正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

------------------------正文开始---------------------------
Hadoop安装:首先到官方下载官网的hadoop2.7.7,链接如下
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
找网盘的hadooponwindows-master.zip
链接如下
https://pan.baidu.com/s/1VdG6PBnYKM91ia0hlhIeHg
把hadoop-2.7.7.tar.gz解压后
使用hadooponwindows-master的bin和etc替换hadoop2.7.7的bin和etc
注意:安装Hadoop2.7.7
官网下载Hadoop2.7.7,安装时注意,最好不要安装到带有空格的路径名下,例如:Programe Files,否则在配置Hadoop的配置文件时会找不到JDK(按相关说法,配置文件中的路径加引号即可解决,但我没测试成功)。
配置HADOOP_HOME
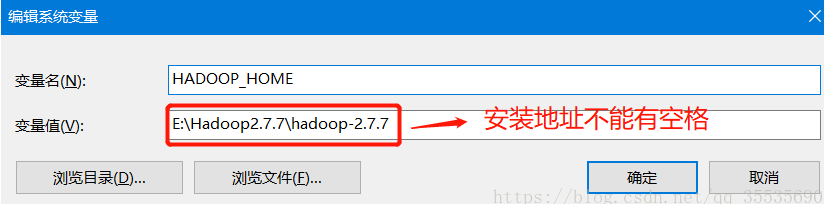
path添加%HADOOP_HOME%in(win10不用分号或者如下编辑界面不用分号,其余加上 ;)
-----------------------------------------------------------配置文件----------------------------
使用编辑器打开E:Hadoop2.7.7hadoop-2.7.7etchadoophadoop-env.cmd
修改JAVA_HOME的路径
把set JAVA_HOME改为jdk的位置
注意其中PROGRA~1代表Program Files
set JAVA_HOME=E:PROGRA~1Javajdk1.8.0_171

打开 hadoop-2.7.7/etc/hadoop/hdfs-site.xml
修改路径为hadoop下的namenode和datanode
dfs.replication
1
dfs.namenode.name.dir
/E:/Hadoop2.7.7/hadoop-2.7.7/data/namenode
dfs.datanode.data.dir
/E:/Hadoop2.7.7/hadoop-2.7.7/data/datanode
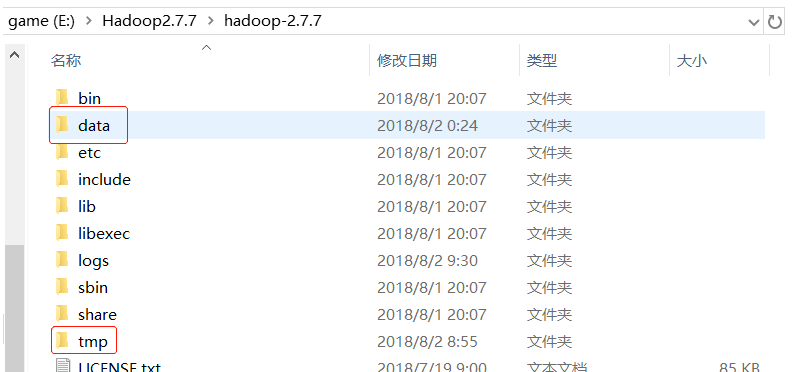
在E:Hadoop-2.7.7目录下 添加tmp文件夹
在E:/Hadoop2.7.7/hadoop-2.7.7/添加data和namenode,datanode子文件夹

还需要把hadoop.dll(从)拷贝到 C:WindowsSystem32
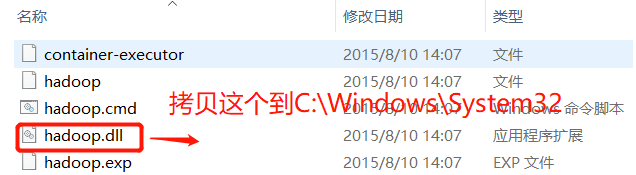
不然在window平台使用MapReduce测试时报错
以管理员身份打开命令提示符
输入hdfs namenode -format,看到seccessfully就说明format成功。
转到Hadoop-2.7.3sbin文件下 输入start-all,启动hadoop集群 ,关闭是 stop-all

