算法与k-means不一致外,其他算法过程一致。
- 区别:
- K-means里每个聚类的中心点是平均值点
- K-medoids里每个聚类的中心点是离平均值点最近的样本点
应用
【例12.1】,当初始中心点为{D,E}时,试运用K-中心点聚类算法给出第一次迭代后生成的两个簇。
sklearn中似乎没有该算法,不过wiki中讲的很详细。
- 第一步建立过程:
% matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[0, 1, 2, 2, 3],
[1, 0, 2, 4, 3],
[2, 2, 0, 1, 5],
[2, 4, 1, 0, 3],
[3, 3, 5, 3, 0]])
k = [3, 4]
y = []
for i, x in enumerate(X):
if x[k[0]] <= x[k[1]]:
print(x[k[0]], x[k[1]], "0")
y.append(0)
else:
print(x[k[0]], x[k[1]], "1")
y.append(1)
y = np.array(y)
print("COST:", np.sum(X[np.where(y == 0)], axis=0)[k[0]], np.sum(X[np.where(y == 1)], axis=0)[k[1]])
结果:
- 第二步交换过程:
- 将D替换为A
k = [0, 4]
y = []
for i, x in enumerate(X):
if x[k[0]] <= x[k[1]]:
print(x[k[0]], x[k[1]], "0")
y.append(0)
else:
print(x[k[0]], x[k[1]], "1")
y.append(1)
y = np.array(y)
print("COST:", np.sum(X[np.where(y == 0)], axis=0)[k[0]], np.sum(X[np.where(y == 1)], axis=0)[k[1]])
ans_da = np.sum(X[np.where(y == 0)], axis=0)[k[0]] + np.sum(X[np.where(y == 1)], axis=0)[k[1]]
print(ans_da - ans)
结果:
- 替换k中的值,得出不同结果,选择第一个代价最小的结果,即用A替换D。
第13章 自组织神经网络聚类算法(SOM)
概念
一个神经网络接受外界输入模式时,将会分为不同的对应区域,各区域对输入模式具有不同的响应特征,而且这个过程是自动完成的。SOM通过自动寻找样本中的内在规律和本质属性,自组织、自适应地改变网络参数与结构。
- SOM是一种属于基于原型的聚类算法。
第14章 基于密度的空间的数据聚类方法(DBSCAN)
概念
DBSCAN是一个基于高密度连接区域地密度聚类算法,该算法将簇定义为密度相连的点的最大集,将具有高密度的区域划分为簇。
- DBSCAN是相对抗噪声的,丢弃被它识别为噪声的对象,并且能够处理任意形状和大小的簇。
- DBSCAN使用基于密度的概念,会合并有重叠的簇。
- DBSCAN在最坏情况下的时间复杂度是(O(m^2))
与K-means比较
| k-means | DBSCAN | |
|---|---|---|
| 划分聚类 | 聚类所有对象 | 丢弃被它识别为噪声的对象 |
| 基准 | 原型 | 密度 |
| 处理数据 | 难处理非球形的簇和不同大小的簇 | 可以处理不同大小或形状的簇 |
| 处理数据 | 只能用于具有明确定义的质心(比如均值或中位数)的数据 | 要求密度定义(基于传统的欧几里得密度概念) |
| 处理数据 | 可以用于稀疏的高维数据,如文档数据 | 对于高维数据,传统的欧几里得密度定义不能很好处理它们 |
| 架设 | 假定所有的簇都来自球形高斯分布,具有不同的均值,但具有相同的协方差矩阵 | 不对数据的分布做任何假定 |
| 合并 | 可以发现不是明显分离的簇,即便簇有重叠也可以发现 | 合并有重叠的簇 |
| 时间复杂度 | (O(m)) | (O(m^2)) |
| 多次运行 | 使用随机初始化质心,不会产生相同的结果 | 会产生相同结果 |
| K值 | 簇个数需要作为参数指定 | 自动地确定簇个数 |
| 模型 | 优化问题,即最小化每个点到最近质心的误差平方和 | 不基于任何形式化模型 |