Introduction
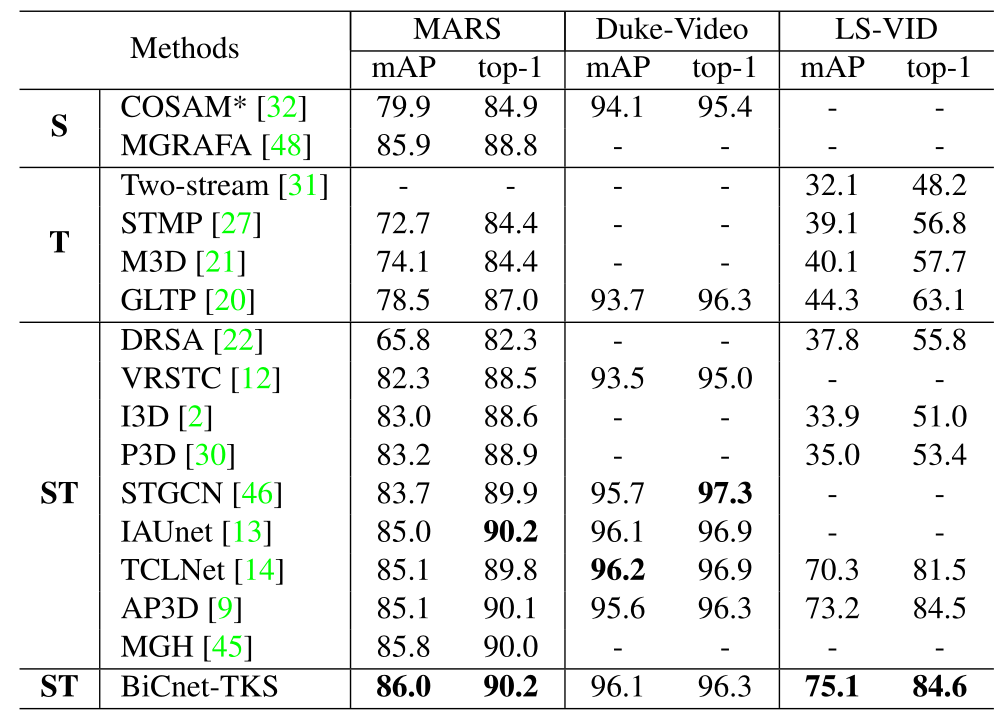
在空间维度上,现有video reid方法局限于把所有帧在相同分辨率下进行特征提取,造成了特征冗余,如图(a)。

在时间维度上,现有方法要么采用long-term要么采用short-term,也有一些方法同时考虑了两者,却赋予两者相同的权重来融合。但如图(b)所示,当存在遮挡情况时,需要long-term来提供更多信息,当存在快速移动情况时,需要short-term来提取动作模式等。因此需要动态地捕获short-term和long-term的特征。

作者提出了Bilateral Complementary Network (BiCnet)来提取不同帧中的互补空间特征。其包含了两个分支,Detail Branch对原分辨率进行空间特征提取,Context Branch对下采样图像进行long-term特征提取。之后在每个分支上增加了多个parallel spatial attention模块,来增强局部注意区域的多样性。最后将两个分支的互补信息进行融合。
此外作者提出了Temporal Kernel Selection (TKS)模块来动态度量short-term和long-term的时序关联。在时间维度上,同时使用小的kernel和大的kernel来捕获时序关联。并且TKS依据全局信息选择了一个dominant temporal scale (主导时序尺度)。将BiCnet和TKS结合,命名为BiCnet-TKS。
Proposed Method
(1) Bilateral Complementary Network:
① Two-branch Architecture:
假设输入的视频序列为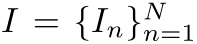 ,划分为
,划分为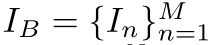 和
和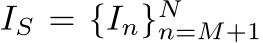 (B表示Big;S表示small,分辨率是B的一半),分别输入到两个分支中,即:
(B表示Big;S表示small,分辨率是B的一半),分别输入到两个分支中,即:
