背景介绍:
Atlassian的东西相信大家都不陌生,JIRA、Confluence……虽然说这些产品都要收费,也可以申请试用;
FishEye 可以方便地查看代码,而Crucible 则是进行CodeReview的利器。因为同属Atlassian,它们又可以与JIRA进行整合,比较方便。
测试环境:

操作步骤:
1. 下载fisheye压缩包
官网下载地址:https://www.atlassian.com/software/fisheye/download

2. 解压
[root@fisheye opt]# unzip fisheye-4.1.2.zip //此处,该zip压缩包放在/opt目录下

3. 破解安装
[root@fisheye opt]# cd fecru-4.1.2/lib/ //进入该lib目录
将其中的“atlassian-extras-2.5.jar”复制出来,等待破解,然后删除/lib/目录中的原文件;
[root@fisheye lib]# ls |grep atlassian-extras-2.5.jar //查看下确认有这个文件

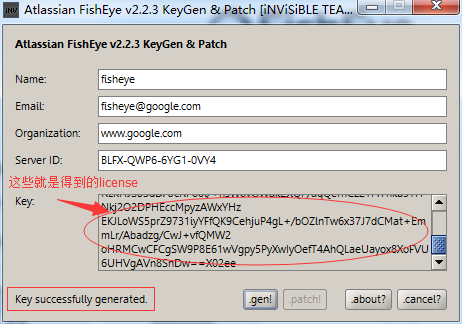
将取出来的atlassian-extras-2.5.jar改名为atlassian-extras-2.3.1-SNAPSHOT.jar //因为用到的破解工具只能识别这个名字
运行破解fisheye工具:fisheye_keygen.jar //windows环境运行先装java,跳出对话框如下
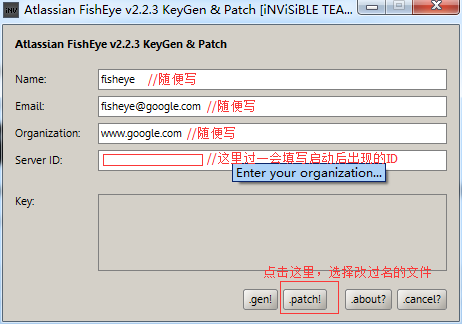
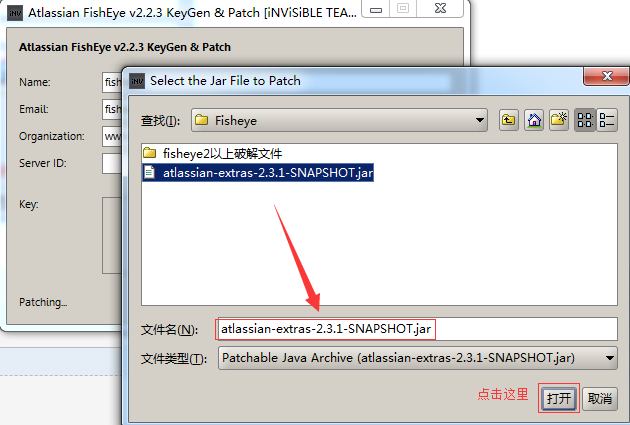
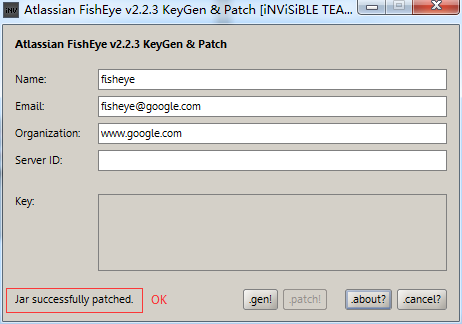
破解完成,将文件atlassian-extras-2.3.1-SNAPSHOT.jar改回原来的名字(atlassian-extras-2.5.jar),传回.../lib/目录中;
4. 启动fisheye
切换到bin目录


查看到启动和停止的两个可执行shell脚本,先启动:
[root@fisheye bin]# ./start.sh


5. 进入网页安装向导
浏览器访问 http://138.138.80.108:8060
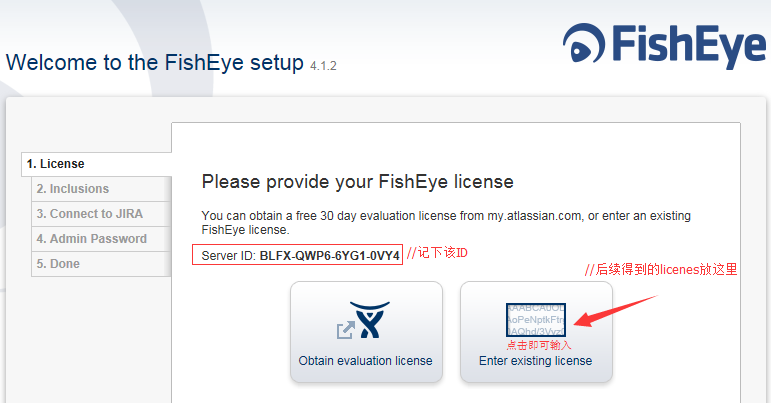
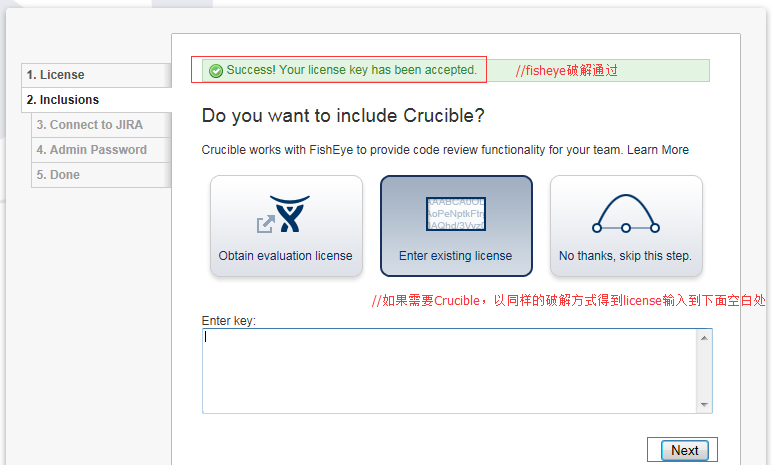
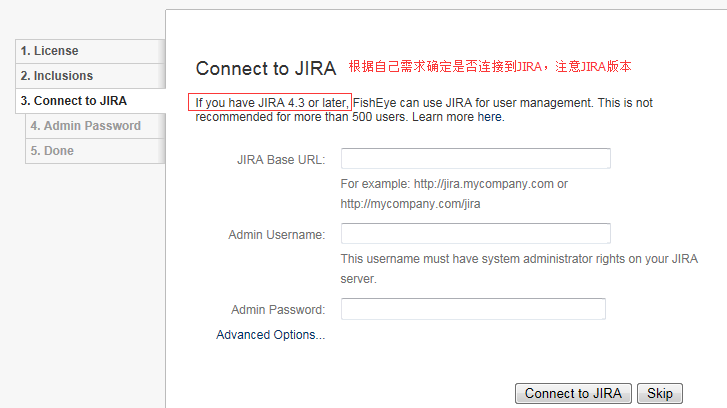
如果跳过,则创建管理员密码。
完成。