摘要:
POST/esstudy/user/3/__更新{“doc”:{“name”:“Wang Wu Upgrade”,“age”:23}}1.3删除Delete/xxx1.4以获取get/xxx5?查询名为张三、年龄为21岁的GETEStudy/用户/_搜索{“查询”:{“bool”:}“must”:〔{“match”:{“name”:“张三”}},{“match”:{“age”:21}}}〕}2.应该只满足一个条件/_搜索{“查询“:{”bool“:{“should”:〔}“mat”匹配“:}name”:”张三“},{“match:{”age“:22}]}}}}}3。大多数情况下,not查询不满足条件,即,搜索{“query”:{“bool”:}“must_not”:〔{”match“:{”name“:”Zhang San“},{”匹配“:{”age“:22}〕}}4。filtergt意味着大于gte意味着大于或等于lt意味着小于lte意味着小于或等于GEesstudy/user/搜索{”query“:}”bool“:”most“:”〔{“match”:“:”name““:”张三“}}}】},“filter”:{”range“:”。
1.简单操作
1.1 增加
先插入四条数据
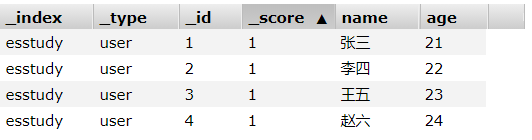
PUT /esstudy/user/1 { "name": "张三", "age": 21 } PUT /esstudy/user/2 { "name": "李四", "age": 22 } PUT /esstudy/user/3 { "name": "王五", "age": 23 } PUT /esstudy/user/4 { "name": "赵六", "age": 24 }
看一下数据:
如果说数据存在那么便是覆盖(全量覆盖)
PUT /esstudy/user/1 { "name": "法外狂徒张三", "age": 21, "desc": "法律大牛" }
再执行
GET /esstudy/user/1
PUT /esstudy/user/2 { "name": "李四" }
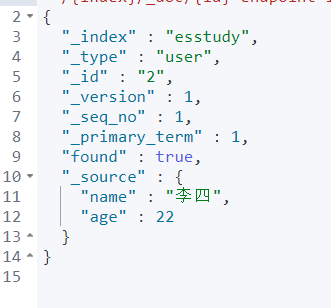
已经修改了 那么 PUT 可以更新数据但是。麻烦的是 原数据你还要重写一遍要 这不符合我们规矩。
1.2 更新
使用 POST 命令,在 id 后面跟 _update ,要修改的内容放到 doc 文档(属性)中即可。
POST /esstudy/user/3/_update { "doc":{ "name": "王五升级", "age": 23 } }

