14日凌晨,B站发布消息称:
昨晚,B站的部分服务器机房发生故障,造成无法访问。技术团队随即进行了问题排查和修复,现在服务已经陆续恢复正常。耽误大家看视频了,对不起!
已知:
- Bilibili,Acfun,豆瓣都出现崩溃404.
- 豆瓣和Acfun很快恢复,Bilibili大约用了一个小时让用户能够正常访问。
- Bilibili直播是可以正常观看的,朋友看吃鸡直播没有受到影响。
- B站高可用用架构实践 - 云+社区 - 腾讯云 (tencent.com)
- 根据上面文章可知,Bilibili的LB(负载均衡器)是自研的,一系列为了高可用配套的服务和中间件都是自研的。
- 在逐渐可以访问主站时,推荐系统并没有推荐正常的视频给用户。
看知乎余歌[1]分析说:
a. Bilibili、Acfun、豆瓣等的云服务供应商出现了问题。但是不清楚CDN出现问题还是挂载着容器的机器出问题
假设是容器出现问题,一个工作正常的LB会访问其他可用的容器。在这种情况下很难出现昨天的问题,毕竟Bilibili这么大一公司也不会把鸡蛋放在一个篮子里,肯定是异地多机房容灾。而且Bilibili这种大型视频网站,读请求和读流量肯定大部分走的都是CDN和缓存,发生这种情况的概率要小很多,另一种情况的概率很大。
那么另一种可能是CDN出现了问题,假设CDN出现了问题,大量读请求发送到CDN,由于供应商出现意外,请求无法在CDN上找到资源,大量请求回源到Bilibili主站。这是一个比较合理的情况。
进行了一个猜测。7 / 14 Bilibili出现问题的整体流程可能如下:
1. 云服务供应商出现意外,大量请求绕过CDN直接打到应用网关,多家互联网公司的主站发生无法访问的现象。
2.1 豆瓣,Acfun等公司的运维收到告警,紧急切换了CDN,或启动了容灾策略进行降流,系统正常对外提供服务。
2.2 Bilibili同样收到告警,启动了容灾策略,但是当时正是Bilibili流量高峰期,有两个可能:
2.2.1 自研的LB没办法处理这么多请求,直接崩了
但是如果LB崩了,只需要切换CDN并且重启LB就可以成功继续对外服务了,对于Bilibili来说这个概率要小一些。
2.2.2 自研的降流有问题,导致大量请求发送到后续底层服务,服务雪崩,整个环境炸了。
结合上述提到的事实,我个人认为服务雪崩的概率要更大一些。现代的微服务系统是一个相当庞大的系统,当整个系统出现问题时,重启需要的时间是相当大的。评论区有说到k8s重启很快,针对单个容器的启动确实很快,Bilibili这么大一公司,一整个后端系统至少要重启几十上百个不同的容器才能才能一定程度上对外保持服务,这些容器也要好几百甚至上千个副本才能正常扛下高峰期流量。结合Bilibili成功访问经过的时间,我认为这样的流程是相对合理的。结合事实[2]和[5],佐证了Bilibili的运维按照优先级重启了各个容器组,Bilibili的服务正在逐渐恢复。
总的来说主要就删库跑路、单个微服务拖垮大集群、服务器厂商着火、被蒙古上单刺杀几种情况。删库跑路现在的运维基本都分级操作,一般不会给这样的权限,几乎排除。上海服务器着火也被上海消防排除,并未发现火情。蒙古上单一直没有回应,排除。所以极大可能是单个微服务拖垮大集群,也就是上面博主分析的那样。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tl54BBWI-1626315215563)![(C:/Users/win10/AppData/Local/Temp/enhtmlclip/Image.png)]](https://img-blog.csdnimg.cn/20210715101427351.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2tuaWdodDc3NjU=,size_16,color_FFFFFF,t_70)
以及,b站高可用架构实践的Q&A:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QUxpHCp8-1626315215576)(C:/Users/win10/AppData/Local/Temp/enhtmlclip/Image(1)].png)
具体原因还是等后续公布吧,咱来对上述技术点,我们进行部分学习回顾。
对于b站 a站这种,核心技术点如下:
视频访问存储
- 流
- 就近节点
- 视频编解码
- 断点续传(跟我们写的io例子差多)
- 数据库系统&文件系统隔离
并发访问
- 流媒体服务器(各大厂商都有,带宽成本较大)
- 数据集群,分布式存储、缓存
- CDN内容分发
