先来一个整体图
一.
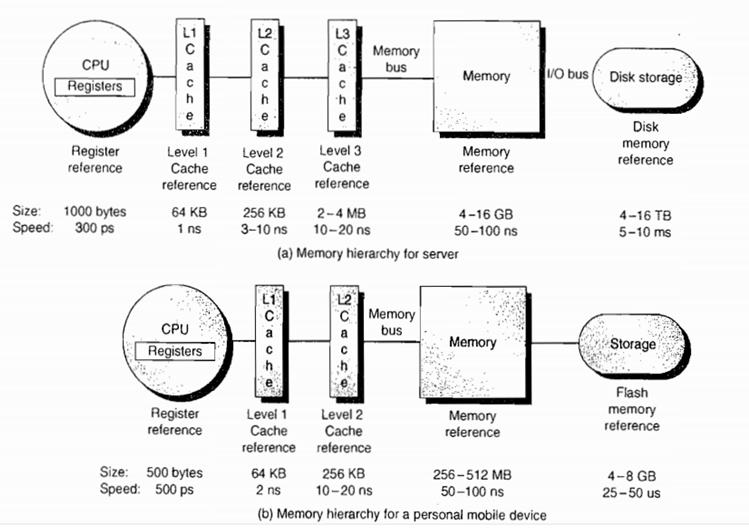
大致关系: CPU Cache --> 前端总线 FSB (下图中的Bus) --> Memory 内存
CPU 为了更快的执行代码。于是当从内存中读取数据时,并不是只读自己想要的部分。而是读取足够的字节来填入高速缓存行。根据不同的 CPU ,高速缓存行大小不同。如 X86 是 32BYTES ,而 ALPHA 是 64BYTES 。并且始终在第 32 个字节或第 64 个字节处对齐。这样,当 CPU 访问相邻的数据时,就不必每次都从内存中读取,提高了速度。 因为访问内存要比访问高速缓存用的时间多得多。
下面一张图可以看出各级缓存之间的响应时间差距,以及内存到底有多慢!

(2)总线概念
前端总线(FSB)就是负责将CPU连接到内存的一座桥,前端总线频率则直接影响CPU与内存数据交换速度,如果FSB频率越高,说明这座桥越宽,可以同时通过的车辆越多,这样CPU处理的速度就更快。目前PC机上CPU前端总线频率有533MHz、800MHz、1066MHz、1333MHz、1600MHz等几种,前端总线频率越高,CPU与内存之间的数据传输量越大。
前端总线——Front Side Bus(FSB),是将CPU连接到北桥芯片的总线。选购主板和CPU时,要注意两者搭配问题,一般来说,前端总线是由CPU决定的,如果主板不支持CPU所需要的前端总线,系统就无法工作
(3) 频率与降频概念
只支持1333内存频率的cpu和主板配1600内存条就会降频。核心数跟ddr2和ddr3没关系,核心数是cpu本身的性质,cpu是四核的就是四核的,是双核的就是双核的。
如果只cpu支持1333,而主板支持1600,那也会降频;cpu支持1600而主板只支持1333那不仅内存会降频,而且发挥不出cpu全部性能。
另外如果是较新的主板cpu,已经采用新的qpi总线,而不是以前的fsb总线。
以前的fsb总线一般是总线为多少就支持多高的内存频率。而qpi总线的cpu集成了内存控制器,5.0
gt/s的cpu可能只支持1333内存频率,但是总线带宽相当于1333内存的内存带宽的两倍,这时候,组成1333双通道,内存速度就会翻倍,相当于2666的内存频率。
什么是Cache Line
