随着互联网用户的快速增长,数据体量的急剧膨胀,数据中心对计算的需求也在迅猛上涨。诸如深度学习在线预测、直播中的视频转码、图片压缩解压缩以及HTTPS加密等各类应用对计算的需求已远远超出了传统CPU处理器的能力所及。摩尔定律失效的今天,关注“新“成员(GPUFPGAASIC)为数据中心带来的体系架构变革,为业务配上一台动力十足的发动机。
1 异构计算:WHY
明明CPU用的好好的,为什么我们要考虑异构计算芯片呢?

随着互联网用户的快速增长,数据体量的急剧膨胀,数据中心对计算的需求也在迅猛上涨。诸如深度学习在线预测、直播中的视频转码、图片压缩解压缩以及HTTPS加密等各类应用对计算的需求已远远超出了传统CPU处理器的能力所及。
历史上,受益于半导体技术的持续演进,计算机体系结构的吞吐量和系统性能不断提高,处理器的性能每18个月就能翻倍(众所周知的“摩尔定律”),使得处理器的性能可以满足应用软件的需求。但是,近几年半导体技术改进达到了物理极限,电路越来越复杂,每一个设计的开发成本高达数百万美元,数十亿美元才能形成新产品投产能力。2016年3月24日,英特尔宣布正式停用“Tick-Tock”处理器研发模式,未来研发周期将从两年周期向三年期转变。至此,摩尔定律对英特尔几近失效。
一方面处理器性能再无法按照摩尔定律进行增长,另一方面数据增长对计算性能要求超过了按“摩尔定律”增长的速度。处理器本身无法满足高性能计算(HPC:High Performance Compute)应用软件的性能需求,导致需求和性能之间出现了缺口(参见图1)。
一种解决方法是通过硬件加速,采用专用协处理器的异构计算方式来提升处理性能。
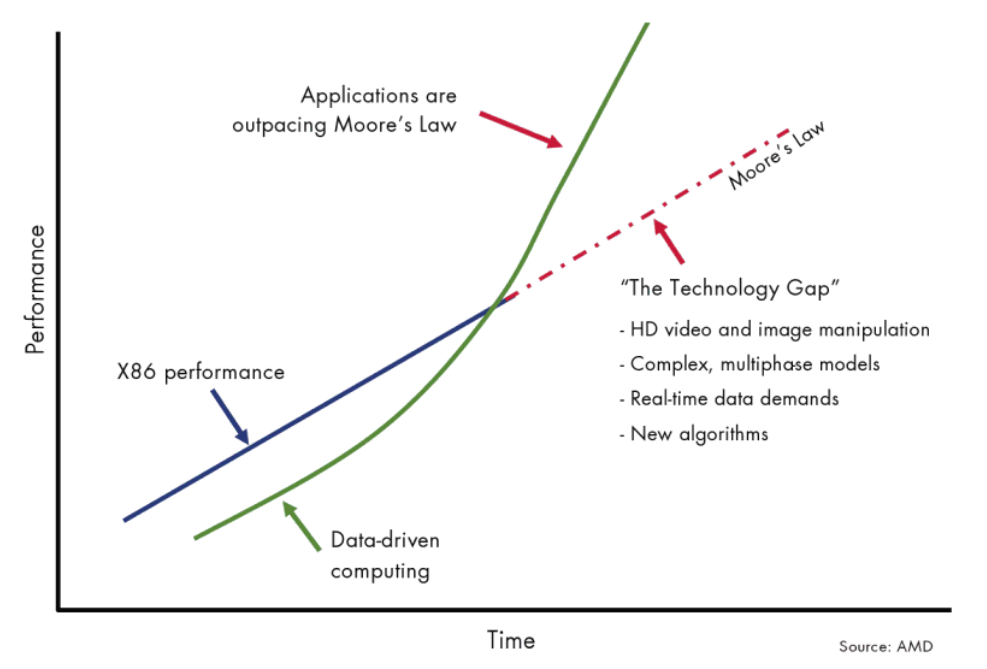
图1 计算需求和计算能力的缺口发展形式
2 异构计算:STANDARDS
通常我们在为业务提供解决方案的时候,部署平台会有四种选择CPU、GPU、FPGA、ASIC。那有什么标准来评判计算平台的优劣呢?

