每当我们谈到对于分布式系统容错性的时候,我们其实真正想聊的是里面的状态一致性的控制。而当我们再想深入探讨一致性控制的时候,我们想到的可能是经典的Paxos协议。但是Paxos协议实现起来较为复杂,而且原理本身也不易理解。笔者在之前文章中聊过一个更易理解和实现的一致性协议Raft协议:聊聊Raft一致性协议以及Apache Ratis。在Raft协议中,引入了Leader、Follower以及Candidate三种角色来做一致性控制中的投票选举过程。本文笔者来聊聊里Raft协议中最为关键的投票选举过程以及它的一个实现版本。在开源项目Apache Ratis中,对此协议有完整的版本实现。
Raft协议的投票选举原理在Raft协议的投票过程中,它是由1个Candidate候选者向其它Follower发送投票请求,让这些Follower投票选择Candidate。然后这些Follower将会返回给Candidate。如果这个Candidate收到超过半数以上的总票数的时候,那么此Candidate就可以当选为Leader身份了。
投票过程如下图所示: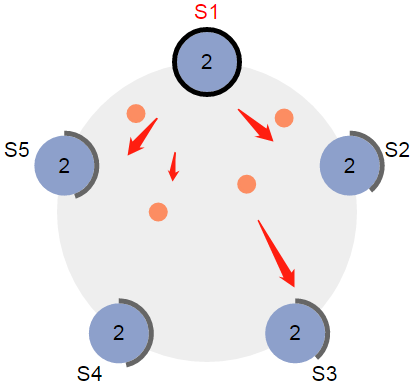
投票请求结果返回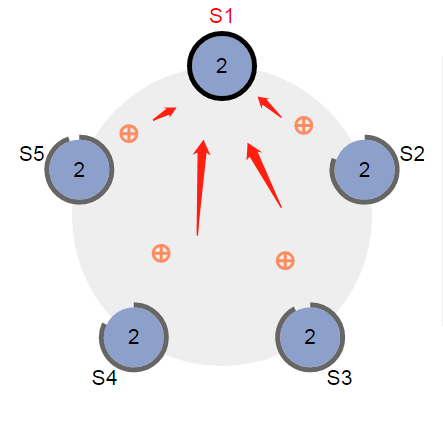
上述投票选举过程在现实情况中其实还有很多种边缘情况,比如同时有另外一个Candidate在投票选举时怎么办?当发起此轮投票选举时,发现已经有新的投票Leader选举已被选出来了,怎么处理呢。
下面我们来看看这些边缘情况Raft协议中是怎么处理的。
Raft协议的投票选举细节及代码实现这里我们要从Leader选举的源头开始讲起。当系统启动好之后,初始选举后系统由1个Leader和若干个Follower角色组成。然后突然由于某个异常原因,Leader服务出现了异常,导致Follower角色检测到和Leader的上次RPC更新时间超过给定阈值时间时。此时Follower会认为Leader服务已出现异常,然后它将会发起一次新的Leader选举行为,同时将自身的状态从Follower切换为Candidate身份。随后请求其它Follower投票选择自己。
这里笔者结合Apache Ratis中对于Raft的实现来展开阐述,上述超时时间代码如下:
public void run() {
long sleepDeviationThresholdMs = server.getSleepDeviationThresholdMs();
while (monitorRunning && server.isFollower()) {
...
synchronized (server) {
// 如果当前Follower检测到上次RPC时间超过规定阈值,则开始将自身切为候选者身份
if (outstandingOp.get() == 0 && lastRpcTime.elapsedTimeMs() >= electionTimeout) {
LOG.info("{}:{} changes to CANDIDATE, lastRpcTime:{}, electionTimeout:{}ms",
server.getId(), server.getGroupId(), lastRpcTime.elapsedTimeMs(), electionTimeout);
// election timeout, should become a candidate
server.changeToCandidate();
break;
}
}
...
