
云妹导读:
在《会展云技术解读》专题中,我们已经推出了安全篇与设计篇,分别介绍了如何应对云上会展最严保障要求与线上展览中基于服务设计的方法,本篇文章云妹将继续为大家带来会展云中非常重要的一环——智能推荐系统。
在如今的互联网产品中智能推荐可谓无处不在,它可以根据用户每个人的性别、年龄、爱好等维度塑造静态用户画像,和用户每一次点击、点赞、评论、收藏等行为数据形成的动态用户画像相结合,来结合挖掘用户深层次兴趣需求维度。
我们常见的有新闻推荐和电商场景的商品推荐,展会场景推荐系统与之不同的是,它需要满足参展商、采购商和个人用户各方需求,尤其是像前不久举办的永不落幕的云上服贸会,首次采用线上+线下结合的模式,将服贸会影响辐射周期从集中的一周拉长至一整年,参展商、采购商以及正在寻找商机有需求的个人用户都可以随时随地浏览云上服贸会寻找有价值的商机。
服贸会注册展商近万家,涉及展品数量庞大,涉及200多个子行业。如何让线上用户从大量的展商信息中快速找到自己想要的商机?如何保持有效商机的持续获取?这些问题是提升观展体验和逛展效率的关键行动。在这个过程中,京东智联云机器学习团队承担了云上服贸会智能推荐功能的开发。

从上图可以看到,整个服贸会智能推荐系统包括四个模块的功能,同时服务官网2D店铺和手机APP端,可以做到用户级别的个性化推荐。针对服贸会的展商、展台、展品、项目四项重要信息,智能推荐系统有对应的展商推荐、展台推荐、展品推荐和项目发布推荐四个模块。
其中,展商、展台和展品推荐三个模块的功能引入了采购商和个人的用户画像、兴趣标签和行为等维度数据进行精准匹配。比较难实现的是项目发布的推荐,因为除了要考虑用户画像和兴趣标签等维度数据外,考虑到项目的及时性和强目的性,还需要高权重的引入内容维度的数据做推荐。
本次智能推荐功能落地过程中除了对于如何更精准的实现项目发布的推荐外,还有3大难题:
整个云上服贸,智能推荐呈现的内容承载近80%的用户“第一眼”,所以如何在第一时间给用户带来最佳的精准推荐是一个比较棘手的问题。加上本次是第一届云上服贸会,没有历史信息可以使用。怎么做才能最大价值用户的第一时间流量是整个项目期间持续思考的问题;
虽然整个云上服贸会注册参展商不如电商平台的量级大,但是在9月5日-9月9日线下展会期间是同样需要面对高并发和性能的挑战,好的架构系统设计是扛得住检验的坚实防线;
解决了“第一眼”的推荐,如何做好第二眼、第三眼……的推荐,除了做好用户画像,在参展内容刻画的不断探索。
同时,我们也在不断思考:对于“永不落寞的服贸会”如何持续做好后续的推荐?不同于互联网产品新闻推荐和电商场景的商品推荐,展会场景的推荐如何做出满足各方(参展商、采购商和个人用户)需求的推荐之路?

目前市场上面向C端的用户产品如头条、淘宝和各家音乐APP等为了做好推荐过程的冷启动可谓各显神通——通过多途径尽可能地获取数据,比如首次注册的“关联微博/微信/QQ”账户;比如询问用户的偏好和感兴趣内容;比如基础的用户信息收集(性别、年龄、地域和所属行业等)。无论通过被动的信息获取还是主动的用户意向选择,都旨在补全对用户的认知,加上对分发内容精细化粒度的标签特征提取,可以实现冷启动的个性化推荐。
而冷启动推荐的另一个较高的门槛是:对用户场景和行为动机的深层理解,足够的知识库沉淀。
但云上服贸会的智能推荐场景,以上两条路似乎都不怎么好走。由于是首次参与展会类场景的推荐,即使看似推荐的产品和京东的商品相似,有展台和展品的划分,但是用户的群体画像和逛展意图有天壤之别。好在京东智联云长期以来一直赋能于ToB的业务,沉淀了对B端企业采购场景的认知。
尤其在2020年年初的疫情期间,为了给企业和政府提供高效的防疫装备采买,京东智联云推出了“应急资源信息发布平台”。提供采购和发布供需信息的通道的同时,还为平台用户提供了基于供需诉求、地理位置、产品匹配度与数量、生产力和运输效率等多维度的精准推荐。这些沉淀的供需场景知识刚好可以应用于本次云上服贸会的推荐。另一方面,我们对于用户画像和分发内容画像的理解和补全也做了很多功课,最终确保本次云上服贸会智能推荐的功能到成功亮相。

面对高并发下的高性能要求,我们设计了基于Caffeine和Redis的多重缓存架构,接下来将从两个方面来介绍:
1,技术选型
为什么使用Caffeine+Redis?Redis不用多说,大家都太熟悉了。这里重点介绍下Caffeine,Caffeine是一个基于Java8开发的提供了近乎最佳命中率的高性能缓存库。
这里有人又会产生疑问,为什么不用Guava Cache呢?这种大家更熟悉基于LRU(The Least Recently Used)算法实现的本地化缓存难道不好吗?