- 负载均衡搜索引擎(分片)
弹幕系统
- 并发、线程
- kafka
- nio框架(netty)
其实跟我们大家学的技术都差不多,大部分技术体系差不多,不过语言应该是go为主,前端框架vue,node为主。
此次事故中出现的热点名词大致如下:CDN,降级,熔断,分布式存储,备份回滚数据等等。下面对主要关键词进行解析:
先来看下什么是CDN。
CDN全称:content Delivery Network ;内容分发网络, 是建立并覆盖在承载网之上,由分布在不同区域的边缘节点服务器群组成的分布式网络。在用户访问高峰期,图片、音视频内容大批量发生变化,大量用户的访问就会穿透cdn,对源站造成巨大的压力。
就淘宝而言, 图片的访问链路有三级缓存(客户端本地、CDN L1、CDN L2),所有图片都持久化的存储到OSS中。[3]
这样会带来2个问题:
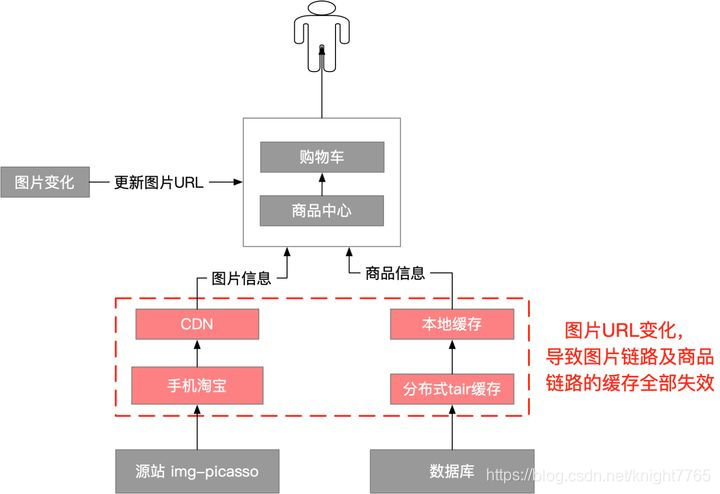
(1)CDN及手机淘宝原本缓存的图片内容失效了,用户访问图片会全部回源到img-picasso。
(2)由于更改了商品的字段,交易的核心应用(购物车和商品中心)的缓存也失效了,用户浏览及购物时,对商品的访问会走到db。源站img-picasso处理图片,以及查询商品DB,都是非常消耗资源的。CDN及商品的缓存命中率降低后,对源站img-picsasso以及db会产生巨大的压力。
拿CDN缓存为例,简单计算一下,CDN平时的命中率是98%,假设命中率降低1个点,对源站的压力就会增加1/3(原本承担2%的流量,现在需要承担3%的流量),意味着img-picasso需要扩容1/3。如果全网一半的图片都同时变化,cdn的命中率降到50%,对img-picasso的访问量就会增加25倍,这个扩容成本肯定没法接受。
服务雪崩
如图所示,一个服务失败,导致整条链路服务都崩溃,称为服务雪崩。[2]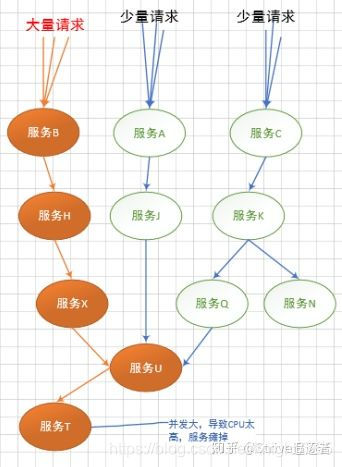
当你频繁更换图片时,
解决灾难性雪崩效应的方式:
1.降级
超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据。
服务降级有很多种降级方式!如开关降级、限流降级、熔断降级!
服务熔断属于降级方式的一种!
撇开框架,以最简单的代码来说明!上游代码如下
try{//调用下游的helloWorld服务xxRpc.helloWorld();}catch(Exception e){//因为熔断,所以调不通doSomething();}
注意看,下游的helloWorld服务因为熔断而调不通。此时上游服务就会进入catch里头的代码块,那么catch里头执行的逻辑,你就可以理解为降级逻辑!
服务降级大多是属于一种业务级别的处理。当然,我这里要讲的是另一种降级方式,也就是开关降级 !
这也是我们生产上常用的另一种降级方式!做法很简单,做个开关,然后将开关放配置中心!在配置中心更改开关,决定哪些服务进行降级。至于配置变动后,应用怎么监控到配置发生了变动,这就不是本文该讨论的范围。
那么,在应用程序中部下开关的这个过程,业内也有一个名词,称为埋点!
那接下来最关键的一个问题,哪些业务需要埋点?
一般有以下方法
(1)简化执行流程自己梳理出核心业务流程和非核心业务流程。然后在非核心业务流程上加上开关,一旦发现系统扛不住,关掉开关,结束这些次要流程。
(2)关闭次要功能一个微服务下肯定有很多功能,那自己区分出主要功能和次要功能。然后次要功能加上开关,需要降级的时候,把次要功能关了吧!
(3)降低一致性假设,你在业务上发现执行流程没法简化了,愁啊!也没啥次要功能可以关了,桑心啊!那只能降低一致性了,即将核心业务流程的同步改异步,将强一致性改最终一致性!
2.隔离(线程池隔离和信号量隔离)限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用。
3.熔断当失败率(如因网络故障/超时造成的失败率高)达到阀值自动触发降级,熔断器触发的快速失败会进行快速恢复。服务熔断:当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用
4.降级熔断当Service A调用Service B,失败多次达到一定阀值,Service A不会再去调Service B,而会去执行本地的降级方法!对于这么一套机制:在Spring cloud中结合Hystrix,将其称为熔断降级!与服务降级区别不同。
最后不管怎样,都要祝B站越办越好咯!b站崩了,知乎热榜第一,微博热榜第一,不愧是年轻人聚集的地方,bilibili,干杯!