在前面我们通过fromnltk.bookimport*的方式获取了一些预定义的文本。本章将讨论各种文本语料库
1古腾堡语料库
古腾堡是一个大型的电子图书在线网站,网址是http://www.gutenberg.org/。上面有超过36000本免费的电子图书,因此也是一个大型的预料库。NLTK也包含了其中的一部分
。通过nltk.corpus.gutenberg.fileids()就可以查看包含了那些文本。
['austen-emma.txt','austen-persuasion.txt','austen-sense.txt','bible-kjv.txt','blake-poems.txt','bryant-stories.txt','burgess-busterbrown.txt','carroll-alice.txt','chesterton-ball.txt','chesterton-brown.txt','chesterton-thursday.txt','edgeworth-parents.txt','melville-moby_dick.txt','milton-paradise.txt','shakespeare-caesar.txt','shakespeare-hamlet.txt','shakespeare-macbeth.txt','whitman-leaves.txt']
通过len(nltk.corpus.gutenberg.words('austen-emma.txt'))就可以知道特定文本里面包含了多少字符。来看下下面的这个代码,num_chars统计的是有多少个字符,num_words统计的是有多少个字母,num_sends统计的是有多少个句子。通过这些指标可以依次算出平均每个单词的词长,平均句子的长度,和每个词出现的平均次数
forfiledingutenberg.fileids():
num_chars=len(gutenberg.raw(filed))
num_words=len(gutenberg.words(filed))
num_sends=len(gutenberg.sents(filed))
num_vocab=len(set([w.lower()forwingutenberg.words(filed)]))
print(int(num_chars/num_words),int(num_words/num_sends),int(num_words/num_vocab),filed)
运行的时候提示如下错误。
Resourcepunktnotfound.
PleaseusetheNLTKDownloadertoobtaintheresource:
>>>importnltk
>>>nltk.download('punkt')
Searchedin:
-'/home/zhf/nltk_data'
-'/usr/share/nltk_data'
-'/usr/local/share/nltk_data'
-'/usr/lib/nltk_data'
-'/usr/local/lib/nltk_data'
-'/usr/nltk_data'
-'/usr/lib/nltk_data'
这个是因为在使用gutenberg.sents(filed)的时候会有那个到punkt资源。需要进行下载
>>>importnltk
>>>nltk.download('punkt')
[nltk_data]Downloadingpackagepunktto/root/nltk_data...
[nltk_data]Unzippingtokenizers/punkt.zip.
True
下载生成了tokenizers文件
root@zhf-maple:~/nltk_data#ls-al
总用量12
drwxr-xr-x3rootroot40964月110:30.
drwx------18rootroot40964月110:45..
drwxr-xr-x3rootroot40964月110:39tokenizers
由于是采用的root账户,因此默认是下载到了/root/nltk_data,需要将tokenizers文件copy到前面错误提示的路径下面去
重新运行结果如下:
/usr/bin/python3.6/home/zhf/py_prj/function_test/NLTP_fun.py
42426austen-emma.txt
42616austen-persuasion.txt
42822austen-sense.txt
43379bible-kjv.txt
4195blake-poems.txt
41914bryant-stories.txt
41712burgess-busterbrown.txt
42012carroll-alice.txt
42011chesterton-ball.txt
42211chesterton-brown.txt
41810chesterton-thursday.txt
42024edgeworth-parents.txt
42515melville-moby_dick.txt
45210milton-paradise.txt
4118shakespeare-caesar.txt
4127shakespeare-hamlet.txt
4126shakespeare-macbeth.txt
43612whitman-leaves.txt
网络和聊天文本:
前面介绍的古腾堡语料库主要包含的是文学,这些词汇都是些正式词汇,NLTK中还包含了很多非正式的语音,比如网络上的文本集合,例如评论,交流论坛等。代码如下。打印出所有的文本以及每个文本的前10个字符
fromnltk.corpusimportwebtext
if__name__=="__main__":
forfieldinwebtext.fileids():
print(field,webtext.raw(field)[:10])
firefox.txtCookieMan
grail.txtSCENE1:[
overheard.txtWhiteguy:
pirates.txtPIRATESOF
singles.txt25SEXYMA
wine.txtLovelydel
布朗语料库:
布朗语料库是一个百万级的英语电子语料库,包含各种不同来源的文本。按照文体分类,如新闻,体育,小说等。
brown.categories()#所有的分类
brown.fileids()#所有的文件名
brown.words(categories='news')#分类为news的词汇
['adventure','belles_lettres','editorial','fiction','government','hobbies','humor','learned','lore','mystery','news','religion','reviews','romance','science_fiction']
