摘要:
当使用Scrapy开发爬虫时,通常需要创建一个Scrapy项目。除了提供startproject子命令外,sketch还提供常用的子命令,如fetch、genspider、shell和version。智品蜘蛛/管道。py:项目的管道文件,负责处理爬行的信息。ZhipinSpider/设置。py:项目的配置文件。您可以在此文件中配置项目。为了更好地理解报废项目中每个组件的作用,下面给出了报废的概述,如图1所示。蜘蛛提取的信息将通过报废引擎以Item对象的形式传输到Pipeline。根据上述分析,使用Scrapy开发网络爬虫主要是开发两个组件,蜘蛛和管道。
在使用Scrapy开发爬虫时,通常需要创建一个Scrapy项目。通过如下命令即可创建 Scrapy 项目:
scrapy startproject ZhipinSpider
在上面命令中,scrapy 是Scrapy 框架提供的命令;startproject 是 scrapy 的子命令,专门用于创建项目;ZhipinSpider 就是要创建的项目名。
scrapy 除提供 startproject 子命令之外,它还提供了 fetch(从指定 URL 获取响应)、genspider(生成蜘蛛)、shell(启动交互式控制台)、version(查看 Scrapy 版本)等常用的子命令。可以直接输入 scrapy 来查看该命令所支持的全部子命令。
1、运行上面命令,将会看到如下输出结果(正常):


New Scrapy project 'ZhipinSpider', using template directory 'd:python3.6libsite-packagesscrapy emplatesproject', created in: C:UsersmengmahipinSpider You can start your first spider with: cd ZhipinSpider scrapy genspider example example.com
上面信息显示 Scrapy 在当前目录下创建了一个 ZhipinSpider 项目,此时在当前目录下就可以看到一个 ZhipinSpider 目录,该目录就代表 ZhipinSpider 项目。
2、运行上面命令,将会看到如下输出结果(异常):
Fatal error in launcher: Unable to create process using '"'
解决方法:
python -m scrapy startproject XXXX
查看 ZhipinSpider 项目,可以看到如下文件结构:
ZhipinSpider
│ scrapy.cfg
│
└──ZhipinSpider
│ item.py
│ middlewares.py
│ pipelines.py
│ setting.py
│
├─ spiders
│ │ __init__.py
│ │
│ └─ __pycache__
└─ __pycache__下面大致介绍这些目录和文件的作用:
- scrapy.cfg:项目的总配置文件,通常无须修改。
- ZhipinSpider:项目的 Python 模块,程序将从此处导入 Python 代码。
- ZhipinSpider/items.py:用于定义项目用到的 Item 类。Item 类就是一个 DTO(数据传输对象),通常就是定义 N 个属性,该类需要由开发者来定义。
- ZhipinSpider/pipelines.py:项目的管道文件,它负责处理爬取到的信息。该文件需要由开发者编写。
- ZhipinSpider/settings.py:项目的配置文件,在该文件中进行项目相关配置。
- ZhipinSpider/spiders:在该目录下存放项目所需的蜘蛛,蜘蛛负责抓取项目感兴趣的信息。
为了更好地理解 Scrapy 项目中各组件的作用,下面给出 Scrapy 概览图,如图 1 所示。
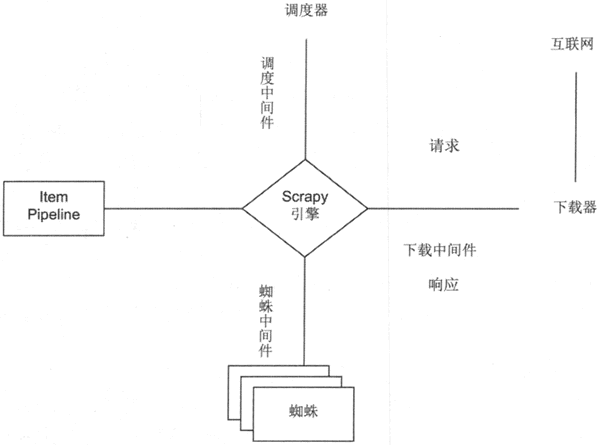
图 1 Scrapy 概览图
在图 1 中可以看到,Scrapy 包含如下核心组件:
- 调度器:该组件由 Scrapy 框架实现,它负责调用下载中间件从网络上下载资源。
- 下载器:该组件由 Scrapy 框架实现,它负责从网络上下载数据,下载得到的数据会由 Scrapy 引擎自动交给蜘蛛。
- 蜘蛛:该组件由开发者实现,蜘蛛负责从下载数据中提取有效信息。蜘蛛提取到的信息会由 Scrapy 引擎以 Item 对象的形式转交给 Pipeline。
- Pipeline:该组件由开发者实现,该组件接收到 Item 对象(包含蜘蛛提取的信息)后,可以将这些信息写入文件或数据库中。
经过上面分析可知,使用 Scrapy 开发网络爬虫主要就是开发两个组件,蜘蛛和 Pipeline。