环境
master node: 数量 1, 系统 ubuntu 16.04_amd64
worker node: 数量 1, 系统 ubuntu 16.04_amd64
kubernetes 版本: v1.10.07
安装docker
sudo -E bash docker.sh
部署kubernetes(master node)
以下操作在master node 上执行:
执行selinux_ipv6.sh,关闭selinux、开启ipv6:
#!/bin/sh # 关闭 selinux sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config setenforce 0 # 开启ipv6 cat <<EOF > /etc/sysctl.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF modprobe br_netfilter sysctl -p执行脚本:
sudo bash selinux_ipv6.sh下载k8s.io镜像
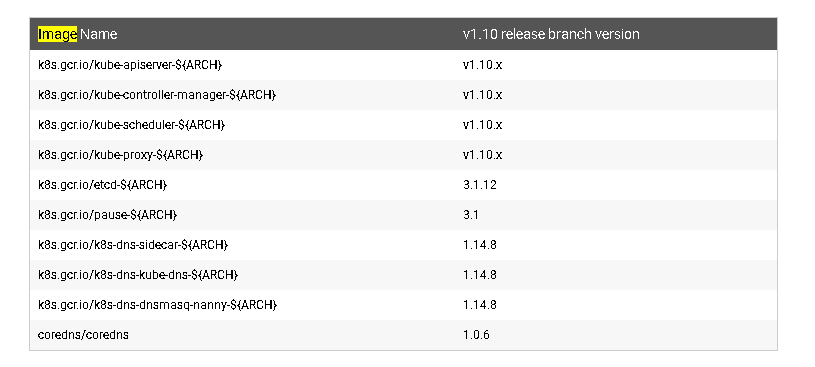
如上表所示的镜像都是我们所需要的,但是由于网络环境的限制导致我们无法直接从gcr.io的源地址拉去镜像,只能在本地事先下载好所需要的镜像,执行k8s_v1.10_images_download.sh脚本即可:sudo bash k8s_v1.10_images_download.sh安装kubeadm
首先,在source.list.d中添加阿里的kubernetes源:# 添加源 cat <<EOF > /etc/apt/sources.list.d/kubernetes.list deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main EOF # 安装源证书 curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add - # 更新源 apt-get update注意,需要在root账户下执行以上命令。
然后安装kubeadm相关组件:
apt-get install -y kubeadm=1.10.7-00初始化 kubernetes 服务
kubeadm init --kubernetes-version=v1.10.7 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=0.0.0.0 --ignore-preflight-errors='Swap'显示结果如下:
Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join 192.168.1.185:6443 --token ow8gkw.yltjigl52r7q3jlq --discovery-token-ca-cert-hash sha256:aa2e50c49a35bcf65edfcf6081159adbf27d7d5a09707d584636a9ab4e1e7b3c按照上面显示的指示,copy kube-config:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config查看当前节点状态:
kubectl get nodes显示结果如下:
NAME STATUS ROLES AGE VERSION whty0-to-be-filled-by-o-e-m NotReady master 2h v1.10.7之所以没有处于Ready状态,是因为我们还没有配置 可以使得kubernetes节点之间互相通信的网络插件.
添加worker节点(worker node)
通过kubeadm上面显示的token就可以,引导其他节点加入到k8s集群:
关闭selinux、开启ipv6
参照上一节下载k8s.io镜像
参照上一节安装kubeadm 组件
参照上一节引导worker node 加入集群:
sudo kubeadm join 192.168.1.185:6443 --token ow8gkw.yltjigl52r7q3jlq --discovery-token-ca-cert-hash sha256:aa2e50c49a35bcf65edfcf6081159adbf27d7d5a09707d584636a9ab4e1e7b3c --ignore-preflight-errors='swap' --ignore-preflight-errors='cri'这里所传入的token就是在master节点上初始化时最后显示的token,需要注意的是token是具有有效期的,在有效期过后需要重新发放token,最终显示结果如下:
[preflight] Running pre-flight checks. [WARNING SystemVerification]: docker version is greater than the most recently validated version. Docker version: 18.06.1-ce. Max validated version: 17.03 [WARNING CRI]: unable to check if the container runtime at "/var/run/dockershim.sock" is running: exit status 1 [WARNING Swap]: running with swap on is not supported. Please disable swap [discovery] Trying to connect to API Server "192.168.1.185:6443" [discovery] Created cluster-info discovery client, requesting info from "https://192.168.1.185:6443" [discovery] Requesting info from "https://192.168.1.185:6443" again to validate TLS against the pinned public key [discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server "192.168.1.185:6443" [discovery] Successfully established connection with API Server "192.168.1.185:6443"
安装跨主机网络插件
想要在集群中部署的容器可以跨节点互相通信则需要安装网络插件,kubernetes的网络插件有很多种,我们这里只说两种 calico 和 flannel。
calico
我们这里通过安装网络插件容器的方式来部署, 所使用的是cni网络插件。主要有两个配置文件:rabc-kdd.yaml用来配置权限,而calico.yaml用于配置calico插件:
kubectl apply -f ./rbac-kdd.yaml
kubectl apply -f ./calico.yaml
这里需要提醒大家的是,我们在calico.yaml中有如下配置:
# Auto-detect the BGP IP address.
# value: "autodetect"
- name: IP
value: "autodetect"
- name: IP_AUTODETECTION_METHOD
value: interface=enp1s.*,wlx.*
- name: FELIX_HEALTHENABLED
value: "true"
IP:autodetect 指定了cni插件自动去识别主机的地址,IP_AUTODETECTION_METHOD:interface=enp1s.*,wlx.* 则指定了主机的物理网卡名称(enp1s是有线网卡的前缀、wlx是无线网卡前缀),支持通配符的方式来匹配,所以我们在安装的时候需要注意本地物理网卡的名称自己进行适当的修改。
此外还有如下配置用来划定pod的IP地址范围:
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
注意:要与 kubeadm init 时指定的ip范围一致。
部署成功后我们可以查看当前在线节点:
NAME STATUS ROLES AGE VERSION
whty0-to-be-filled-by-o-e-m Ready master 2h v1.10.7
whtyhust-to-be-filled-by-o-e-m Ready <none> 1h v1.10.7
flannel
与calico相同,我们flannel也使用同样的方式来部署,只要按照以下步骤执行即可:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
注意: 需要kubernetes的版本在1.7以上才行,此外在 flannel.yml中有如下配置:
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
此处Network的地址范围要与 kubeadm init 时指定的范围一致。
允许在master node 上创建资源(Optional)
在master node 上执行
kubectl taint nodes --all node-role.kubernetes.io/master-
显示结果如下:
taint "node-role.kubernetes.io/master:" not found
taint "node-role.kubernetes.io/master:" not found
执行以上命令后,在部署 k8s资源时 master node会像 worker node一样被对待,否则默认不会在master节点上部署 k8s 资源
kudeadm token 生成
在我们安装了kubernetes集群后可能过一段时间需要添加一个节点,当你使用最初的token去加入节点时发现token失效了,这是因为这个token是有时间限制的。只有重新的生成token才能把节点加入,token的生成过程如下:
创建token
kubeadm token create显示结果如下:
[kubeadm] WARNING: starting in 1.8, tokens expire after 24 hours by default (if you require a non-expiring token use --ttl 0) aa78f6.8b4cafc8ed26c34f此处的aa78f6.8b4cafc8ed26c34f 就是新生成的token。
获取api server ca 证书的hash
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'显示结果如下:
0fd95a9bc67a7bf0ef42da968a0d55d92e52898ec37c971bd77ee501d845b538加入新节点:
kubeadm join --token aa78f6.8b4cafc8ed26c34f --discovery-token-ca-cert-hash sha256:0fd95a9bc67a7bf0ef42da968a0d55d92e52898ec37c971bd77ee501d845b538 172.16.6.79:6443
其它
不同的网络插件实现的机制不一致,其中flannel+vxlan的方式比较流行,我们需要后续的研究和比较,哪种类型的插件更加高效。比如在作者实际的工作过程中,遇到过以下问题:
使用kubernetes搭建fabric-kafka分布式服务,在使用calcio时kafka服务的zookeeper节点之间频繁链接超时,即使修改了超时等待时间仍然无法解决问题,但在同样的环境中,使用了flannel+vxlan插件之后zookeeper之间可以稳定的链接。
此外,当使用flannel+vxlan后有可能在创建pod的过程中遇到如下问题:
network: failed to set bridge addr: "cni0" already has an IP address different from 10.244.1.1/24"
这是因为在反复安装kubernetes过程中cni的历史数据并没有清除干净,这个问题在后续版本中已经被修复,但在1.10.7版本中仍然存在这个问题,可以通过执行以下命令来彻底清除cni历史数据:
#!/bin/sh
kubeadm reset
systemctl stop kubelet
systemctl stop docker
rm -rf /var/lib/cni/
rm -rf /var/lib/kubelet/*
rm -rf /etc/cni/
ifconfig cni0 down
ifconfig flannel.1 down
ifconfig docker0 down
ip link delete cni0
ip link delete flannel.1
systemctl start kubelet
systemctl start docker
参考网址:
- kubeadm: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/
- token 配置: https://segmentfault.com/a/1190000011986560
- kubernetes reset bug 修复: https://github.com/oonisim/kubernetes-installation/commit/7b1158da1dd9097a45b3b200cd1acd0c1f56aa76
- join token的生成 https://blog.csdn.net/mailjoin/article/details/79686934