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。目前主流的CPU Cache的Cache Line大小都是64Bytes。假设我们有一个512字节的一级缓存,那么按照64B的缓存单位大小来算,这个一级缓存所能存放的缓存个数就是512/64 = 8个。具体参见下图:

为了更好的了解Cache Line,我们还可以在自己的电脑上做下面这个有趣的实验。
下面这段C代码,会从命令行接收一个参数作为数组的大小创建一个数量为N的int数组。并依次循环的从这个数组中进行数组内容访问,循环10亿次。最终输出数组总大小和对应总执行时间。
#include "stdio.h" #include <stdlib.h> #include <sys/time.h> long timediff(clock_t t1, clock_t t2) { long elapsed; elapsed = ((double)t2 - t1) / CLOCKS_PER_SEC * 1000; return elapsed; } int main(int argc, char *argv[]) #******* { int array_size=atoi(argv[1]); int repeat_times = 1000000000; long array[array_size]; for(int i=0; i<array_size; i++){ array[i] = 0; } int j=0; int k=0; int c=0; clock_t start=clock(); while(j++<repeat_times){ if(k==array_size){ k=0; } c = array[k++]; } clock_t end =clock(); printf("%lu ", timediff(start,end)); return 0; }
如果我们把这些数据做成折线图后就会发现:总执行时间在数组大小超过64Bytes时有较为明显的拐点(当然,由于博主是在自己的Mac笔记本上测试的,会受到很多其他程序的干扰,因此会有波动)。原因是当数组小于64Bytes时数组极有可能落在一条Cache Line内,而一个元素的访问就会使得整条Cache Line被填充,因而值得后面的若干个元素受益于缓存带来的加速。而当数组大于64Bytes时,必然至少需要两条Cache Line,继而在循环访问时会出现两次Cache Line的填充,由于缓存填充的时间远高于数据访问的响应时间,因此多一次缓存填充对于总执行的影响会被放大,最终得到下图的结果:

我们来看下面这个C语言中常用的循环优化例子
下面两段代码中,第一段代码在C语言中总是比第二段代码的执行速度要快。具体的原因相信你仔细阅读了Cache Line的介绍后就很容易理解了。
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
int num;
arr[i][j] = num;
}
}for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
int num;
arr[j][i] = num;
}
}三. 下面看CPU Cache与Memory关系图
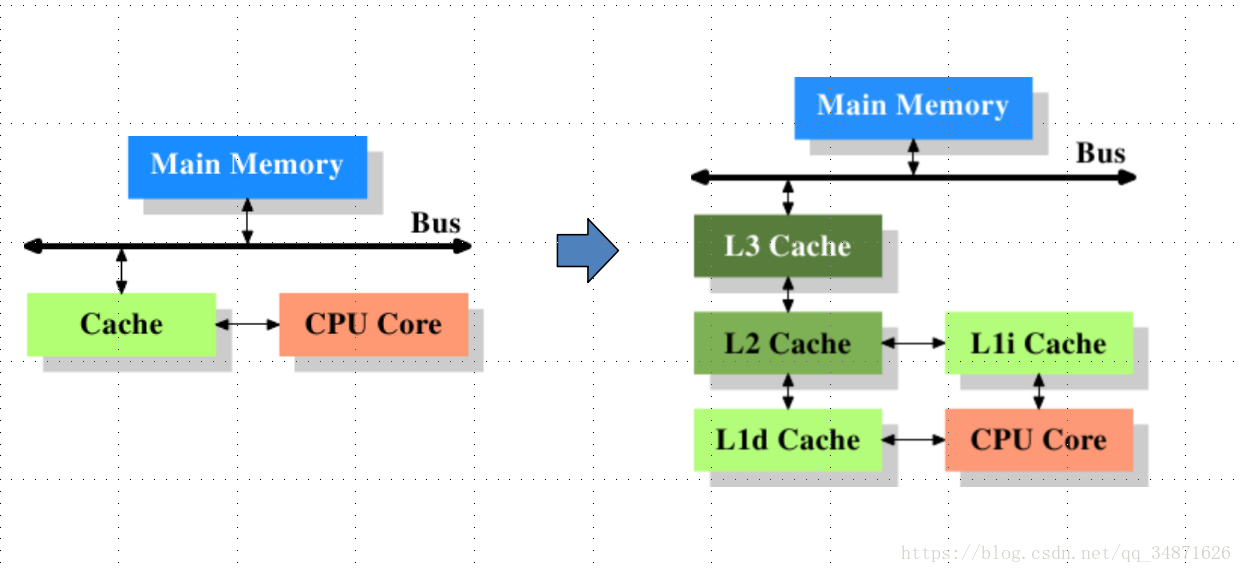
上述左图是最简单的高速缓存的图示,数据的读取和存储都经过高速缓存,CPU核心和高速缓存之间有一条特殊的快速通道,在这个简化的图示上,主存(main memory)与高速缓存(cache)都连在系统总线上。这条总线同时还用于其他组件之间的通信。在高速缓存出现后不久,系统变得更加复杂,高速缓存与主存之间的速度差异被拉大,直到加入了另一级的缓存(由于加大一级缓存的做法从经济上考虑是行不通的,所以有了二级缓存甚至三级缓存)。新加入的这些缓存比第一缓存更大但是更慢。
多核发达的年代。情况就不能那么简单了。试想下面这样一个情况。
1、 CPU1 读取了一个字节,以及它和它相邻的字节被读入 CPU1 的高速缓存。
2、 CPU2 做了上面同样的工作。这样 CPU1 , CPU2 的高速缓存拥有同样的数据。
3、 CPU1 修改了那个字节,被修改后,那个字节被放回 CPU1 的高速缓存行。但是该信息并没有被写入 RAM 。
4、 CPU2 访问该字节,但由于 CPU1 并未将数据写入 RAM ,导致了数据不同步。
为了解决这个问题,芯片设计者制定了一个规则。当一个 CPU 修改高速缓存行中的字节时,计算机中的其它 CPU 会被通知,它们的高速缓存将视为无效。于是,在上面的情况下, CPU2 发现自己的高速缓存中数据已无效, CPU1 将立即把自己的数据写回 RAM ,然后 CPU2 重新读取该数据。 可以看出,高速缓存行在多处理器上会导致一些不利。
