摘要:
little tricks Littletricksbitlocker用hashcat解密了010编辑器。在查看了vhdx磁盘后,它被安装到了wink上,并发现在Bitlocker尝试加密后,某些软件无法正常工作。我仍然使用hashcat作为johntheriper的下载地址https://www.openwall.com/john/在运行中查找bitlocker2john.exebitlocker2john.exe-ill2.vhdx以生成四个h
bitlocker用hashcat解密
010editor看了下是vhdx磁盘,挂载到win发现被bitlocker加密
尝试了一些软件都不好使,还是用hashcat做
john the ripper下载地址
在run里找到bitlocker2john.exe
bitlocker2john.exe -i ll2.vhdx
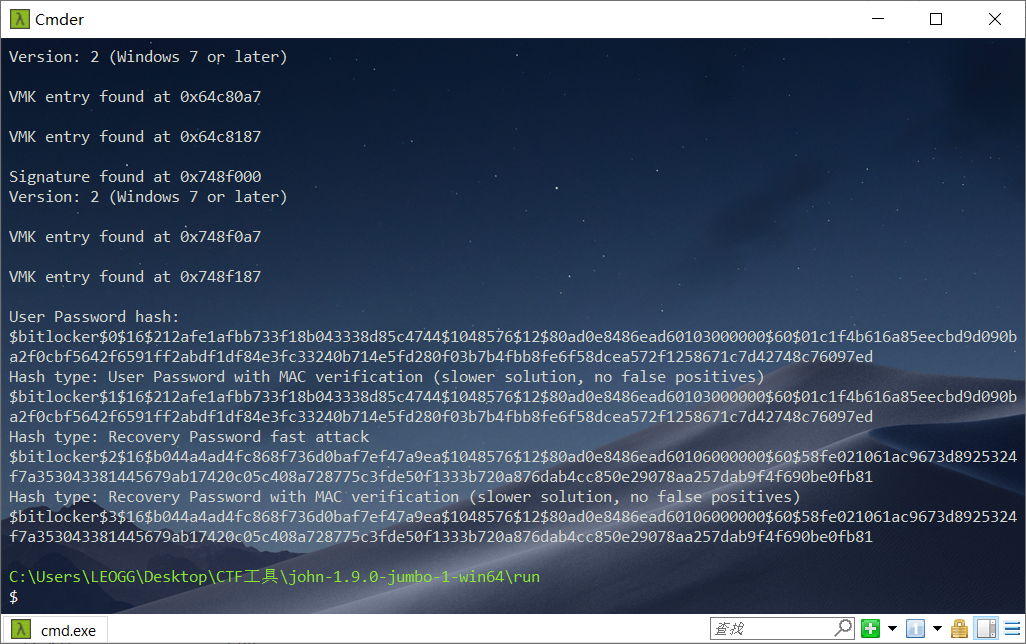
生成了四个hash,先保存下来
User Password hash:
$bitlocker$0$16$212afe1afbb733f18b043338d85c4744$1048576$12$80ad0e8486ead60103000000$60$01c1f4b616a85eecbd9d090ba2f0cbf5642f6591ff2abdf1df84e3fc33240b714e5fd280f03b7b4fbb8fe6f58dcea572f1258671c7d42748c76097ed
Hash type: User Password with MAC verification (slower solution, no false positives)
$bitlocker$1$16$212afe1afbb733f18b043338d85c4744$1048576$12$80ad0e8486ead60103000000$60$01c1f4b616a85eecbd9d090ba2f0cbf5642f6591ff2abdf1df84e3fc33240b714e5fd280f03b7b4fbb8fe6f58dcea572f1258671c7d42748c76097ed
Hash type: Recovery Password fast attack
$bitlocker$2$16$b044a4ad4fc868f736d0baf7ef47a9ea$1048576$12$80ad0e8486ead60106000000$60$58fe021061ac9673d8925324f7a353043381445679ab17420c05c408a728775c3fde50f1333b720a876dab4cc850e29078aa257dab9f4f690be0fb81
Hash type: Recovery Password with MAC verification (slower solution, no false positives)
$bitlocker$3$16$b044a4ad4fc868f736d0baf7ef47a9ea$1048576$12$80ad0e8486ead60106000000$60$58fe021061ac9673d8925324f7a353043381445679ab17420c05c408a728775c3fde50f1333b720a876dab4cc850e29078aa257dab9f4f690be0fb81

找一下bitlocker对应哈希类型
hashcat --help

用个工具里带的字典,感谢th31nk师傅
hashcat -m 22100 common_8k.txt
跑出结果后加--show查看

得到密码12345678
这边看了盖乐希师傅的博客,说用第二种进行,我这边尝试了第一种hash也是可以的(还发现了jtr自带的字典)