['ca01','ca02','ca03','ca04','ca05','ca06','ca07','ca08','ca09','ca10','ca11','ca12','ca13','ca14','ca15','ca16','ca17','ca18','ca19','ca20','ca21','ca22','ca23','ca24','ca25','ca26','ca27','ca28','ca29','ca30','ca31','ca32','ca33','ca34','ca35','ca36','ca37','ca38','ca39','ca40','ca41','ca42','ca43','ca44','cb01','cb02','cb03','cb04','cb05','cb06','cb07','cb08','cb09','cb10','cb11','cb12','cb13','cb14','cb15','cb16','cb17','cb18','cb19','cb20','cb21','cb22','cb23','cb24','cb25','cb26','cb27','cc01','cc02','cc03','cc04','cc05','cc06','cc07','cc08','cc09','cc10','cc11','cc12','cc13','cc14','cc15','cc16','cc17','cd01','cd02','cd03','cd04','cd05','cd06','cd07','cd08','cd09','cd10','cd11','cd12','cd13','cd14','cd15','cd16','cd17','ce01','ce02','ce03','ce04','ce05','ce06','ce07','ce08','ce09','ce10','ce11','ce12','ce13','ce14','ce15','ce16','ce17','ce18','ce19','ce20','ce21','ce22','ce23','ce24','ce25','ce26','ce27','ce28','ce29','ce30','ce31','ce32','ce33','ce34','ce35','ce36','cf01','cf02','cf03','cf04','cf05','cf06','cf07','cf08','cf09','cf10','cf11','cf12','cf13','cf14','cf15','cf16','cf17','cf18','cf19','cf20','cf21','cf22','cf23','cf24','cf25','cf26','cf27','cf28','cf29','cf30','cf31','cf32','cf33','cf34','cf35','cf36','cf37','cf38','cf39','cf40','cf41','cf42','cf43','cf44','cf45','cf46','cf47','cf48','cg01','cg02','cg03','cg04','cg05','cg06','cg07','cg08','cg09','cg10','cg11','cg12','cg13','cg14','cg15','cg16','cg17','cg18','cg19','cg20','cg21','cg22','cg23','cg24','cg25','cg26','cg27','cg28','cg29','cg30','cg31','cg32','cg33','cg34','cg35','cg36','cg37','cg38','cg39','cg40','cg41','cg42','cg43','cg44','cg45','cg46','cg47','cg48','cg49','cg50','cg51','cg52','cg53','cg54','cg55','cg56','cg57','cg58','cg59','cg60','cg61','cg62','cg63','cg64','cg65','cg66','cg67','cg68','cg69','cg70','cg71','cg72','cg73','cg74','cg75','ch01','ch02','ch03','ch04','ch05','ch06','ch07','ch08','ch09','ch10','ch11','ch12','ch13','ch14','ch15','ch16','ch17','ch18','ch19','ch20','ch21','ch22','ch23','ch24','ch25','ch26','ch27','ch28','ch29','ch30','cj01','cj02','cj03','cj04','cj05','cj06','cj07','cj08','cj09','cj10','cj11','cj12','cj13','cj14','cj15','cj16','cj17','cj18','cj19','cj20','cj21','cj22','cj23','cj24','cj25','cj26','cj27','cj28','cj29','cj30','cj31','cj32','cj33','cj34','cj35','cj36','cj37','cj38','cj39','cj40','cj41','cj42','cj43','cj44','cj45','cj46','cj47','cj48','cj49','cj50','cj51','cj52','cj53','cj54','cj55','cj56','cj57','cj58','cj59','cj60','cj61','cj62','cj63','cj64','cj65','cj66','cj67','cj68','cj69','cj70','cj71','cj72','cj73','cj74','cj75','cj76','cj77','cj78','cj79','cj80','ck01','ck02','ck03','ck04','ck05','ck06','ck07','ck08','ck09','ck10','ck11','ck12','ck13','ck14','ck15','ck16','ck17','ck18','ck19','ck20','ck21','ck22','ck23','ck24','ck25','ck26','ck27','ck28','ck29','cl01','cl02','cl03','cl04','cl05','cl06','cl07','cl08','cl09','cl10','cl11','cl12','cl13','cl14','cl15','cl16','cl17','cl18','cl19','cl20','cl21','cl22','cl23','cl24','cm01','cm02','cm03','cm04','cm05','cm06','cn01','cn02','cn03','cn04','cn05','cn06','cn07','cn08','cn09','cn10','cn11','cn12','cn13','cn14','cn15','cn16','cn17','cn18','cn19','cn20','cn21','cn22','cn23','cn24','cn25','cn26','cn27','cn28','cn29','cp01','cp02','cp03','cp04','cp05','cp06','cp07','cp08','cp09','cp10','cp11','cp12','cp13','cp14','cp15','cp16','cp17','cp18','cp19','cp20','cp21','cp22','cp23','cp24','cp25','cp26','cp27','cp28','cp29','cr01','cr02','cr03','cr04','cr05','cr06','cr07','cr08','cr09']
['The','Fulton','County','Grand','Jury','said',...