图:我是法官,标准我说了算
当今理想的协处理器应该是基于硬件的设计,具备三种基本能力。第一是设计能够提供专门的硬件加速实现各种应用中需要的关键处理功能。其次是协处理器设计在性能上非常灵活,使用流水线和并行结构,跟上算法更新以及性能的需求变化。最后,协处理器能够为主处理器和系统存储器提供宽带、低延迟接口。
除了硬件要求以外,理想的协处理器还应该满足HPC市场的“4P”要求:性能(performance)、效能(productivity)、功耗(power)和价格(price)。
HPC市场对性能的最低要求是全面加速实现算法,而不仅仅是某一步骤,并能够加速实现整个应用软件。
效能需求来自最终用户。在现有的计算机系统中,协处理器必须安装起来很方便,提供简单的方法来配置系统,加速实现现有的应用软件。
HPC市场的功耗需求来自计算系统安装和使用上的功耗限制。对于大部分用户,能够提供给计算机的空间有限。计算系统的功耗越小,那么可以采取更少的散热措施来保持计算机不会过热。因此,低功耗协处理器不但能够为计算系统提供更低的运转成本,而且还提高了计算系统的空间利用率。
价格因素在HPC市场上显得越来越重要。十几年前,某些应用软件对性能的需求超出了单个处理器能力范围,这促使人们采用专用体系结构,例如密集并行处理(MPP)和对称多处理(SMP)等。然而,这类系统要求使用定制处理器单元和专用数据通路,开发和编程都非常昂贵。
现在的HPC市场抛弃了如此昂贵的方法,而是采用性价比更高的集群计算方法。集群计算采用商用标准体系结构,例如Intel和AMD;采用工业标准互联,例如万兆以太网和InfiniBand;采用标准程序语言,例如运行在低成本Linux操作系统上的C语言等。当今的协处理器设计必须能够平滑集成到商用集群计算环境中,其成本和在集群中加入另一个节点大致相当。
了解了基本的评判标准之后,我们以当今最火的深度学习为例,从芯片架构、计算性能、功耗、开发难度几个方面来对几种不同的芯片进行分析对比。
3.2 芯片计算性能
深度学习的学名又叫深层神经网络(Deep Neural Networks),是从人工神经网络(Artificial Neural Networks)模型发展而来。我们以深度学习作为切入点来分析各个芯片的性能。图3是神经网络的基本结构,模型中每一层的大量计算是上一层的输出结果和其对应的权重值这两个矩阵的乘法运算。
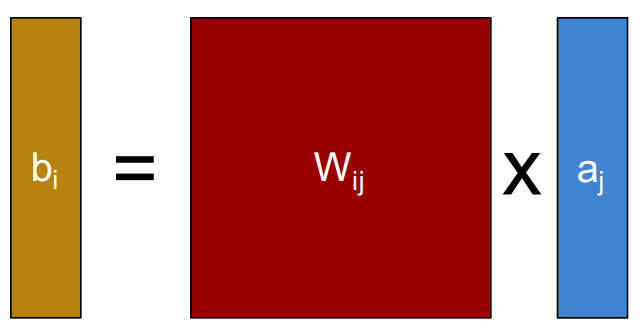
图3 神经网络基本结构
横向对比CPU,GPU,FPGA,ASIC计算能力,实际对比的是:
1.硬件芯片的乘加计算能力。
2.为什么有这样乘加计算能力?
3.是否可以充分发挥硬件芯片的乘加计算能力?
带着这三个问题,我们进行硬件芯片的计算能力对比。
本文转载自腾云阁,已获得作者授权。