第三种和第四种,hashcat会识别不了
取证
用diskgenius在回收站里找到两个pdf,打开较大的那个就可以看到
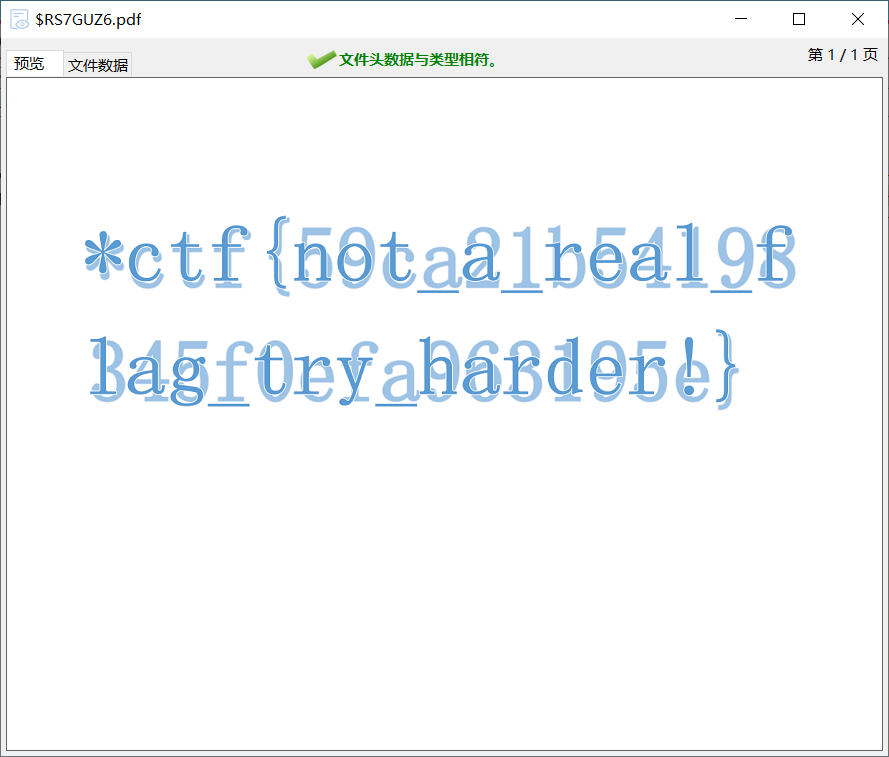
gaps尝试了一下,试了很多参数发现拼不出来
google了一下原图,想到DDCTF的拼图技巧,把给的图片切片一下和原图进行对比

上次DDCTF大师傅们的脚本利用一下
import cv2
from PIL import Image
import numpy as np
import os
import shutil
import threading
# 读取目标图片(原图)
source = cv2.imread(r"C:UsersLEOGGDesktopwallpaper.jpg")
# 拼接结果
target = Image.fromarray(np.zeros(source.shape, np.uint8))
# 图库目录(切片后的1100张图片)
dirs_path = r"C:UsersLEOGGDesktop est est"
# 差异图片存放目录(跑的时候生成的图片)
dst_path = r"C:UsersLEOGGDesktopdddiff"
def match(temp_file):
# 读取模板图片
template = cv2.imread(temp_file)
# 获得模板图片的高宽尺寸
theight, twidth = template.shape[:2]
# 执行模板匹配,采用的匹配方式cv2.TM_SQDIFF_NORMED
result = cv2.matchTemplate(source, template, cv2.TM_SQDIFF_NORMED)
# 归一化处理
cv2.normalize(result, result, 0, 1, cv2.NORM_MINMAX, -1)
# 寻找矩阵(一维数组当做向量,用Mat定义)中的最大值和最小值的匹配结果及其位置
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
target.paste(Image.fromarray(template), min_loc)
return abs(min_val)
class MThread(threading.Thread):
def __init__(self, file_name):
threading.Thread.__init__(self)
self.file_name = file_name
def run(self):
real_path = os.path.join(dirs_path, k)
rect = match(real_path)
if rect > 6e-10:
print(rect)
shutil.copy(real_path, dst_path)
count = 0
dirs = os.listdir(dirs_path)
threads = []
for k in dirs:
if k.endswith('jpg'):
count += 1
print("processing on pic" + str(count))
mt = MThread(k)
mt.start()
threads.append(mt)
else:
continue
# 等待所有线程完成
for t in threads:
t.join()
target.show()
# 跑出来后的图片
target.save(r"C:UsersLEOGGDesktopdd.jpg")

flag{you_can_never_finish_the}