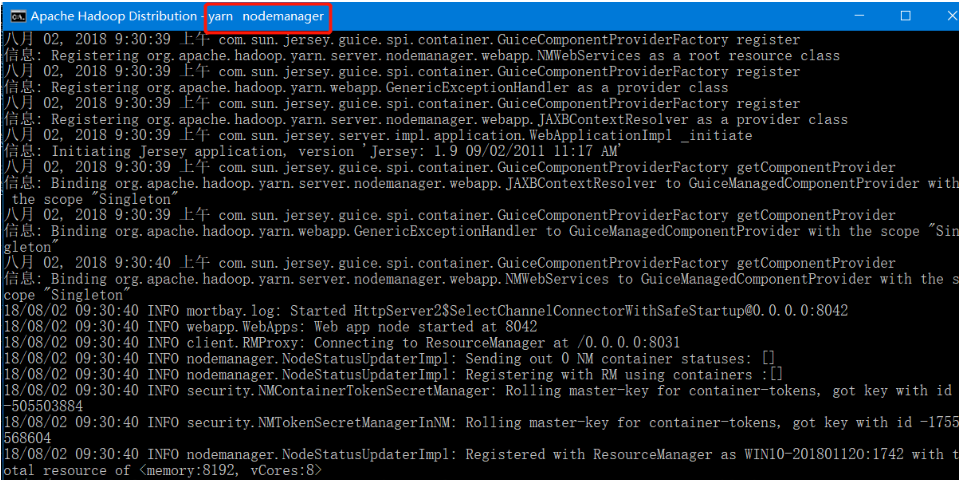
输入jps - 可以查看运行的所有节点
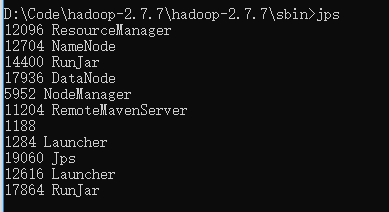
访问http://localhost:50070,访问hadoop的web界面
---------------------------------------------------------------------
hadoop启动后,创建如下的HDFS文件:
D:Codehadoop-2.7.7hadoop-2.7.7sbin>hdfs dfs -mkdir /user
D:Codehadoop-2.7.7hadoop-2.7.7sbin>hdfs dfs -mkdir /user/hive
D:Codehadoop-2.7.7hadoop-2.7.7sbin>hdfs dfs -mkdir /user/hive/warehouse
D:Codehadoop-2.7.7hadoop-2.7.7sbin>hdfs dfs -mkdir /tmp
D:Codehadoop-2.7.7hadoop-2.7.7sbin>hdfs dfs -mkdir /tmp/hive
D:Codehadoop-2.7.7hadoop-2.7.7sbin>hadoop fs -chmod -R 777 /tmp
1.安装hadoop
2.从maven中下载mysql-connector-java-5.1.26-bin.jar(或其他jar版本)放在hive目录下的lib文件夹
3.配置hive环境变量,HIVE_HOME=F:hadoopapache-hive-2.1.1-bin
4.hive配置
hive的配置文件放在$HIVE_HOME/conf下,里面有4个默认的配置文件模板
hive-default.xml.template 默认模板
hive-env.sh.template hive-env.sh默认配置
hive-exec-log4j.properties.template exec默认配置
hive-log4j.properties.template log默认配置
可不做任何修改hive也能运行,默认的配置元数据是存放在Derby数据库里面的,大多数人都不怎么熟悉,我们得改用mysql来存储我们的元数据,以及修改数据存放位置和日志存放位置等使得我们必须配置自己的环境,下面介绍如何配置。
(1)创建配置文件
$HIVE_HOME/conf/hive-default.xml.template -> $HIVE_HOME/conf/hive-site.xml
$HIVE_HOME/conf/hive-env.sh.template -> $HIVE_HOME/conf/hive-env.sh
$HIVE_HOME/conf/hive-exec-log4j.properties.template -> $HIVE_HOME/conf/hive-exec-log4j.properties
$HIVE_HOME/conf/hive-log4j.properties.template -> $HIVE_HOME/conf/hive-log4j.properties
(2)修改 hive-env.sh
export HADOOP_HOME=F:hadoophadoop-2.7.2
export HIVE_CONF_DIR=F:hadoopapache-hive-2.1.1-binconf
export HIVE_AUX_JARS_PATH=F:hadoopapache-hive-2.1.1-binlib
(3)修改 hive-site.xml