四. 多核CPU多级缓存一致性协议MESI
多核CPU的情况下有多个一级缓存,如何保证缓存内部数据的一致,不让系统数据混乱。这里就引出了一个一致性的协议MESI。
MESI协议缓存状态
MESI 是指4中状态的首字母。每个Cache line有4个状态,可用2个bit表示,它们分别是:
缓存行(Cache line):缓存存储数据的单元。
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 |
| E 独享、互斥 (Exclusive) | 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
| S 共享 (Shared) | 该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I 无效 (Invalid) | 该Cache line无效。 | 无 |
注意:
对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
从上面的意义看来E状态是一种投机性的优化:如果一个CPU想修改一个处于S状态的缓存行,总线事务需要将所有该缓存行的copy变成invalid状态,而修改E状态的缓存不需要使用总线事务。
MESI状态转换
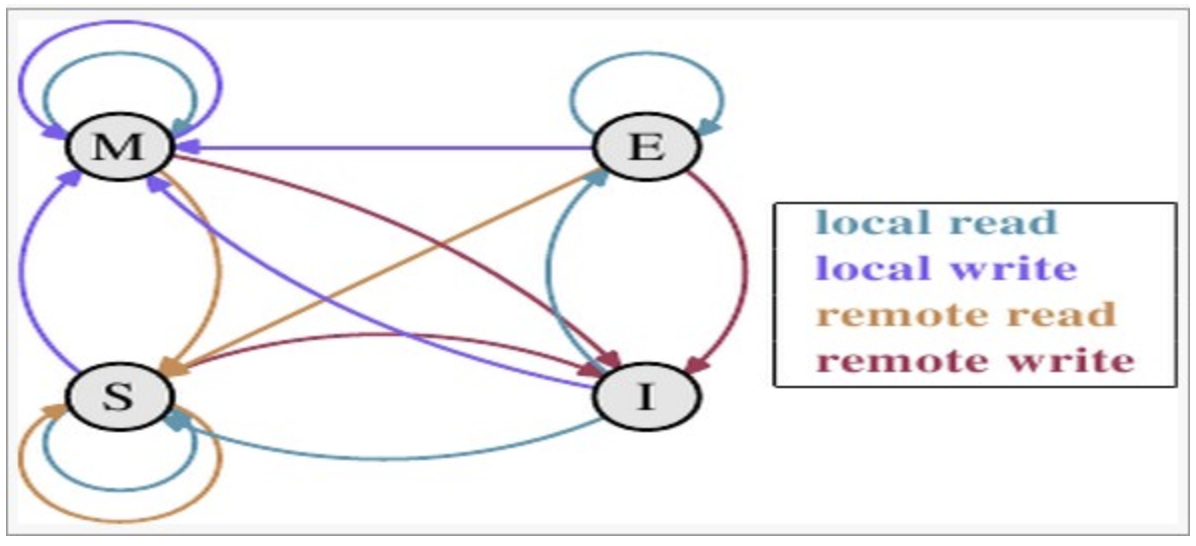
理解该图的前置说明:
1.触发事件
| 触发事件 | 描述 |
|---|---|
| 本地读取(Local read) | 本地cache读取本地cache数据 |
| 本地写入(Local write) | 本地cache写入本地cache数据 |
| 远端读取(Remote read) | 其他cache读取本地cache数据 |
| 远端写入(Remote write) | 其他cache写入本地cache数据 |
2.cache分类:
前提:所有的cache共同缓存了主内存中的某一条数据。
本地cache:指当前cpu的cache。
触发cache:触发读写事件的cache。
其他cache:指既除了以上两种之外的cache。
注意:本地的事件触发 本地cache和触发cache为相同。
上图的切换解释:
| 状态 | 触发本地读取 | 触发本地写入 | 触发远端读取 | 触发远端写入 |
|---|---|---|---|---|
| M状态(修改) | 本地cache:M 触发cache:M 其他cache:I | 本地cache:M 触发cache:M 其他cache:I | 本地cache:M→E→S 触发cache:I→S 其他cache:I→S 同步主内存后修改为E独享,同步触发、其他cache后本地、触发、其他cache修改为S共享 | 本地cache:M→E→S→I 触发cache:I→S→E→M 其他cache:I→S→I 同步和读取一样,同步完成后触发cache改为M,本地、其他cache改为I |
| E状态(独享) | 本地cache:E 触发cache:E 其他cache:I | 本地cache:E→M 触发cache:E→M 其他cache:I 本地cache变更为M,其他cache状态应当是I(无效) | 本地cache:E→S 触发cache:I→S 其他cache:I→S 当其他cache要读取该数据时,其他、触发、本地cache都被设置为S(共享) | 本地cache:E→S→I 触发cache:I→S→E→M 其他cache:I→S→I 当触发cache修改本地cache独享数据时时,将本地、触发、其他cache修改为S共享.然后触发cache修改为独享,其他、本地cache修改为I(无效),触发cache再修改为M |
| S状态(共享) | 本地cache:S 触发cache:S 其他cache:S | 本地cache:S→E→M 触发cache:S→E→M 其他cache:S→I 当本地cache修改时,将本地cache修改为E,其他cache修改为I,然后再将本地cache为M状态 | 本地cache:S 触发cache:S 其他cache:S | 本地cache:S→I 触发cache:S→E→M 其他cache:S→I 当触发cache要修改本地共享数据时,触发cache修改为E(独享),本地、其他cache修改为I(无效),触发cache再次修改为M(修改) |
