最近在调研3D算法方面的工作,整理了几篇多视角学习的文章。还没调研完,先写个大概。
因为直接用2D的卷积神经网络方法并不能很好的处理3D任务,这几篇文章主要偏向于将3D模型从多个角度变换成多张2D的图像,然后使用2D领域的方法处理3D任务。所以大家主要涉及到两个问题:1、视角选择问题(如何选择视角?选择几个视角?如果能够主动的选择显著性视角就更好了);2、视角特征信息的融合。
- 1、(ICCV2015)MVCNN:Multi-view Convolutional Neural Networks for 3D Shape Recognition
- 2、(CVPR2016) Volumetric and multi-view CNNs for object classification on 3D data
- 3、(BMVC2017)DSCNN:Dominant Set Clustering and Pooling for Multi-View 3D Object Recognition
- 4、(CVPR2018)GVCNN: Group-View Convolutional Neural Networks for 3D Shape Recognition
- 5、(CVPR2018)MHBN:Multi-view Harmonized Bilinear Network for 3D Object Recognition
- 6、(TMM2018)Learning multi-view representation with LSTM for 3D shape recognition and retrieval
- 7、(CVPR2018)RotationNet: Joint Object Categorization and Pose Estimation Using Multiviews from Unsupervised Viewpoints
- 8、(ICCV2019)Learning Relationships for Multi-View 3D Object Recognition
- 9、(CVPR2020)View-gcn: View-based graph convolutional network for 3D shape analysis
- 10、(CVPR2020)End-to-End Learning Local Multi-view Descriptors for 3D Point Clouds
论文地址:https://arxiv.org/abs/1505.00880
代码:https://github.com/suhangpro/mvcnn
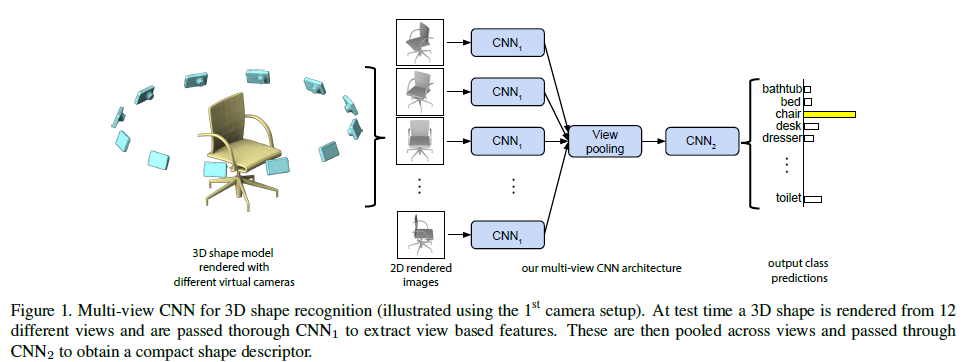
简单的求一个3D形状的多视角图像的特征描述子的平均值,或者简单的将这些特征描述子做“连接”(这地方可以想象成将特征简单的“串联”),会导致不好的效果。所以,我们集中于融合多视角2D图像产生的特征,以便综合这些信息,形成一个简单、高效的3D形状描述子。