1.3 删除
DELETE /xxx
1.4 获取
GET /xxx
5.查询
GET esstudy/user/_search?q=name:赵六
通过 _serarch?q=name:狂神说 查询条件是name属性有赵六的那些数据。
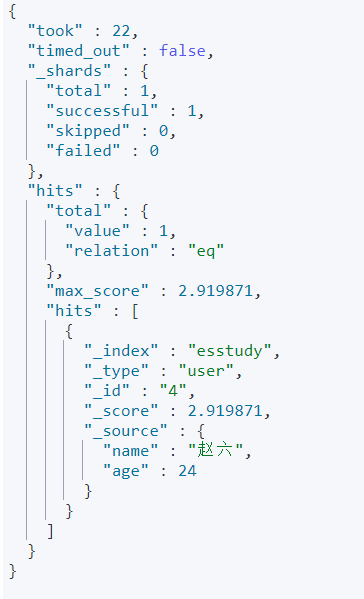
我们看一下结果 返回并不是 数据本身,是给我们了一个 hits ,还有 _score得分,就是根据算法算出和
查询条件匹配度高得分就搞。
2.复杂查询
2.1 查询所有
GET esstudy/user/_search { "query": { "match_all": {} } }
2.2 构建查询
再插入一条数据
PUT /esstudy/user/5 { "name": "张三", "age": 21 }
再进行查询
GET esstudy/user/_search { "query": { "match": { "name": "法外狂徒张三" } } }
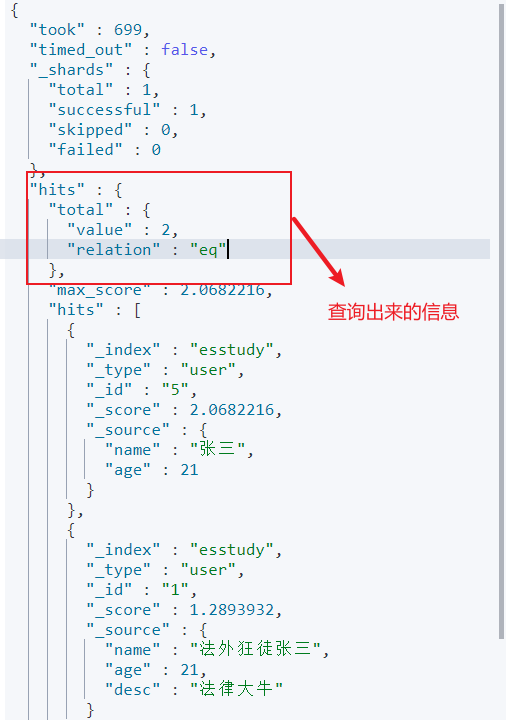
通过分数来查看谁更加符合结果
2.3限制属性
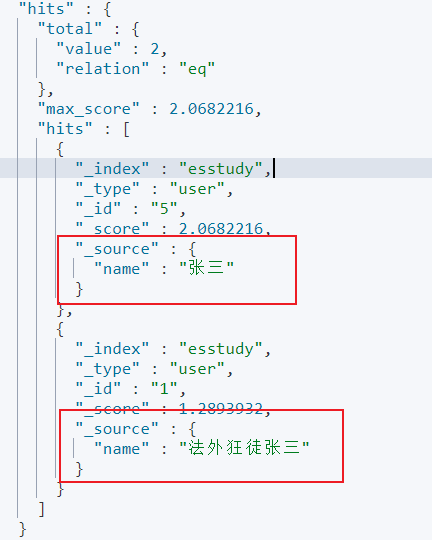
通过 _source 来控制,比如说只需要名字的属性
GET esstudy/user/_search { "query": { "match": { "name": "张三" } }, "_source": ["name"] }
2.4 排序
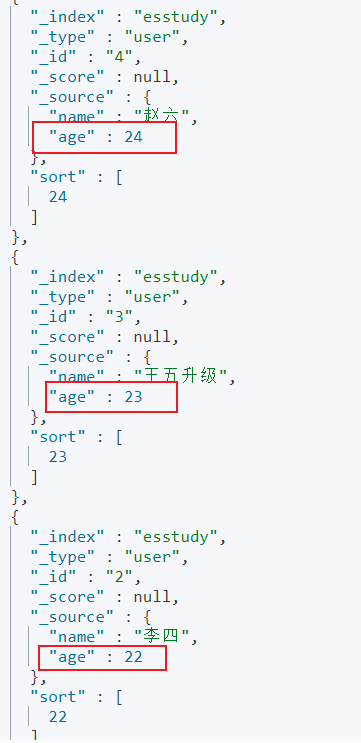
根据年龄倒序
GET esstudy/user/_search { "query": { "match_all": {} }, "sort": [ { "age": { "order": "desc" } } ] }
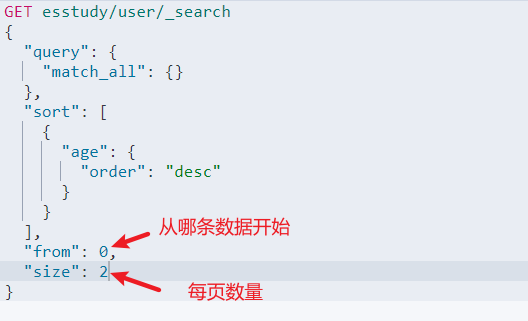
2.5 分页
GET esstudy/user/_search { "query": { "match_all": {} }, "sort": [ { "age": { "order": "desc" } } ], "from": 0, "size": 2 }

2.6 布尔查询
1. must
都要符合
例如。查询名字是张三,年龄是21的
GET esstudy/user/_search { "query": { "bool": { "must": [ { "match": { "name": "张三" } }, { "match": { "age": 21 } } ] } } }

2. should
只要满足一个即可
GET esstudy/user/_search { "query": { "bool": { "should": [ { "match": { "name": "张三" } }, { "match": { "age": 22 } } ] } } }

查询不满足条件的,即过滤操作
GET esstudy/user/_search { "query": { "bool": { "must_not": [ { "match": { "name": "张三" } }, { "match": { "age": 22 } } ] } } }