虽然Guava Cache在过去应用更广泛,性能也还不错,但在日新月异的今天,总是会有更优秀、性能更好的缓存框架出现——就像Caffeine。另外再补充下,从Spring5(SpringBoot2)开始也使用Caffeine来取代Guava Cache。
为什么Caffeine的性能更好?
首先从淘汰算法说起,Guava Cache使用的是LRU。LRU实现比较简单,日常使用时也有着不错的命中率,它可以有效的保护热点数据,但对于偶发或周期性的访问,会导致偶发数据被保留,而真正的热点数据被淘汰,大大降低缓存命中率。为此Caffeine使用了Window TinyLFU算法。
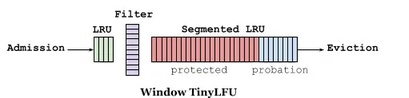
在讲Window TinyLFU前,还需要再简单介绍下LFU。LFU算法解决了LRU对于突发或周期性访问导致真实热点数据淘汰的问题,但短时间对于某些数据的高频访问,会导致这些数据长时间驻留在内存中,进而在触发淘汰时,新加入的热点数据被错误的淘汰掉,最终导致命中率的下降。另外LFU还需要维护访问频次,每次访问都需要更新,造成巨大的资源开销。Window TinyLFU实际上吸取了LRU和LFU的优点,又规避了各自的缺点。
具体做法是:首先Window TinyLFU维护了一个近期访问记录的频次信息,作为一个过滤器,当新记录来时,只有满足TinyLFU要求的记录才可以被插入缓存。为了解决资源的高消耗问题,它通过4-bit CountMinSketch实现,这个算法类似于布隆过滤器,可以用很小的空间来存放大量的访问频次数据。这个设计给予每个数据项积累热度的机会,而不是立即过滤掉。这避免了持续的未命中,特别是在突然流量暴涨的的场景中,一些短暂的重复流量就不会被长期保留。为了刷新历史数据,一个时间衰减进程被周期性或增量的执行,给所有计数器减半。
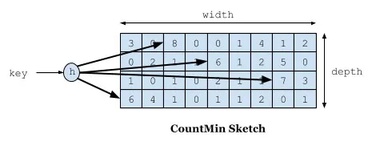
而对于长期保存的数据,W-TinyLFU使用了Segmented LRU(缩写 SLRU)策略。在初始阶段,一个数据项会被存储在probationary segment中,在后续被访问时,它会被移到protected segment中。当protected segment内存不够时,有的数据会被淘汰回probationary segment,这也可能再次触发probationary segment的淘汰。这套机制确保了访问间隔小的热点数据被保存,而重复访问少的冷数据则被回收。
除此以外,在caffeine中读写都是通过异步操作,将事件提交至队列实现的,而队列的数据结构使用的是RingBuffer(高性能无锁队列Disruptor用的就是RingBuffer),所有的写操作共享同一个RingBuffer;而读取时,这块的设计思想是类似于Striped64,每一个读线程对应一个RingBuffer,从而避免竞争。
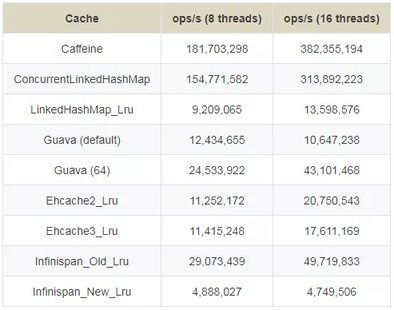
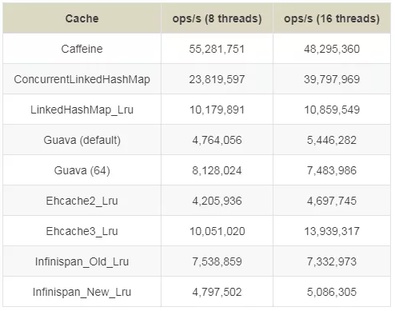
下面是官方性能测试对比:
1、读(100%)
2、读 (75%) / 写 (25%)
