视图是从一个或者多个表导出的,它的行为与表非常相似,但视图是一个虚拟表,在视图中可以使用SELECT语句查询数据,以及使用insert、update和delete语句修改记录,对于视图的操作最终转化为对基本数据表的操作。视图不仅可以方便操作,而且可以保障数据库系统的安全性。
视图一经定义便存储在数据库中,与其相对应的数据并没有像表数据那样在数据库中在存储一份,通过视图看到的数据只是存放在基本表中的数据。可以对其进行增删该查,通过视图对数据修改,基本表数据也对应变化,反之亦然。
1.2 使用视图的目的与好处
1.聚焦特定数据:使用户只能看到和操作与他们有关的数据,提高了数据的安全性。2.简化数据操作:使用户不必写复杂的查询语句就可对数据进行操作。
3.定制用户数据:使不同水平的用户能以不同的方式看到不同的数据。
4.合并分离数据:视图可以从水平和垂直方向上分割数据,但原数据库的结构保持不变。
2 创建视图
语法:| [withcheckoption]--强制所有通过是同修改的数据,都要满足select语句中指定的条件 select查询语句 as [withencryption]--用于加密视图的定义,用户只能查看不能修改。 [(列名表)] createview视图 |
usemarvel_db; --创建一个学生表 createtablestuTable( idintidentity(1,1)primarykey,--id主键,自增 namevarchar(20), genderchar(2), ageint, ) --往表中插入数据 insertintostuTable(name,gender,age) values ('刘邦','男',23), ('项羽','男',22), ('韩信','男',21); insertintostuTable(name,gender,age)values('萧何','男',24) |
--创建视图 if(exists(select*fromsys.objectswherename='stu_view')) dropviewstu_view go --stu_view()不实用参数,默认为基础表中的列名称 --注意createview必须是批处理里面的语句 createviewstu_view as selectname,agefromstuTablewhereage>20; go --执行视图 select*fromstu_view; |
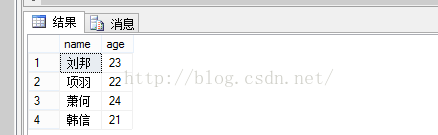
3 修改视图
go alterviewstu_view as select*fromstuTablewhereage>22; go select*fromstu_view |
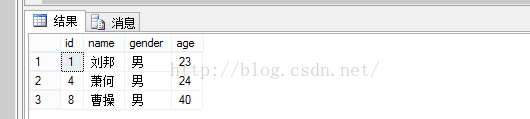
4 删除视图
go --语法 dropviewview_name1,view_name2,......,view_nameN; --该语句可以同时删除多个视图,只要在删除各视图名称之间用逗号分隔即可。 |
--语法 dropviewstu_view; --该语句可以同时删除多个视图,只要在删除各视图名称之间用逗号分隔即可。 |
注意:
1.可通过视图向基表中插入数据,但插入的数据实际上存放在基表中,而不是存放在视图中。
2.如果视图引用了多个表,使用insert语句插入的列必须属于同一个表。
3.若创建视图时定义了“with check option”选项,则使用视图向基表中插入数据时,必须保证插入后的数据满足定义视图的限制条件。
--(1).通过视图向基本表中插入数据 go createviewstu_insert_view(编号,姓名,性别,年龄) as selectid,name,gender,agefromstuTable; go select*fromstuTable; ---插入一条数据 insertintostu_insert_viewvalues('孙权','男',34); ----查看插入记录之后表中的内容。 select*fromstuTable; |
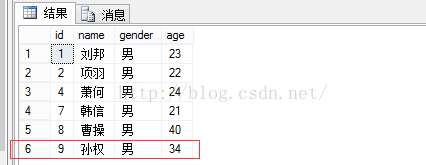
(2).通过视图修改基本表的数据
| --查看修改之前的数据 select*fromstuTable; |
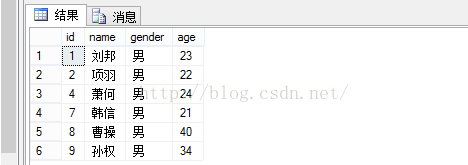
--修改数据 updatestu_insert_viewset年龄=30where姓名='刘邦'; --查看修改后的数据 select*fromstuTable; |
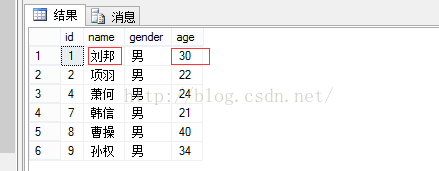
(3).通过视图删除基本表的数据
注意:
1.要删除的数据必须包含在视图的结果集中。
2.如果视图引用了多个表时,无法用delete命令删除数据。
语法
| --语法 deletestu_insert_viewwherecondition; |
删除之前:
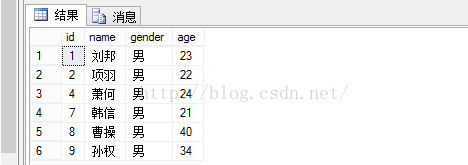
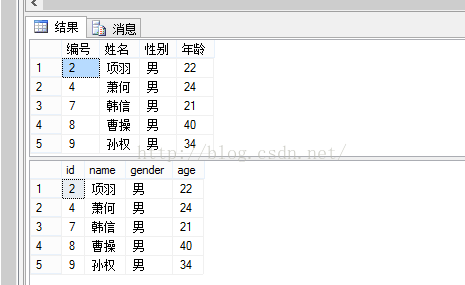
删除:
--例子 deletestu_insert_viewwhere姓名='刘邦'; select*fromstu_insert_view; select*fromstuTable; |
2.涉及到权限管理方面,比如某表中的部分字段含有机密信息,不应当让低权限的用户访问到的情况,这时候给这些用户提供一个适合他们权限的视图,供他们阅读自己的数据就行了。
2.视图与表的区别:
1.视图是已经编译好的SQL语句,是基于SQL语句的结果集的可视化表,而表不是;
2.视图(除过索引视图)没有实际的物理记录,而基本表有;
3.表示内容,视图是窗口;
4.表占物理空间,而视图不占物理空间,视图只是逻辑概念的存在;
5.视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全角度说,视图可以防止用户接触数据表,从而不知表结构;
6.表属于全局模式的表,是实表;视图数据局部模式的表,是虚表;
7.视图的建立和删除只影响视图本身,不影响对应的基本表。
转载自:https://blog.csdn.net/marvel_java/article/details/53353475