}
}
然后切换为Candidate的服务发起新的领导选举,
synchronized void changeToCandidate() {
Preconditions.assertTrue(isFollower());
role.shutdownFollowerState();
setRole(RaftPeerRole.CANDIDATE, "changeToCandidate");
if (state.shouldNotifyExtendedNoLeader()) {
stateMachine.notifyExtendedNoLeader(getRoleInfoProto());
}
// 然后此Candidate发起新的领导选举
role.startLeaderElection(this);
}
接着我们需将当前Leader选举的轮次更新,通俗地解释可理解为第几届选举了,这个值在Candidate每次发起选举时会递增。选举轮次编号信息是一个十分重要的信息,这可以避免那些消息落后的Candidate发起滞后的领导选举过程,而获取最新的Leader信息。
private void askForVotes() throws InterruptedException, IOException {
final ServerState state = server.getState();
while (shouldRun()) {
// one round of requestVotes
final long electionTerm;
final RaftConfiguration conf;
synchronized (server) {
// (1).初始化当前选举轮次编号,比当前的轮次递增1
electionTerm = state.initElection();
conf = state.getRaftConf();
state.persistMetadata();
}
...
final ResultAndTerm r;
// (2).获取除自身外其他Follow服务的Service信息
final Collection<RaftPeer> others = conf.getOtherPeers(server.getId());
if (others.isEmpty()) {
r = new ResultAndTerm(Result.PASSED, electionTerm);
} else {
final Executor voteExecutor = new Executor(this, others.size());
try {
// (3).发起投票过程
final int submitted = submitRequests(electionTerm, lastEntry, others, voteExecutor);
// (4).等待投票结果返回
r = waitForResults(electionTerm, submitted, conf, voteExecutor);
} finally {
voteExecutor.shutdown();
}
}
下面我们来进入submitRequests的实际子过程,看看Follower在接收到投票请求时,是如何处理的。
private RequestVoteReplyProto requestVote(
RaftPeerId candidateId, RaftGroupId candidateGroupId,
long candidateTerm, TermIndex candidateLastEntry) throws IOException {
...
synchronized (this) {
final FollowerState fs = role.getFollowerState().orElse(null);
// (1)Follower判断发起的领导轮次编号是否落后于当前的轮次
if (shouldWithholdVotes(candidateTerm)) {
LOG.info("{}-{}: Withhold vote from candidate {} with term {}. State: leader={}, term={}, lastRpcElapsed={}",
getMemberId(), role, candidateId, candidateTerm, state.getLeaderId(), state.getCurrentTerm(),
fs != null? fs.getLastRpcTime().elapsedTimeMs() + "ms": null);
} else if (state.recognizeCandidate(candidateId, candidateTerm)) {
// (2)轮次编号,CandidateId有效,当前Follower投票给请求方的Candidate
final boolean termUpdated = changeToFollower(candidateTerm, true, "recognizeCandidate:" + candidateId);
// see Section 5.4.1 Election restriction
if (state.isLogUpToDate(candidateLastEntry) && fs != null) {
fs.updateLastRpcTime(FollowerState.UpdateType.REQUEST_VOTE);
// (3)记下当前Follower投票的CandidateId,用来表明此Follower的投票归属
// 避免发生二次投票
state.grantVote(candidateId);
voteGranted = true;
}
if (termUpdated || voteGranted) {
state.persistMetadata(); // sync metafile
}
}
...
}
return reply;
}
这里我们着重再来看state.recognizeCandidate操作,它在Follower作出投票选举前做了哪些关键的验证操作呢。
/**
* 判断当前的轮次编号,给定的Candidate身份是否是可接受的
*/
boolean recognizeCandidate(RaftPeerId candidateId, long candidateTerm) {
if (!getRaftConf().containsInConf(candidateId)) {
return false;
}
final long current = currentTerm.get();
// 如果当前投票选举编号轮次是新的领导选举轮次,则是可接受的
if (candidateTerm > current) {
return true;
} else if (candidateTerm == current) {
// 如果不是,意为此选举轮次中,有多个Candidate发起了领导选择
// 此时判断当前Follower是否已经投出过票:
// 1)没有投出过票,Candidate可接受
// 2) 投出过票,但是投出的票不是给定Candidate,则不接受
return votedFor == null || votedFor.equals(candidateId);
}
return false;
}
从上面处理中,我们可以注意到这里面是会存在多个Candidate同时发生新轮次的领导选举过程中,这个时候就还得进行投票归属信息的判断,避免Follower投出进行二次投票过程。当然在这个过程中,我们也要保证投票相关变量的更新务必是原子更新的。
随后Follower将投票结果返回给发起请求的Candidate,然后Candidate进行了以下的处理过程。
private ResultAndTerm waitForResults(final long electionTerm, final int submitted,
RaftConfiguration conf, Executor voteExecutor) throws InterruptedException {
final Timestamp timeout = Timestamp.currentTime().addTimeMs(server.getRandomTimeoutMs());
final Map<RaftPeerId, RequestVoteReplyProto> responses = new HashMap<>();
final List<Exception> exceptions = new ArrayList<>();
int waitForNum = submitted;
Collection<RaftPeerId> votedPeers = new ArrayList<>();
while (waitForNum > 0 && shouldRun(electionTerm)) {
...