因此,我们设计了Multi-view CNN(MVCNN),放在基础的2D图像CNN之中。如图所示,同一个3D形状的 每一张视角图像 各自独立地经过第一段的CNN1卷积网络,在一个叫做View-pooling层进行“聚合”。之后,再送入剩下的CNN2卷积网络。整张网络第一部分的所有分支,共享相同的 CNN1里的参数。在View-pooling层中,我们逐元素取最大值操作,另一种是求平均值操作,但在我们的实验中,这并不有效。这个View-pooling层,可以放在网络中的任何位置。经过我们的实验,这一层最好放在最后的卷积层(Conv5),以最优化的执行分类与检索的任务。
参考:https://blog.csdn.net/qq_25011449/article/details/81029812
https://blog.csdn.net/khflash/article/details/80154051
论文地址:https://arxiv.org/abs/1604.03265
代码:https://github.com/charlesq34/3dcnn.torch
论文地址:https://arxiv.org/abs/1906.01592?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+arxiv%2FQSXk+%28ExcitingAds%21+cs+updates+on+arXiv.org%29
代码:https://github.com/fate3439/dscnn
论文地址:
https://openaccess.thecvf.com/content_cvpr_2018/html/Feng_GVCNN_Group-View_Convolutional_CVPR_2018_paper.html
代码:https://github.com/ace19-dev/gvcnn-tf
https://github.com/LemingGuo/gvcnn
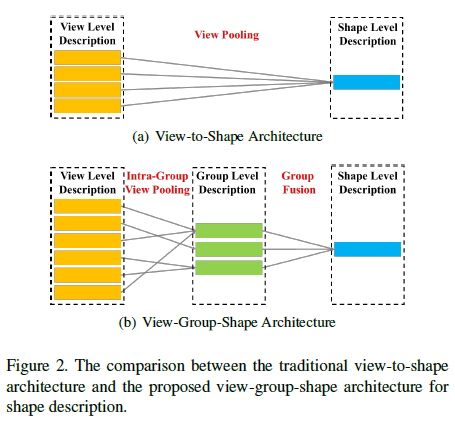
MVCNN的做法就是模拟相机从若干不同的角度拍摄三维物体,得到投影的二维图像,然后分别利用ImageNet下预训练的网络提取特征,随后通过view pooling,即全局最大池化将各视角下的特征聚合起来,再接分类网络。
作者认为,MVCNN并没有将多视角下特征之间的关系有效地利用起来,这也会在一定程度上限制最后的特征描述子的可区分力。
• 一方面,一些视角彼此相类似,然后有一些则差异较大。这些相似的视角对于3D物体形状的表示所起到的作用应该是同等的。
• 另一方面,有一部分视角则能提取到更有用的特征。
也正是为了解决上述的问题,才提出了GVCNN。
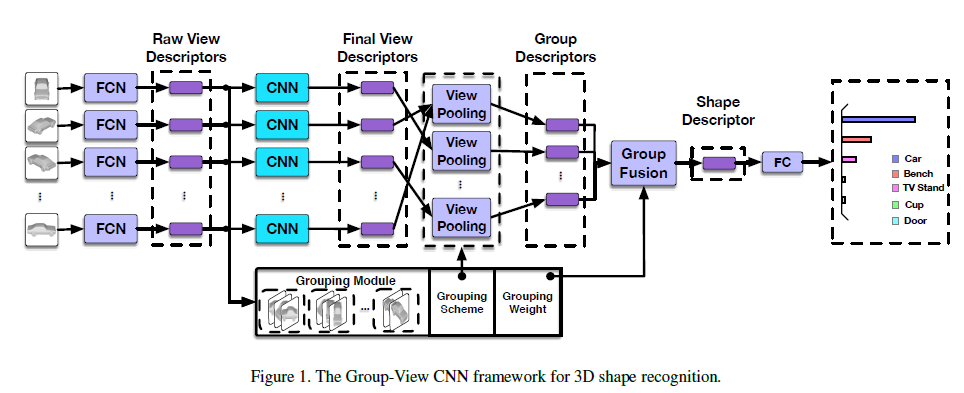
• GVCNN采用GoogLeNet作为基础网络。
• "FCN"是GoogleNet的前5个卷积层。
• 中间的"CNN"指的是也是GoogLeNet。
• "FC"是全连接层。
GVCNN首先从若干不同视角拍摄三维模型的二维图像,每个视角的图像都被送入了第一部分的"FCN"中提取视觉描述子。随后,第二部分的CNN网络进一步提取视觉特征,group模块再根据判别力评分将不同视角的特征子进行分组。最后将各个组的视觉特征描述子通过view pooling(全局池化)聚合到一起。再接上分类网络进行分类。