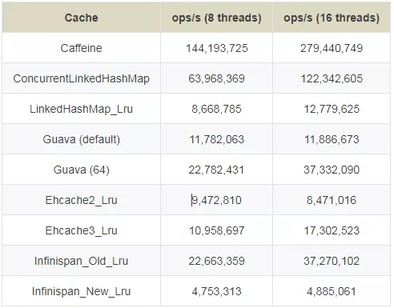
3、写 (100%)
2,多级缓存设计
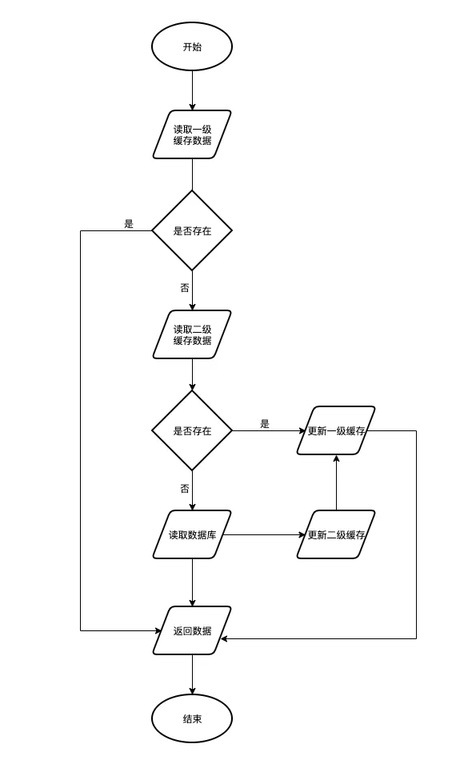
Redis作为常用的缓存,虽然性能非常优秀,但随着数据量的增长,数据结构的复杂,在叠加高并发场景时,不管是网络IO的消耗,还是Redis单节点的瓶颈,都会对整个调用链的性能造成不可忽视的影响。所以我们既需要Caffeine作为JVM级别的缓存,也需要Redis作为我们的二级缓存,这种多级的缓存设计才能最终满足我们的需要。
在Java世界中,我们最常用的就是基于Spring Cache来实现应用缓存,但Spring Cache仅支持单一缓存来源,并无法满足多级缓存的场景。因此我们需要通过实现CacheManager接口来定义自己的多级缓存CacheManager,同时还需要实现自己的Cache类(继承AbstractValueAdaptingCache),在这里面将CaffeineCache和RedisTemplate类以及相关的一些策略配置注入进去,这样我们就可以自己实现想要的get、put方法:多级缓存的读和写。
在数据一致性的设计上,这块主要依赖于Redis的发布订阅模式,也就是将所有的更新、删除都通过该模式通知其他节点去清理本地缓存,当然因为CAP的关系,这种设计是无法保证数据的强一致性的,所以我们也只能尽可能的去保证数据的最终一致性。

在会展云中,我们采用了用户画像、信息画像、关键词匹配等技术实现个性化推荐。其中,用户画像是通过用户的注册信息、兴趣标签、浏览偏好等数据进行构建。信息画像包括了展商画像、展台画像、展品画像和项目画像四部分,前三部分各自构建又互相利用了对方的信息,如展商的收藏、浏览等数据会添加该企业对应展台和展品的数据,展品的行业信息需要从展商画像中获取,三部分数据融合建模,从而构建了更加丰富的画像。
关键词匹配技术主要应用于行业名称和交易类型关键词的匹配,通过该技术可以将不标准的信息规范化。该系统还针对冷启动场景进行了优化,当用户和信息数据不足时,系统可以根据仅有的用户注册信息和参展商的行业信息进行匹配,并考虑信息的热度进行排序。
本次服贸会实现了对数十万用户提供个性化推荐服务,针对新注册的用户和新发布的信息也可以通过冷启动方案快速实现智能推荐。推荐系统采用了通用的召回和排序架构,召回部分将采用协同过滤、矩阵分解等模型,可以快速从海量数据中粗筛出候选集;排序部分采用更复杂且准确率较高的深度学习模型,如业界常用的Wide&Deep、DeepFM等先进模型,实现对候选集每个信息的精准排序,为服贸会的用户和参展商提供准确和稳定的服务。
在模型选择上,我们使用DIN(Deep Interest Network)模型。在正式介绍模型之前,先来介绍一下Attention机制。
Attention机制是模仿人类注意力而提出的一种解决问题的办法,简单地说就是从大量信息中快速筛选出高价值信息,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。