由于词汇量众多我们可以统计特定词汇的出现次数,采用FreqDist的方法
newx_text=brown.words(categories='news')
fdist=nltk.FreqDist([w.lower()forwinnewx_text])
models=['can','could','may','might','must','will']
forminmodels:
print(m+':',fdist[m])
在新闻中下面词语的出现次数。
can:94
could:87
may:93
might:38
must:53
will:389
就职演说库:NLTK中的就职演说库汇集了从1789到2009的演讲记录
print(inaugural.fileids())
print([fileid[:4]forfileidininaugural.fileids()])#文件名的前4位就是具体的年份
['1789-Washington.txt','1793-Washington.txt','1797-Adams.txt','1801-Jefferson.txt','1805-Jefferson.txt','1809-Madison.txt','1813-Madison.txt','1817-Monroe.txt','1821-Monroe.txt','1825-Adams.txt','1829-Jackson.txt','1833-Jackson.txt','1837-VanBuren.txt','1841-Harrison.txt','1845-Polk.txt','1849-Taylor.txt','1853-Pierce.txt','1857-Buchanan.txt','1861-Lincoln.txt','1865-Lincoln.txt','1869-Grant.txt','1873-Grant.txt','1877-Hayes.txt','1881-Garfield.txt','1885-Cleveland.txt','1889-Harrison.txt','1893-Cleveland.txt','1897-McKinley.txt','1901-McKinley.txt','1905-Roosevelt.txt','1909-Taft.txt','1913-Wilson.txt','1917-Wilson.txt','1921-Harding.txt','1925-Coolidge.txt','1929-Hoover.txt','1933-Roosevelt.txt','1937-Roosevelt.txt','1941-Roosevelt.txt','1945-Roosevelt.txt','1949-Truman.txt','1953-Eisenhower.txt','1957-Eisenhower.txt','1961-Kennedy.txt','1965-Johnson.txt','1969-Nixon.txt','1973-Nixon.txt','1977-Carter.txt','1981-Reagan.txt','1985-Reagan.txt','1989-Bush.txt','1993-Clinton.txt','1997-Clinton.txt','2001-Bush.txt','2005-Bush.txt','2009-Obama.txt']
['1789','1793','1797','1801','1805','1809','1813','1817','1821','1825','1829','1833','1837','1841','1845','1849','1853','1857','1861','1865','1869','1873','1877','1881','1885','1889','1893','1897','1901','1905','1909','1913','1917','1921','1925','1929','1933','1937','1941','1945','1949','1953','1957','1961','1965','1969','1973','1977','1981','1985','1989','1993','1997','2001','2005','2009']
我们通过ConditionalFreqDist(条件概率分布函数)来看下这些年演讲过程中america和citizen出现的频率。条件概率分布函数处理的是配对列表,每对的形式是(条件,事件),在下面的例子中条件是[‘america’,’citizen’],事件是fileid[:4](年份)
cfd=nltk.ConditionalFreqDist((target,fileid[:4])
forfileidininaugural.fileids()
forwininaugural.words(fileid)
fortargetin['america','citizen']
ifw.lower().startswith(target))
cfd.plot()
可以看到america的次数今年来逐渐增加,而citizen的次数却是略微下降的趋势。
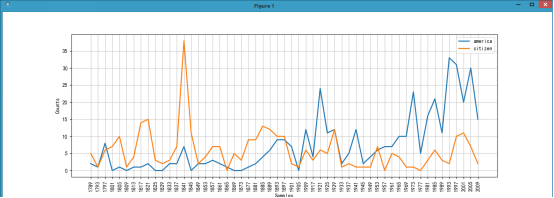
我们可以通过cfd.tabulate()打印出条件概率分布表:上面的图片也是根据这个表画出来的。
1789179317971801180518091813181718211825182918331837184118451849185318571861186518691873187718811885188918931897190119051909191719211925192919331937194119451949195319571961196519691973197719811985198919931997200120052009
america21801011200227022321001246997012424111225122467710102351621113331203015
citizen5167101414153237381124770539913121010216365121211170541103632101172
None
cfd.conditons():将条件按字母排序来分类
cfd[conditions]:此条件下的频率分布
cfd[conditions][sample]:此条件下给定样本的频率
下面来打印看下
print(cfd.conditions())
print(cfd['america'])
print(cfd['america']['2001'])
可以看到cfd['america']其实是返回的是一个FreqDist对象。也就是对应的频率统计
/usr/bin/python3.6/home/zhf/py_prj/function_test/NLTP_fun.py
['citizen','america']
<FreqDistwith47samplesand408outcomes>
20