多视角视觉特征、Grouping模块、组内视角池化、组间特征融合,这五部分详细看论文。
参考:https://blog.csdn.net/hongbin_xu/article/details/96699145
论文地址:https://openaccess.thecvf.com/content_cvpr_2018/html/Yu_Multi-View_Harmonized_Bilinear_CVPR_2018_paper.html
代码:https://github.com/LiyuanLacfo/MHBNN-PyTorch
论文地址:
代码:https://github.com/charlesq34/3dcnn.torch
论文地址:https://arxiv.org/abs/1603.06208
代码:https://github.com/kanezaki/pytorch-rotationnet
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/html/Wei_View-GCN_View-Based_Graph_Convolutional_Network_for_3D_Shape_Analysis_CVPR_2020_paper.html
代码:https://github.com/weixmath/view-GCN
不同视角下看不同物体可能是不同的。因而,不同视图图像的联系可能隐藏了3D物体的潜在信息,这将为3D物体形状识别提供有价值的信息。因而,作者设计了GCN来自动调差视图间的关系。
主要挑战:如何聚合多视图特征成为一个全局的3D形状描述。
传统方法:通过最大池化来聚合多视图特征,该方法是置换不变的,但忽略了视图之间的关系。
该方法:使用view-Graph来表示物体的3D形状,每一个视图对应图中一个节点。如图1所示。节点间的边由摄像机坐标的k近邻确定。在此基础上设计了一种图卷积神经网络view-GCN用于聚合多视图特征以学习全局形状描述子。
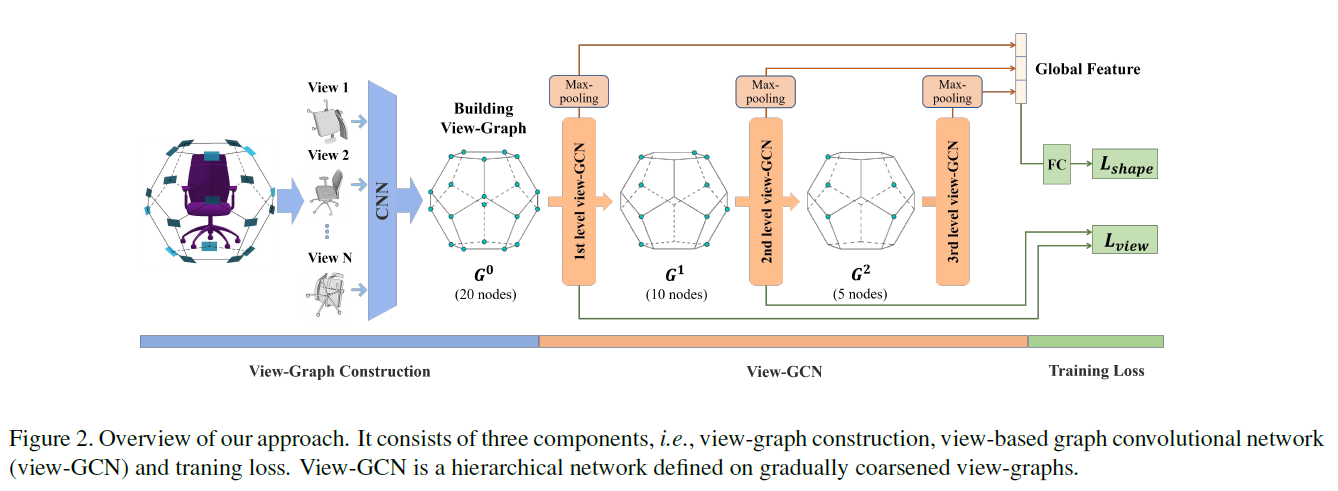
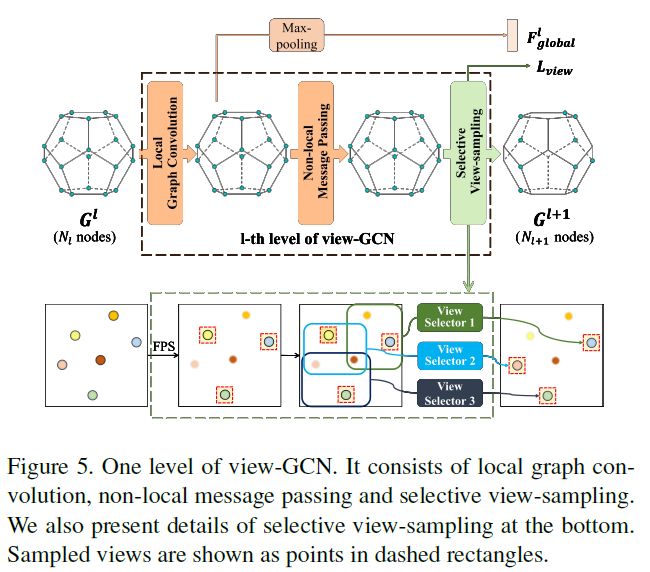
View-GCN是一个层次化的GCN架构,在越来越粗糙的视图上有多个层次。每层设计了一个局部图卷积操作 + 一个非局部消息传递操作,通过研究相邻图和远程成对视图之间的关系来聚合多视图特征。为使图粗化,提出了一种选择性视图抽样策略,通过视图选择器对有代表性的视图进行抽样。所有学习到的不同层次的特征被组合成一个全局形状描述子。
参考:https://blog.csdn.net/qq_38904659/article/details/107341099
https://blog.csdn.net/weixin_43882112/article/details/108464941
论文地址:https://arxiv.org/abs/2003.05855
代码:https://github.com/craigleili/3DLocalMultiViewDesc