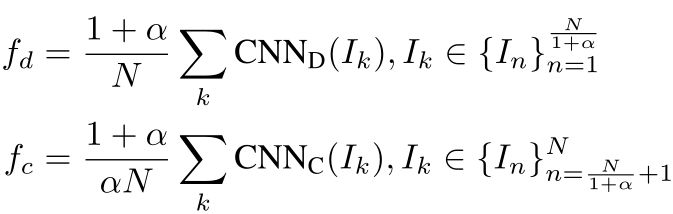
最终将两个特征求平均值。
② Cross-Scale Paths:
在两个分支间设计了Cross-Scale Paths(CSP)将Detail分支的信息传播到Context分支中。假设两个分支的中间特征图为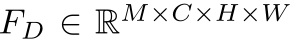 和
和 。由于两者的结构不同,需要改变前者的特征图维度,即:
。由于两者的结构不同,需要改变前者的特征图维度,即:
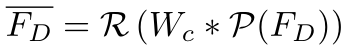
其中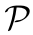 为最大池化,*为卷积,
为最大池化,*为卷积, 为reshape操作使得维度从
为reshape操作使得维度从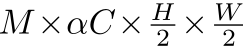 转为
转为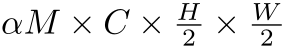 。特征图维度一致后将两者进行相加融合。
。特征图维度一致后将两者进行相加融合。
③ Diverse Attentions Operation:
每个分支都嵌入了DAO模块来增强注意力的多样性。对第一帧进行全局平均池化和softmax,获取权重图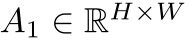 ,而后续帧的权重图计算为:通过卷积层压缩通道为1,空间维度reshape为HW维,在、通过全连接层映射,再重新回复到HxW维,最后进行softmax得到权重。为了训练不同帧关注不同区域,设计了divergence regularization term,即:
,而后续帧的权重图计算为:通过卷积层压缩通道为1,空间维度reshape为HW维,在、通过全连接层映射,再重新回复到HxW维,最后进行softmax得到权重。为了训练不同帧关注不同区域,设计了divergence regularization term,即:
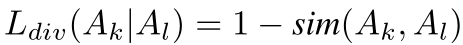
作者采用了dot-product相似度(余弦相似度),上述的公式表示两个区域的区别度(越大越好),因此下面divergence loss越小越好:
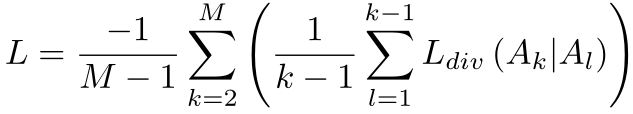
(2) Temporal Kernel Selection Block:
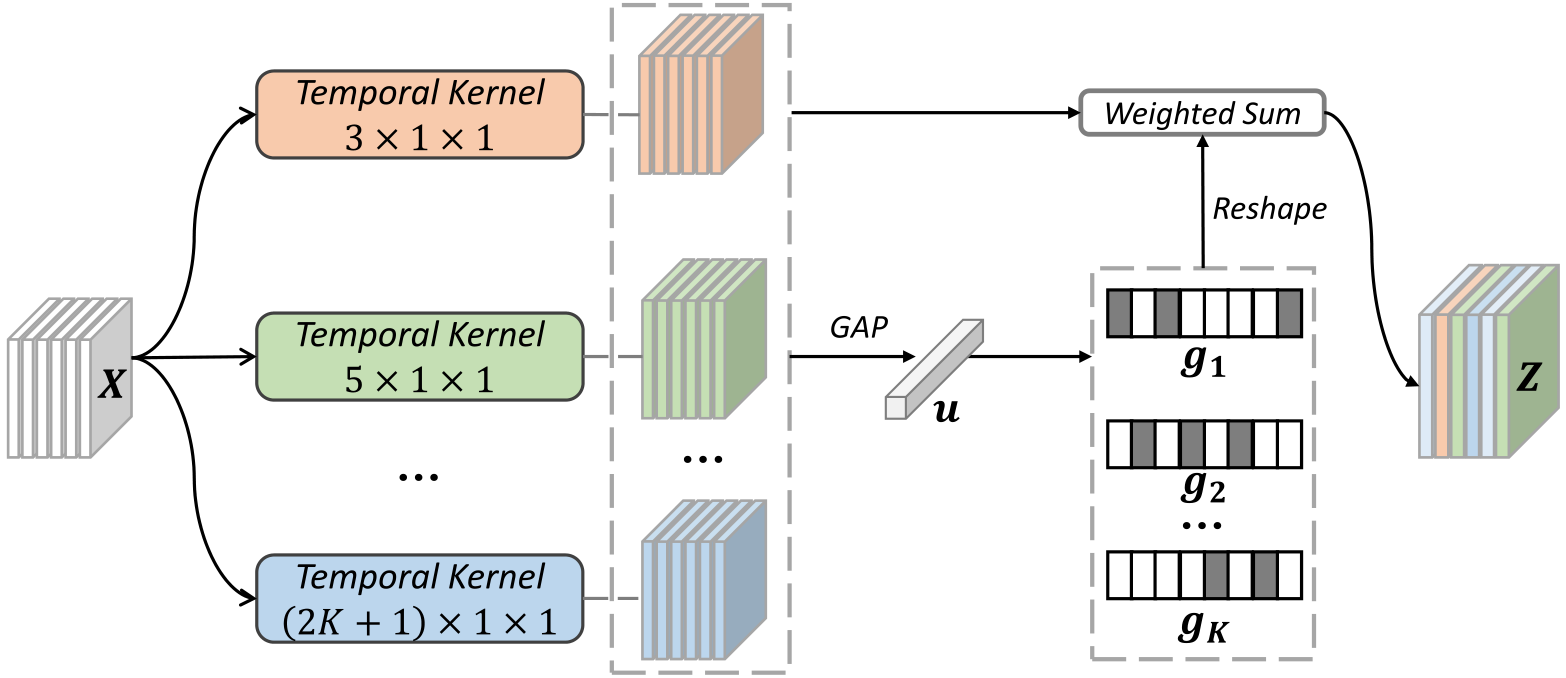
TKS对一个特征图序列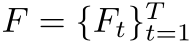 进行处理,分为三个步骤:分割、选择、激励。
进行处理,分为三个步骤:分割、选择、激励。
① Partition Operation:
由于不同帧的行人图像存在不对齐现象,因此采用分块策略,把每帧分为hxw个空间块,再对每个块采用平均池化,得到region-level的特征图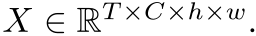
② Select Operation:
采用K个分支,每个分支采用不同卷积核尺寸的1D空洞卷积,将K个分支的输出相加,再进行全局平均池化,得到全局特征,即:
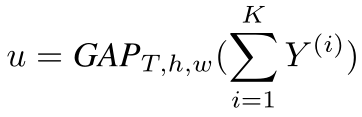
对全局特征进行K个投影,再进行正则化,即:
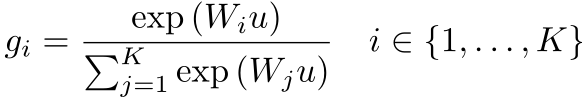
最后将K个分支的权重进行加权求和,即:
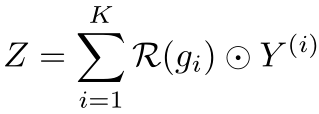
其中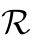 是reshape。
是reshape。
③ Excite Operation:
基于残差的思想,最终的特征图可以计算为: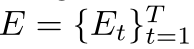 ,
,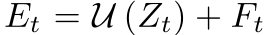 ,其中
,其中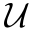 为最邻近上采样。TKS保持了原始特征图尺寸,因此可以插入网络任何阶段。
为最邻近上采样。TKS保持了原始特征图尺寸,因此可以插入网络任何阶段。
(3) Overall Architecture:
作者采用预训练的ResNet-50作为骨干网络,DAO插入在第三个stage后,而TKS可以插入在任何阶段。两个分支共享权重以降低参数量。
Experiment