1. CUDA里的块和线程概念可以用下面的图来表示:
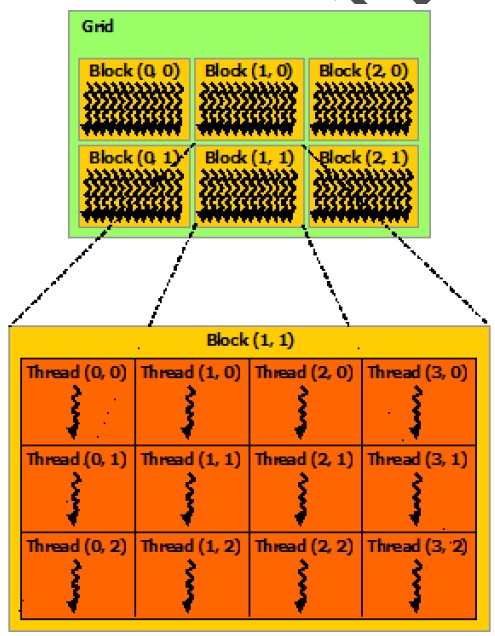
每个grid里包含可以用二维数组表示的block(块),每个block又包含一个可以用二维数组表示的thread(线程)。
2. 二维数组块和线程可以用dim3来定义:
dim3 blockPerGrid(3,2); //定义了3*2=6个blocks
dim3 threadsPerBlock(3,3);//定义了3*3=9个threads
3. 运行时每个线程的代码,如何知道自己是在哪个块里的哪个线程中运行呢?通过下面的变量计算:
* 块的二维索引:(blockIdx.x,blockIdx.y), 块二维数组x方向长度 gridDim.x,y方向长度 gridDim.y
* 每个块内线程的二维索引:(threadIdx.x,threadIdx.y) ,线程二维数组x方向长度 blockDim.x,y方向长度 blockDim.y
* 每个grid内有gridDim.x*gridDim.y个块,每个块内有 blockDim.x*blockDim.y个线程
通过上述参数可以确定每个线程的唯一编号:
tid= (blockIdx.y*gridDim.x+blockIdx.x)* blockDim.x*blockDim.y+threadIdx.y*blockDim.x+threadIdx.x;
4.下面具体一个例子,来引用上诉这些变量(仍引用上一个博客的N个数求和例子)
上一篇文章其实是用块和线程都是一维素组,现在我们用二维数组来实现
关键语句:
dim3 blockPerGrid(BLOCKS_PerGridX,BLOCKS_PerGridY); //定义了块二维数组
dim3 threadsPerBlock(THREADS_PerBlockX,THREADS_PerBlockY);//定义了线程二维数组
SumArray<<<blockPerGrid, threadsPerBlock>>>(dev_c, dev_a);
完整代码如下:
//////////////////////////////////////////
//////////////////////////////////////////
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, int *a);
#define TOTALN 72120
#define BLOCKS_PerGridX 2
#define BLOCKS_PerGridY 2
#define BLOCKS_PerGrid (BLOCKS_PerGridX*BLOCKS_PerGridY)
#define THREADS_PerBlockX 2 //2^8
#define THREADS_PerBlockY 4 //2^8
#define THREADS_PerBlock (THREADS_PerBlockX*THREADS_PerBlockY)
dim3 blockPerGrid(BLOCKS_PerGridX,BLOCKS_PerGridY); //定义了块二维数组
dim3 threadsPerBlock(THREADS_PerBlockX,THREADS_PerBlockY);//定义了线程二维数组
//grid 中包含BLOCKS_PerGridX*BLOCKS_PerGridY(2*2)个block
// blockIdx.x方向->,最大gridDim.x
// |***|***|*
// |0,0|0,1| blockIdx.y
// |***|***|* 方
// |1,0|1,1| 向
// |--------
// * ↓
// * 最大gridDim.y
// *
//每个block中包括THREADS_PerBlockX*THREADS_PerBlockY(4*2)个线程
// threadIdx.x方向->,最大值blockDim.x
// |***|***|*
// |0,0|0,1|
// |***|***|* threadIdx.y
// |1,0|1,1| 方
// |-------- 向
// |2,0|2,1| ↓
// |-------- 最大blockDim.y
// |3,0|3,1|
// |--------
// /
__global__ void SumArray(int *c, int *a)//, int *b)
{
__shared__ unsigned int mycache[THREADS_PerBlock];//设置每个块内同享内存threadsPerBlock==blockDim.x
//i为线程编号
int tid= (blockIdx.y*gridDim.x+blockIdx.x)* blockDim.x*blockDim.y+threadIdx.y*blockDim.x+threadIdx.x;
int j = gridDim.x*gridDim.y*blockDim.x*blockDim.y;//每个grid里一共有多少个线程
int cacheN;
unsigned sum,k;
cacheN=threadIdx.y*blockDim.x+threadIdx.x; //
sum=0;
while(tid<TOTALN)
{
sum += a[tid];// + b[i];
tid = tid+j;//获取下一个Grid里的同一个线程位置的编号
}
mycache[cacheN]=sum;
__syncthreads();//对线程块进行同步;等待该块里所有线程都计算结束
//下面开始计算本block中每个线程得到的sum(保存在mycache)的和