4. filter
gt 表示大于
gte 表示大于等于
lt 表示小于
lte 表示小于等于
GET esstudy/user/_search { "query": { "bool": { "must": [ { "match": { "name": "张三" } } ], "filter": { "range": { "age": { "gte": 20, "lte": 40 } } } } } }
2.7 term精确查询
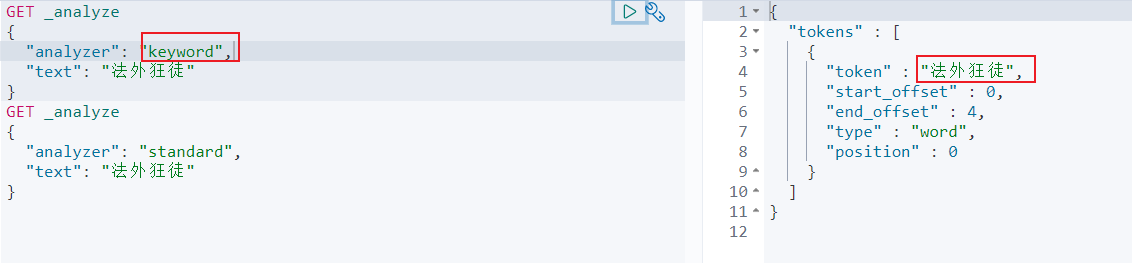
关于分词:
term 查询是直接通过倒排索引指定的词条,也就是精确查找。
term和match的区别:
- match是经过分析(analyer)的,也就是说,文档是先被分析器处理了,根据不同的分析器,分析出的结果也会不同,在会根据分词 结果进行匹配。
- term是不经过分词的,直接去倒排索引查找精确的值。
注意 ⚠ :我们现在 用的es7版本 所以我们用 mappings properties 去给多个字段(fifields)指定类型的时
候,不能给我们的索引制定类型:
创建规则
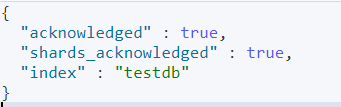
PUT testdb { "mappings": { "properties": { "name": { "type": "text" }, "desc": { "type": "keyword" } } } }
插入数据:
PUT testdb/_doc/1 { "name": "法外狂徒1号", "desc": "法外狂徒1号decs" } PUT testdb/_doc/2 { "name": "法外狂徒2号", "desc": "法外狂徒2号decs" }
总结:keyword 字段类型不会被分析器分析!
然后使用term查询
GET testdb/_search { "query": { "term": { "desc": "法外狂徒2号decs" } } }
可以看到结果只有一个

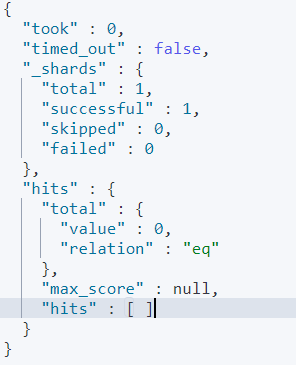
如果只查询法外狂徒那么一个都没有
GET testdb/_search { "query": { "term": { "desc": "法外狂徒" } } }
精确查询多个值:
GET esstudy/user/_search { "query": { "bool": { "should": [ { "term": { "age": "22" } }, { "term": { "age": 21 } } ] } } }
2.8 高亮显示
GET esstudy/user/_search
{
"query": {
"match": {
"name": "张三"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
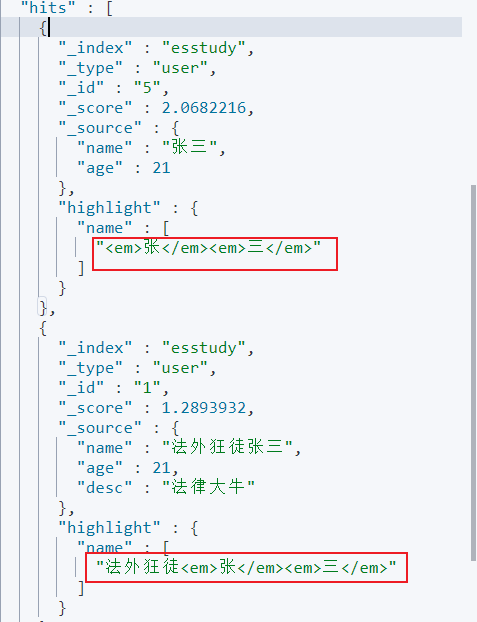
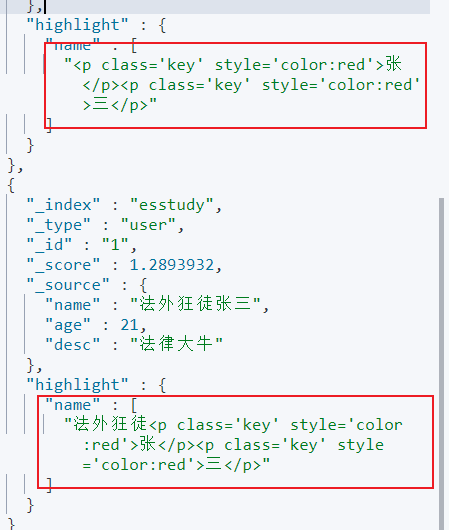
可以看到加上了em标签,当然我们也可以自定义。
GET esstudy/user/_search { "query": { "match": { "name": "张三" } }, "highlight": { "pre_tags": "<p style='color:red'>", "post_tags": "</p>", "fields": { "name": {} } } }