摘要:
如上所述,继续使用ik分析器声明ik _智能分词模式被用作分词器的分析器。冲突=继续。结论到目前为止,同义词搜索已经完成。稍后,我们将继续引入其他附加功能,例如拼音搜索和突出显示搜索结果。
一、前言
上篇介绍了 ES 的基础搜索,能满足我们基本的需求,然而在实际使用中还可能希望搜索「番茄」能将包含「西红柿」的结果也罗列出来,本篇将介绍如何实现同义词之间的搜索。
二、安装 ES 同义词插件
2.1 同义词插件简介
GitHub 地址:https://github.com/ginobefun/elasticsearch-dynamic-synonym
定时从 MySQL 中获取自定义词库,支持「扩展词」及「停用词」
2.2 安装步骤
参考 GitHub 中的项目说明
三、自定义分析器
要使用「同义词插件」需要在创建索引时使用「自定义模板」并在自定义模板中「自定义分析器」。
3.1 相关概念
① 字符过滤器(character filter)
② 分词器(tokenizer)
③ 词过滤器(token filter)
自定义分析器官方文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/custom-analyzers.html
3.2 具体配置
① 在上篇新建的「 yb_knowledge.json 」模板中修改「 setting 」配置,往其中添加自定义分析器
"analysis": {
"filter": {
"synonym_filter": {
"type": "dynamic-synonym",
"expand": true,
"ignore_case": true,
"interval": 30,
"tokenizer": "ik_max_word",
"db_url": "jdbc:mysql://localhost:3306/elasticsearch?user=es_user&password=es_pwd&useUnicode=true&characterEncoding=UTF8"
}
},
"analyzer": {
"ik_synonym_max": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": [
"synonym_filter"
]
},
"ik_synonym_smart": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": [
"synonym_filter"
]
}
}
}
自定义分析器说明:
- 首先声明一个新「 token filter 」—— 「 synonym_filter 」,其中 type 为 dynamic-synonym 即动态同义词插件, interval 为 定时同步频率(单位为秒), db_url 为词库的数据库地址。
- 其次声明一个新 「analyzer」—— 「ik_synonym_max」,其中 type 为 custom 即自定义类型, tokenizer 为 ik_max_word 即使用 ik 分析器的 ik_max_word 分词模式, filter 为要使用的词过滤器,可以使用多个,这里使用了上述定义的 synonym_filter 。
- 同上继续声明一个以 ik 分析器的 ik_smart 分词模式作为分词器的分析器。
② 与此同时修改「 mappings 」中的 properties 配置,将「 knowledgeTitle 」及「 knowledgeContent 」这两个字段使用的分析器更换为上述自定义的「 ik_synonym_max 」
"mappings": {
"knowledge": {
...省略其余部分...
"properties": {
...省略其余部分...
"knowledgeTitle": {
"type": "text",
"analyzer": "ik_synonym_max"
},
"knowledgeContent": {
"type": "text",
"analyzer": "ik_synonym_max"
}
}
}
}
③ 最后删除先前创建的 yb_knowledge 索引并重启 Logstash
注:重建索引后可以通过「_analyze」测试分词结果
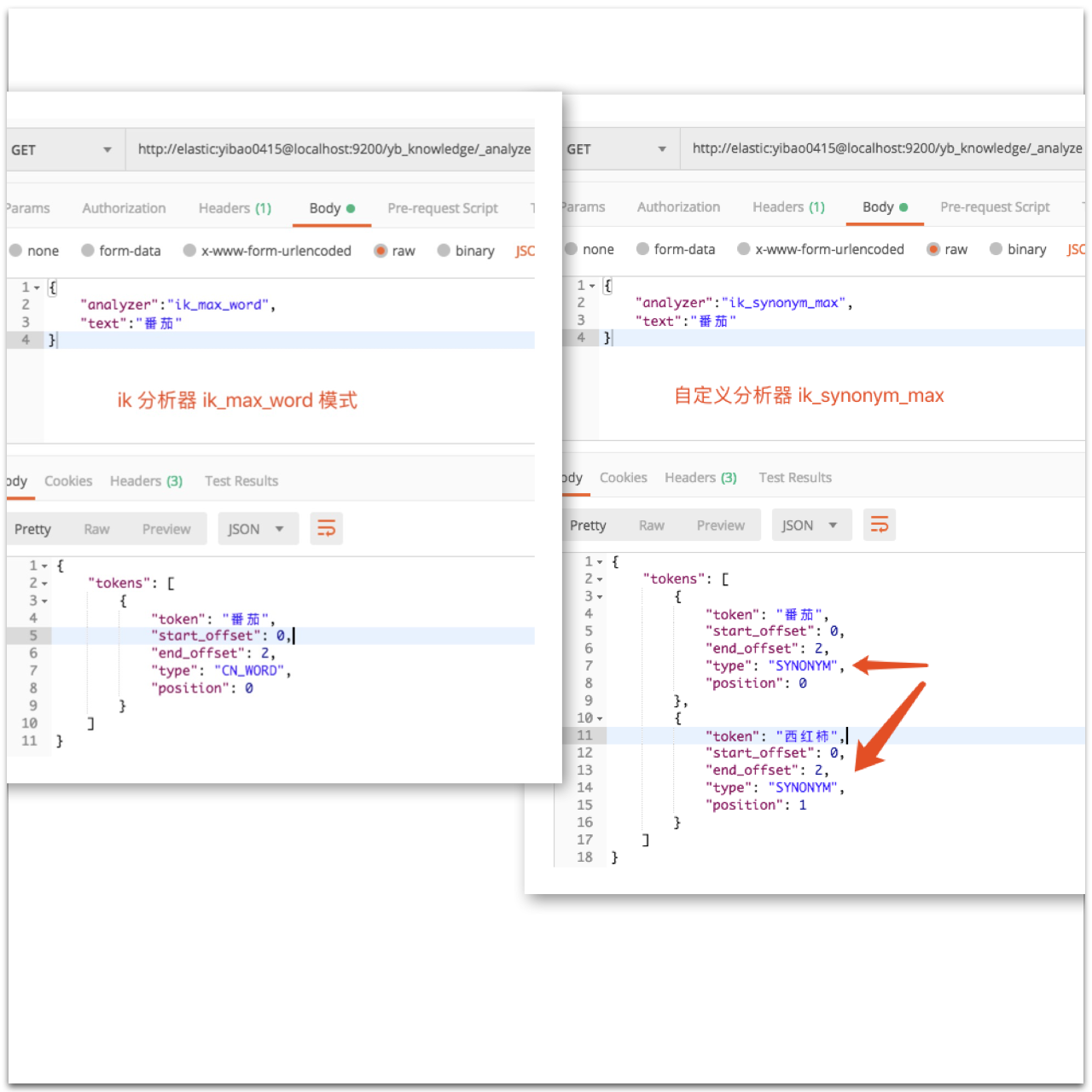
④ 原本在索引中已存在的数据不受同义词动态更新的影响,可以通过以下命令手动更新
curl -XPOST 'http://localhost:9200/yb_knowledge/_update_by_query?conflicts=proceed'
四、结语
至此同义词搜索已经实现完毕,后续将继续介绍其他附加功能,如拼音搜索以及搜索结果高亮等。