1. 写在前面
在大数据实时计算方向,天猫双11的实时交易额是最具权威性的,当然技术架构也是相当复杂的,不是本篇博客的简单实现,因为天猫双11的数据是多维度多系统,实时粒度更微小的。当然在技术的总体架构上是相近的,主要的组件都是用到大数据实时计算组件Flink(当然阿里是用了基于Flink深度定制和优化改装的Blink)。下图是天猫双11实时交易额的大体架构模型及数据流向(参照https://baijiahao.baidu.com/s?id=1588506573420812062&wfr=spider&for=pc)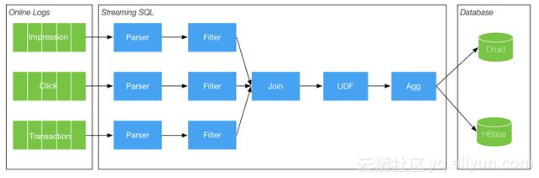
2. 仿天猫双11实时交易额技术架构
利用Linux shell自动化模拟每秒钟产生一条交易额数据,数据内容为用户id,购买商品的付款金额,用户所在城市及所购买的商品
技术架构上利用Filebeat去监控每生产的一条交易额记录,Filebeat将交易额输出到Kafka(关于Filebeat和kafka的安装或应用请参照之前的博客),然后编写Flink客户端程序去实时消费Kafka数据,对数据进行两块计算,一块是统计实时总交易额,一块是统计不同城市的实时交易额
技术架构图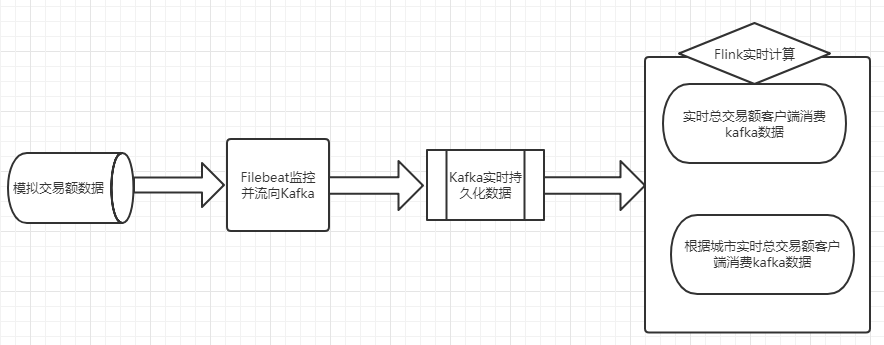
3.具体实现
3.1. 模拟交易额数据double11.sh脚本
#!/bin/bash
i=1
for i in $(seq 1 60)
do
customernum=`openssl rand -base64 8 | cksum | cut -c1-8`
pricenum=`openssl rand -base64 8 | cksum | cut -c1-4`
citynum=`openssl rand -base64 8 | cksum | cut -c1-2`
itemnum=`openssl rand -base64 8 | cksum | cut -c1-6`
echo "customer"$customernum","$pricenum",""city"$citynum",""item"$itemnum >> /home/hadoop/tools/double11/double11.log
sleep 1
done
将double11.sh放入Linux crontab
#每分钟执行一次
* * * * * sh /home/hadoop/tools/double11/double11.sh
3.2. 实时监控double11.log
Filebeat实时监控double11.log产生的每条交易额记录,将记录实时流向到Kafka的topic,这里只需要对Filebeat的beat-kafka.yml做简单配置,kafka只需要启动就好
3.3. 核心:编写Flink客户端程序
这里将统计实时总交易额和不同城市的实时交易额区分写成两个类(只提供Flink Java API)
需要导入的maven依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.0.0</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.8_2.11</artifactId>
<version>1.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
统计实时总交易额代码
package com.fastweb;
import java.util.Properties;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
public class Double11Sum {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.enableCheckpointing(1000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.184.12:9092");
properties.setProperty("zookeeper.connect", "192.168.184.12:2181");
properties.setProperty("group.id", "test");
FlinkKafkaConsumer08<String> myConsumer = new FlinkKafkaConsumer08<String>("test", new SimpleStringSchema(),
properties);
DataStream<String> stream = env.addSource(myConsumer);
DataStream<Tuple2<String, Integer>> counts = stream.flatMap(new LineSplitter()).keyBy(0).sum(1);
counts.print();
env.execute("Double 11 Real Time Transaction Volume");
}
//统计总的实时交易额
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
JSONObject object = JSONObject.parseObject(value);
String message = object.getString("message");
Integer price = Integer.parseInt(message.split(",")[1]);
out.collect(new Tuple2<String, Integer>("price", price));
}
}
}
统计不同城市的实时交易额
package com.fastweb;
import java.util.Properties;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
public class Double11SumByCity {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.enableCheckpointing(1000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.184.12:9092");
properties.setProperty("zookeeper.connect", "192.168.184.12:2181");
properties.setProperty("group.id", "test");
FlinkKafkaConsumer08<String> myConsumer = new FlinkKafkaConsumer08<String>("test", new SimpleStringSchema(),
properties);
DataStream<String> stream = env.addSource(myConsumer);
DataStream<Tuple2<String, Integer>> cityCounts = stream.flatMap(new CitySplitter()).keyBy(0).sum(1);
cityCounts.print();
env.execute("Double 11 Real Time Transaction Volume");
}
//按城市分类汇总实时交易额
public static final class CitySplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
JSONObject object = JSONObject.parseObject(value);
String message = object.getString("message");
Integer price = Integer.parseInt(message.split(",")[1]);
String city = message.split(",")[2];
out.collect(new Tuple2<String, Integer>(city, price));
}
}
}
代码解释:这里可以方向两个类里面只有flatMap的对数据处理的内部类不同,但两个内部类的结构基本相同,在内部类里面利用fastjson解析了一层获取要得到的数据,这是因为经过Filebeat监控的数据是json格式的,Filebeat这样实现是为了在正式的系统上确保每条数据的来源IP,时间戳等信息
3.4. 验证
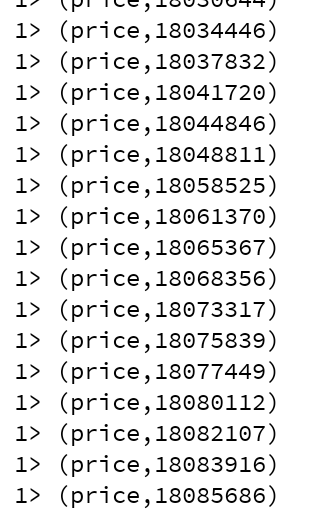
启动Double11Sum类的main方法就可以得到实时的总交易额,按城市分类的实时交易额也一样,这个结果是实时更新的,每条记录都是新的