前几天接到一个任务,从gerrit上通过ssh命令获取一些commit相关的数据到文本文档中,随后将这些数据存入Excel中。数据格式如下图所示
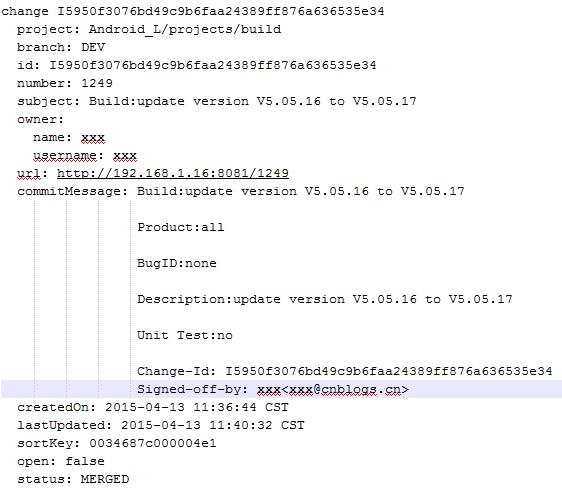
观察上图可知,存在文本文档中的数据符合一定的格式,通过python读取、正则表达式处理并写入Excel文档将大大减少人工处理的工作量。
1. 从gerrit获取原始信息,存入文本文档:
$ssh –p 29418 <your-account>@192.168.1.16 gerrit query status:merged since:<date/7/days/ago> 2>&1 | tee merged_patch_this_week.txt
2. 从txt文档中读取数据。
Python的标准库中,文件对象提供了三个“读”方法: .read()、.readline() 和 .readlines()。每种方法可以接受一个变量以限制每次读取的数据量,但它们通常不使用变量。 .read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。然而 .read() 生成文件内容最直接的字符串表示,但对于连续的面向行的处理,它却是不必要的,并且如果文件大于可用内存,则不可能实现这种处理。
readline() 和 readlines()之间的差异是后者一次读取整个文件,象 .read()一样。.readlines()自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for... in ... 结构进行处理。另一方面,.readline()每次只读取一行,通常比 .readlines()慢得多。仅当没有足够内存可以一次读取整个文件时,才应该使用.readline()。
patch_file_name="merged_patch_this_week.txt" patch_file=open(patch_file_name,'r') #打开文档,逐行读取数据 for line in open(patch_file_name): line=patch_file.readline() print line
3. 写入到Excel文档中
python处理Excel的函数库中,xlrd、xlwt、xlutils比较常用,网上关于它们的资料也有很多。但由于它们都不支持Excel 2007以后的版本(.xlsx),所以只能忍痛放弃。
经过一番搜索,找到了openpyxl这个函数库,它不仅支持Excel 2007,并且一直有人维护(当前最新版本为2.2.1,2015年3月31日发布)。官方的描述为:
A Python library to read/write Excel 2007 xlsx/xlsm files,它的文档清晰易读,相关网站:http://openpyxl.readthedocs.org/en/latest/index.html
openpyxl 下载地址:https://bitbucket.org/openpyxl/openpyxl/get/2.2.1.tar.bz2
它依赖于jdcal 模块,下载地址: https://pypi.python.org/packages/source/j/jdcal/jdcal-1.0.tar.gz
安装方法(windows 7):首先安装jdcal模块--解压缩到某目录,cd到该目录,运行"python setup.py install"。 然后安装openpyxl,方法相同。
写入步骤如下:
1. 打开工作簿:
wb=load_workbook('Android_Patch_Review-Y2015.xlsx')
2. 获得工作表
sheetnames = wb.get_sheet_names()
ws = wb.get_sheet_by_name(sheetnames[2]) 3. 将txt文档中的数据写入并设置单元格格式
patch_file_name="merged_patch_this_week.txt" patch_file=open(patch_file_name,'r') #打开文档,逐行读取数据 ft=Font(name='Neo Sans Intel',size=11) for line in open(patch_file_name): line=patch_file.readline() ws.cell(row=1,column=6).value=re.sub('project:','',line)#匹配project行,若匹配成功,则将字符串“project:”删除,剩余部分写入Excel第1行第6列 ws.cell(row=rows+1,column=1).font=ft
4. 保存工作簿
wb.save('Android_Patch_Review-Y2015.xlsx')
完整代码如下:
from openpyxl.workbook import Workbook from openpyxl.reader.excel import load_workbook from openpyxl.styles import PatternFill, Border, Side, Alignment, Protection, Font import re #from openpyxl.writer.excel import ExcelWriter #import xlrd ft=Font(name='Neo Sans Intel',size=11) #define font style bd=Border(left=Side(border_style='thin',color='00000000'), right=Side(border_style='thin',color='00000000'), top=Side(border_style='thin',color='00000000'), bottom=Side(border_style='thin',color='00000000')) #define border style alg_cc=Alignment(horizontal='center', vertical='center', text_rotation=0, wrap_text=True, shrink_to_fit=True, indent=0) #define alignment styles alg_cb=Alignment(horizontal='center', vertical='bottom', text_rotation=0, wrap_text=True, shrink_to_fit=True, indent=0) alg_lc=Alignment(horizontal='left', vertical='center', text_rotation=0, wrap_text=True, shrink_to_fit=True, indent=0) patch_file_name="merged_patch_this_week.txt" patch_file=open(patch_file_name,'r') #get data patch text wb=load_workbook('Android_Patch_Review-Y2015.xlsx') #open excel to write sheetnames = wb.get_sheet_names() ws = wb.get_sheet_by_name(sheetnames[2]) #get sheet rows=len(ws.rows) assert ws.cell(row=rows,column=1).value!