try {
// (1)从投票线程池中拿出投票结果
final Future<RequestVoteReplyProto> future = voteExecutor.poll(waitTime);
if (future == null) {
continue; // poll timeout, continue to return Result.TIMEOUT
}
final RequestVoteReplyProto r = future.get();
final RaftPeerId replierId = RaftPeerId.valueOf(r.getServerReply().getReplyId());
final RequestVoteReplyProto previous = responses.putIfAbsent(replierId, r);
if (previous != null) {
LOG.warn("{} received duplicated replies from {}, the 2nd reply is ignored: 1st = {}, 2nd = {}",
server.getId(), replierId, ServerProtoUtils.toString(previous), ServerProtoUtils.toString(r));
continue;
}
if (r.getShouldShutdown()) {
return logAndReturn(Result.SHUTDOWN, responses, exceptions, -1);
}
// (2)如果发现当前Follower的领导选举已经是新的轮次的话,则返回新的轮次信息
if (r.getTerm() > electionTerm) {
return logAndReturn(Result.DISCOVERED_A_NEW_TERM, responses,
exceptions, r.getTerm());
}
// (3)接受到成功的返回结果,加入到投票结果列表中
if (r.getServerReply().getSuccess()) {
votedPeers.add(replierId);
// 如果投票总数超过半数以上时,则表明当前领导选举通过
if (conf.hasMajority(votedPeers, server.getId())) {
return logAndReturn(Result.PASSED, responses, exceptions, -1);
}
}
} catch(ExecutionException e) {
LogUtils.infoOrTrace(LOG, () -> this + " got exception when requesting votes", e);
exceptions.add(e);
}
waitForNum--;
}
// (4)规定时间内没有获取到足够多的票数,则当前领导选举竞选失败
return logAndReturn(Result.REJECTED, responses, exceptions, -1);
}
Candidate对于上述最终结果的处理过程如下:
private void askForVotes() throws InterruptedException, IOException {
final ServerState state = server.getState();
while (shouldRun()) {
...
try {
// (3).发起投票过程
final int submitted = submitRequests(electionTerm, lastEntry, others, voteExecutor);
// (4).等待投票结果返回
r = waitForResults(electionTerm, submitted, conf, voteExecutor);
} finally {
voteExecutor.shutdown();
}
}
synchronized (server) {
if (!shouldRun(electionTerm)) {
return; // term already passed or this should not run anymore.
}
// (5)对选举结果的处理
switch (r.result) {
case PASSED:
// 选举通过,则切换当前身份为Leader
server.changeToLeader();
return;
case SHUTDOWN:
LOG.info("{} received shutdown response when requesting votes.", this);
server.getProxy().close();
return;
// 如果选举失败或发现更新一轮的选举轮次(说明别的Candidate发起的领导选举已经成功)
// 则进行相应信息更新
case REJECTED:
case DISCOVERED_A_NEW_TERM:
final long term = Math.max(r.term, state.getCurrentTerm());
server.changeToFollowerAndPersistMetadata(term, Result.DISCOVERED_A_NEW_TERM);
return;
case TIMEOUT:
// should start another election
}
}
}
}
以上就是Apache Ratis内部基于Raft协议的投票过程的代码实现过程。在这里,为了避免可能存在多个Candidate几乎同时发生投票,导致结果完全一致从而需要进行下一轮次的选举。这里会进行随机时间间隔的设置,来错开投票的发起时间。
在Apache Ratis中,也有此细节的实现:
public void run() {
long sleepDeviationThresholdMs = server.getSleepDeviationThresholdMs();
while (monitorRunning && server.isFollower()) {
// 随机时间的设置,避免完全同时投票选举过程发生
final long electionTimeout = server.getRandomTimeoutMs();
try {
if (!JavaUtils.sleep(electionTimeout, sleepDeviationThresholdMs)) {
continue;
}
...
synchronized (server) {
if (outstandingOp.get() == 0 && lastRpcTime.elapsedTimeMs() >= electionTimeout) {
// ...
server.changeToCandidate();
break;
}
}
...