1 <!--修改的配置-->
2
3 <property>
4
5 <name>hive.metastore.warehouse.dir</name>
6
7 <!--hive的数据存储目录,指定的位置在hdfs上的目录-->
8
9 <value>/user/hive/warehouse</value>
10
11 <description>location of default database for the warehouse</description>
12
13 </property>
14
15 <property>
16
17 <name>hive.exec.scratchdir</name>
18
19 <!--hive的临时数据目录,指定的位置在hdfs上的目录-->
20
21 <value>/tmp/hive</value>
22
23 <description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
24
25 </property>
26
27 <property>
28
29 <name>hive.exec.local.scratchdir</name>
30
31 <!--本地目录-->
32
33 <value>F:/hadoop/apache-hive-2.1.1-bin/hive/iotmp</value>
34
35 <description>Local scratch space for Hive jobs</description>
36
37 </property>
38
39 <property>
40
41 <name>hive.downloaded.resources.dir</name>
42
43 <!--本地目录-->
44
45 <value>F:/hadoop/apache-hive-2.1.1-bin/hive/iotmp</value>
46
47 <description>Temporary local directory for added resources in the remote file system.</description>
48
49 </property>
50
51 <property>
52
53 <name>hive.querylog.location</name>
54
55 <!--本地目录-->
56
57 <value>F:/hadoop/apache-hive-2.1.1-bin/hive/iotmp</value>
58
59 <description>Location of Hive run time structured log file</description>
60
61 </property>
62
63 <property>
64
65 <name>hive.server2.logging.operation.log.location</name>
66
67 <value>F:/hadoop/apache-hive-2.1.1-bin/hive/iotmp/operation_logs</value>
68
69 <description>Top level directory where operation logs are stored if logging functionality is enabled</description>
70
71 </property>
72
73 <!--新增的配置-->
74
75 <property>
76
77 <name>javax.jdo.option.ConnectionURL</name>
78
79 <value>jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8</value>
80
81 </property>
82
83 <property>
84
85 <name>javax.jdo.option.ConnectionDriverName</name>
86
87 <value>com.mysql.jdbc.Driver</value>
88
89 </property>
90
91 <property>
92
93 <name>javax.jdo.option.ConnectionUserName</name>
94
95 <value>root</value>
96
97 </property>
98
99 <property>
100
101 <name>javax.jdo.option.ConnectionPassword</name>
102
103 <value>root</value>
104
105 </property>
106
107 <!-- 解决 Required table missing : "`VERSION`" in Catalog "" Schema "". DataNucleus requires this table to perform its persistence operations. Either your MetaData is incorrect, or you need to enable "datanucleus.autoCreateTables" -->
108
109 <property>
110
111 <name>datanucleus.autoCreateSchema</name>
112
113 <value>true</value>
114
115 </property>
116
117 <property>
118
119 <name>datanucleus.autoCreateTables</name>
120
121 <value>true</value>
122
123 </property>
124
125 <property>
126
127 <name>datanucleus.autoCreateColumns</name>
128
129 <value>true</value>
130
131 </property>
132
133 <!-- 解决 Caused by: MetaException(message:Version information not found in metastore. ) -->
134
135 <property>
136
137 <name>hive.metastore.schema.verification</name>
138
139 <value>false</value>
140
141 <description>
142
143 Enforce metastore schema version consistency.
144
145 True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
146
147 schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures
148
149 proper metastore schema migration. (Default)
150
151 False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
152
153 </description>
154
155 </property> 注:需要事先在hadoop上创建hdfs目录
启动metastore服务:hive --service metastore
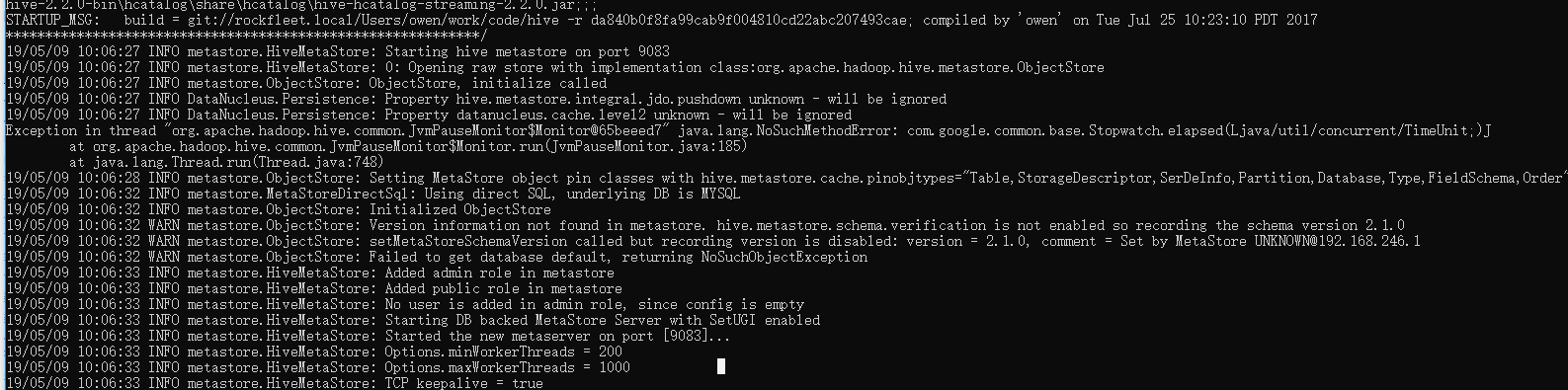
在数据库中生成对应的 hive 数据库
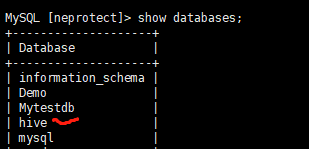
启动Hive:hive