=None, 'New Document or empty row at the end of the document? Please input at least one row!' print "The original Excel document has %d rows totally." %(rows) end_tag='type: stats' for line in open(patch_file_name): line=patch_file.readline() if re.match(end_tag,line) is not None: #end string break if len(line)==1: #go to next patch rows=rows+1 continue line = line.strip() # print line ws.cell(row=rows+1,column=1).value=ws.cell(row=rows,column=1).value+1 #Write No. ws.cell(row=rows+1,column=1).font=ft ws.cell(row=rows+1,column=1).border=bd ws.cell(row=rows+1,column=1).alignment=alg_cb ws.cell(row=rows+1,column=5).border=bd ws.cell(row=rows+1,column=9).border=bd if re.match('change',line) is not None: ws.cell(row=rows+1,column=2).value=re.sub('change','',line) #Write Gerrit ID ws.cell(row=rows+1,column=2).font=ft ws.cell(row=rows+1,column=2).border=bd ws.cell(row=rows+1,column=2).alignment=alg_cb if re.match('url:',line) is not None: ws.cell(row=rows+1,column=3).value=re.sub('url:','',line) #Write Gerrit url ws.cell(row=rows+1,column=3).font=ft ws.cell(row=rows+1,column=3).border=bd ws.cell(row=rows+1,column=3).alignment=alg_cb if re.match('project:',line) is not None: ws.cell(row=rows+1,column=6).value=re.sub('project:','',line) #Write project ws.cell(row=rows+1,column=6).font=ft ws.cell(row=rows+1,column=6).border=bd ws.cell(row=rows+1,column=6).alignment=alg_lc if re.match('branch:',line) is not None: ws.cell(row=rows+1,column=7).value=re.sub('branch:','',line) #Write branch ws.cell(row=rows+1,column=7).font=ft ws.cell(row=rows+1,column=7).border=bd ws.cell(row=rows+1,column=7).alignment=alg_cc if re.match('lastUpdated:',line) is not None: ws.cell(row=rows+1,column=8).value=re.sub('lastUpdated:|CST','',line) #Write update time ws.cell(row=rows+1,column=8).font=ft ws.cell(row=rows+1,column=8).border=bd ws.cell(row=rows+1,column=8).alignment=alg_cc if re.match('commitMessage:',line) is not None: description_str=re.sub('commitMessage:','',line) if re.match('Product:|BugID:|Description:|Unit Test:|Change-Id:',line) is not None: description_str=description_str+' '+line # if re.match('Signed-off-by:',line) is not None: description_str=description_str+' '+line ws.cell(row=rows+1,column=4).value=description_str #Write patch description ws.cell(row=rows+1,column=4).font=ft ws.cell(row=rows+1,column=4).border=bd ws.cell(row=rows+1,column=4).alignment=alg_lc wb.save('Android_Patch_Review-Y2015.xlsx') print 'Android_Patch_Review-Y2015.xlsx saved! Patch Collection Done!' #patch_file.close()
目前为止,基本功能已经实现,但是还有两个问题没有搞明白:
第一个是完整代码中的最后一句注释行,我搜到的几篇介绍openpyxl的博客中,打开文件后都没有close,所以我在代码中也没有close。理论上感觉还是需要的。等对文件对象的理解更加深入一些时会继续考虑这个问题。
第二是运行该脚本时有一个warning," UserWarning: Discarded range with reserved name,warnings.warn("Discarded range with reserved name")“,目前还在搜索原因,如有明白的,也请不吝告知。