//递归方法:(参考《GPU高性能编程CUDA实战中文》)
//1:线程对半加:
k=THREADS_PerBlock>>1;
while(k)
{
if(cacheN<k)
{
//线程号小于一半的线程继续运行这里加
mycache[cacheN] += mycache[cacheN+k];//数组序列对半加,得到结果,放到前半部分数组,为下次递归准备
}
__syncthreads();//对线程块进行同步;等待该块里所有线程都计算结束
k=k>>1;//数组序列,继续对半,准备后面的递归
}
//最后一次递归是在该块的线程0中进行,所有把线程0里的结果返回给CPU
if(cacheN==0)
{
c[blockIdx.y*gridDim.x+blockIdx.x]=mycache[0];
}
}
int main()
{
int a[TOTALN] ;
int c[BLOCKS_PerGrid] ;
unsigned int j;
for(j=0;j<TOTALN;j++)
{
//初始化数组,您可以自己填写数据,我这里用1
a[j]=1;
}
// 进行并行求和
cudaError_t cudaStatus = addWithCuda(c, a);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
unsigned int sum1,sum2;
sum1=0;
for(j=0;j<BLOCKS_PerGrid;j++)
{
sum1 +=c[j];
}
//用CPU验证和是否正确
sum2=0;
for(j=0;j<TOTALN;j++)
{
sum2 += a[j];
}
printf("sum1=%d; sum2=%d ",sum1,sum2);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, int *a)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// 申请一个GPU内存空间,长度和main函数中c数组一样
cudaStatus = cudaMalloc((void**)&dev_c, BLOCKS_PerGrid * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// 申请一个GPU内存空间,长度和main函数中a数组一样
cudaStatus = cudaMalloc((void**)&dev_a, TOTALN * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
//////////////////////////////////////////////////
//////////////////////////////////////////////////
//////////////////////////////////////////////////
//////////////////////////////////////////////////
//////////////////////////////////////////////////
// Copy input vectors from host memory to GPU buffers.
//将a的数据从cpu中复制到GPU中
cudaStatus = cudaMemcpy(dev_a, a, TOTALN * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
//////////////////////////////////////////////////
//////////////////////////////////////////////////
//////////////////////////////////////////////////
//////////////////////////////////////////////////
//////////////////////////////////////////////////
// dim3 threadsPerBlock(8,8);
//dim3 blockPerGrid(8,8);
// Launch a kernel on the GPU with one thread for each element.
//启动GPU上的每个单元的线程
SumArray<<<blockPerGrid, threadsPerBlock>>>(dev_c, dev_a);//, dev_b);
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
//等待全部线程运行结束
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel! ", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, BLOCKS_PerGrid * sizeof(int), cudaMemcpyDeviceToHost);
cudaStatus = cudaMemcpy(a, dev_a, TOTALN * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
return cudaStatus;
}