例如人的视觉在处理一张图片时,会通过快速扫描全局图像,获得需要重点关注的目标区域,也就是注意力焦点。然后对这一区域投入更多的注意力资源,以获得更多所需要关注的目标的细节信息,并抑制其它无用信息。图1中对Attention机制进行了图示,其中亮白色区域表示更关注的区域。

▲图1 注意力机制直观展示图▲
Attention机制的具体计算过程见图2。对目前大多数Attention方法进行抽象,可以将其归纳为两个过程、三个阶段:
第一个过程是根据query和key计算权重系数:
(1)第一个阶段根据query和key计算两者的相似性或者相关性;
(2)第二个阶段对第一阶段的原始分值进行归一化处理。
第二个过程根据权重系数对value进行加权求和:
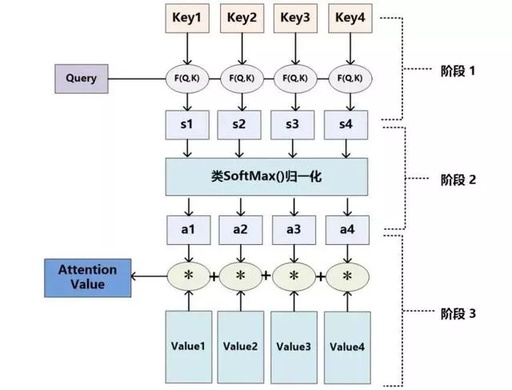
▲图2 三阶段计算Attention过程▲
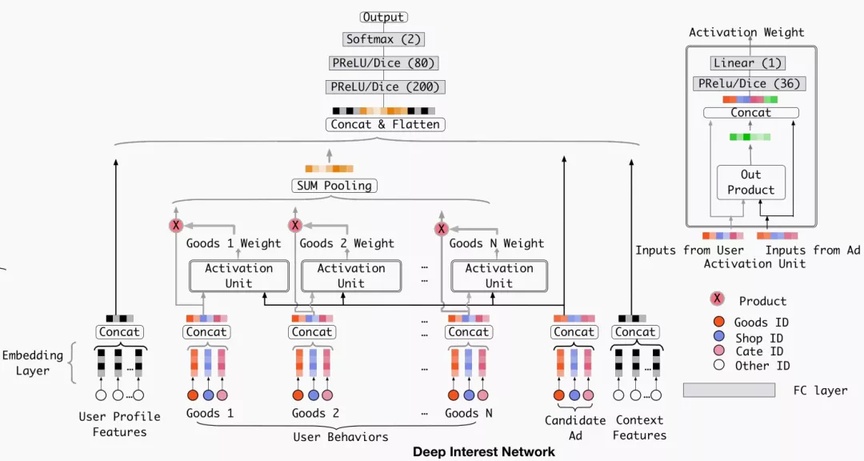
利用候选参展商品和用户历史行为之间的相关性计算出一个权重,这个权重就代表了“注意力”的强弱。DIN设计了局部激活单元,激活单元会计算候选参展商品与用户最近N个历史行为商品的相关性权重,然后将其作为加权系数对N个行为商品的embedding向量做sum pooling。
用户的兴趣由加权后的embedding来体现。权重是根据候选参展商品和历史行为共同决定的,同一候选商品对不同用户历史行为的影响是不同的,与候选商品相关性高的历史行为会获得更高的权重。可以看到,激活单元是一个多层网络,输入为用户画像embedding向量、信息画像embedding向量以及二者的叉乘。
DIN模型大致分为以下五个部分:
Embedding Layer:原始数据是高维且稀疏的0-1矩阵,emdedding层用于将原始高维数据压缩成低维矩阵;
Pooling Layer :由于不同的用户有不同个数的行为数据,导致embedding矩阵的向量大小不一致,而全连接层只能处理固定维度的数据,因此利用Pooling Layer得到一个固定长度的向量;
Concat Layer:经过embedding layer和pooling layer后,原始稀疏特征被转换成多个固定长度的用户兴趣的抽象表示向量,然后利用concat layer聚合抽象表示向量,输出该用户兴趣的唯一抽象表示向量;
MLP:将concat layer输出的抽象表示向量作为MLP的输入,自动学习数据之间的交叉特征;
Loss:损失函数一般采用Logloss;
DIN认为用户的兴趣不是一个点,而是一个多峰的函数。一个峰就表示一个兴趣,峰值的大小表示兴趣强度。那么针对不同的候选参展商品,用户的兴趣强度是不同的,也就是说随着候选商品的变化,用户的兴趣强度不断在变化。
总的来说,DIN通过引入attention机制,针对不同的商品构造不同的用户抽象表示,从而实现了在数据维度一定的情况下,更精准地捕捉用户当前的兴趣。
以上,是我们为本次服贸会智能推荐板块提供的技术支持和思考,本次服贸会作为首届“永不落幕”服贸会,同样,我们在技术之路的深耕和追逐的脚步一刻也不敢懈怠,不断思考持续探索,不忘初心未来可期。
推荐阅读:
欢迎点击【京东智联云】,了解京东会展云服务
更多精彩技术实践与独家干货解析
欢迎关注【京东智联云开发者】公众号