-------------------------------------------------------------- 创建表 以及 查询案例
hive上创建表:
CREATE TABLE testB (
id INT,
name string,
area string
) PARTITIONED BY (create_time string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;
将本地文件上传到 HDFS:
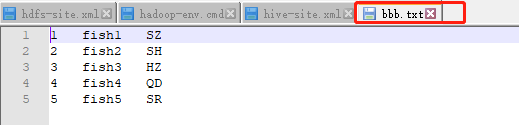
HDFS下执行: D:Codehadoop-2.7.7hadoop-2.7.7sbin>hdfs dfs -put D:Codehadoop-2.7.7gxybb.txt /user/hive/warehouse

hive导入HDFS中的数据:
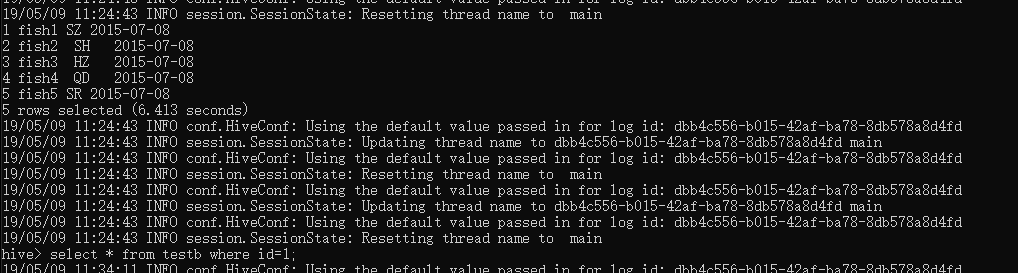
LOAD DATA INPATH '/user/hive/warehouse/bbb.txt' INTO TABLE testb PARTITION(create_time='2015-07-08');
执行选择命令:
select * from testb;