}
}
这个corner case是可能存在的,比如A, B, C, D四个服务,A和B要竞选Leader身份,当按照下述选举过程时,就会出现平票结果:
1)每个Candidate会向非自身服务发起投票选举,但是如若自身也收到投票选举时,默认只选自己,不会投向其它Candidate
2)Candidate A向B, C,D发起投票选举,B也是Candidate,它只会投给自己,同时C投票给A。接着D投给了B。这样就出现了平票2对2的情况了。
当然上述情况主要多加1个服务,就不会出现平票的情况了,
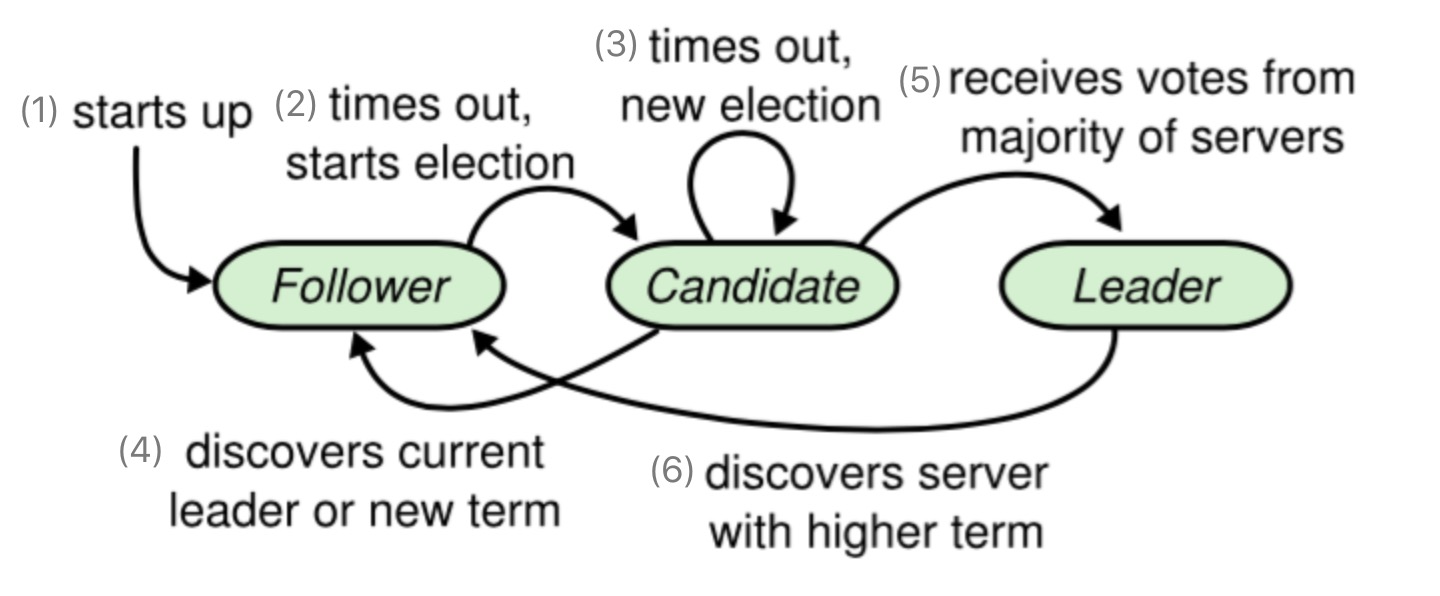
最后附上Raft投票选举过程图,大家可以对照上述的子过程实现,进行对比,学习。总体来讲,投票实现过程还是比较易于理解的。
[1].https://raft.github.io/raft.pdf
[2].http://ratis.incubator.apache.org/
[3].https://raft.github.io/
[4].https://blog.csdn.net/Androidlushangderen/article/details/86763412