| I状态(无效) | 本地cache:I→S或者I→E 触发cache:I→S或者I →E 其他cache:E、M、I→S、I 本地、触发cache将从I无效修改为S共享或者E独享,其他cache将从E、M、I 变为S或者I | 本地cache:I→S→E→M 触发cache:I→S→E→M 其他cache:M、E、S→S→I | 既然是本cache是I,其他cache操作与它无关 | 既然是本cache是I,其他cache操作与它无关 |
下图示意了,当一个cache line的调整的状态的时候,另外一个cache line 需要调整的状态。
| M | E | S | I | |
|---|---|---|---|---|
| M | × | × | × | √ |
| E | × | × | × | √ |
| S | × | × | √ | √ |
| I | √ | √ | √ | √ |
举个栗子来说:
假设cache 1 中有一个变量x = 0的cache line 处于S状态(共享)。
那么其他拥有x变量的cache 2、cache 3等x的cache line调整为S状态(共享)或者调整为 I 状态(无效)。
多核缓存协同操作
假设有三个CPU A、B、C,对应三个缓存分别是cache a、b、 c。在主内存中定义了x的引用值为0。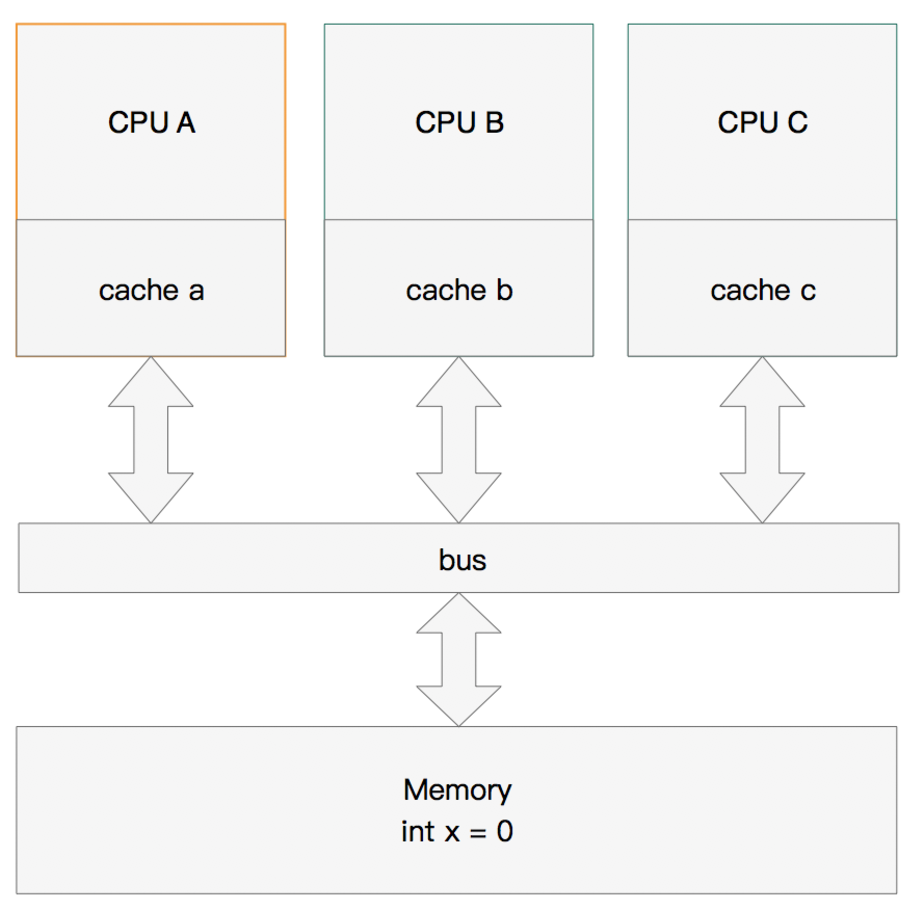
单核读取
那么执行流程是:
CPU A发出了一条指令,从主内存中读取x。
从主内存通过bus读取到缓存中(远端读取Remote read),这是该Cache line修改为E状态(独享).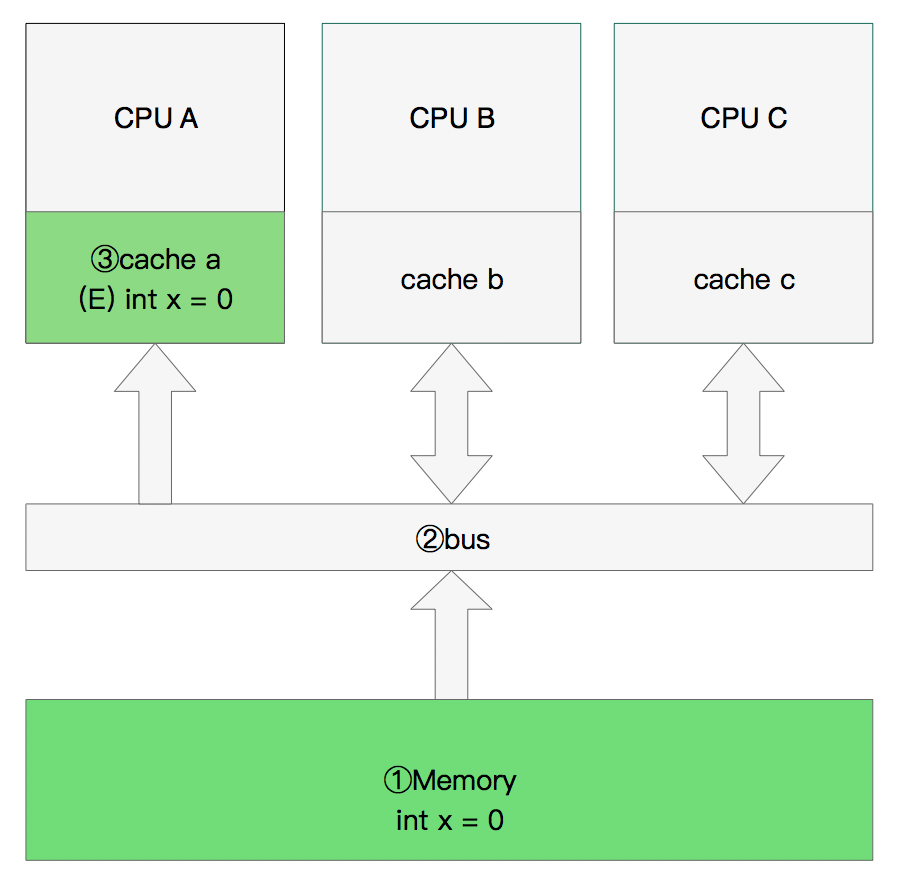
双核读取
那么执行流程是:
CPU A发出了一条指令,从主内存中读取x。
CPU A从主内存通过bus读取到 cache a中并将该cache line 设置为E状态。
CPU B发出了一条指令,从主内存中读取x。
CPU B试图从主内存中读取x时,CPU A检测到了地址冲突。这时CPU A对相关数据做出响应。此时x 存储于cache a和cache b中,x在chche a和cache b中都被设置为S状态(共享)。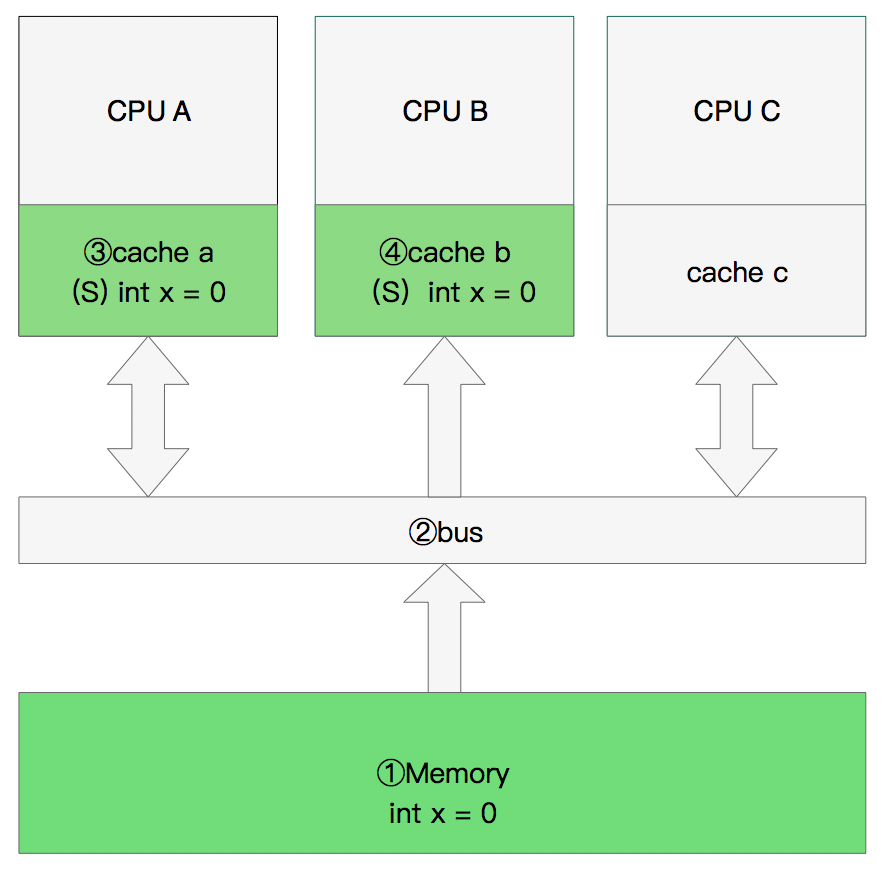
修改数据
那么执行流程是:
CPU A 计算完成后发指令需要修改x.
CPU A 将x设置为M状态(修改)并通知缓存了x的CPU B, CPU B将本地cache b中的x设置为I状态(无效)
CPU A 对x进行赋值。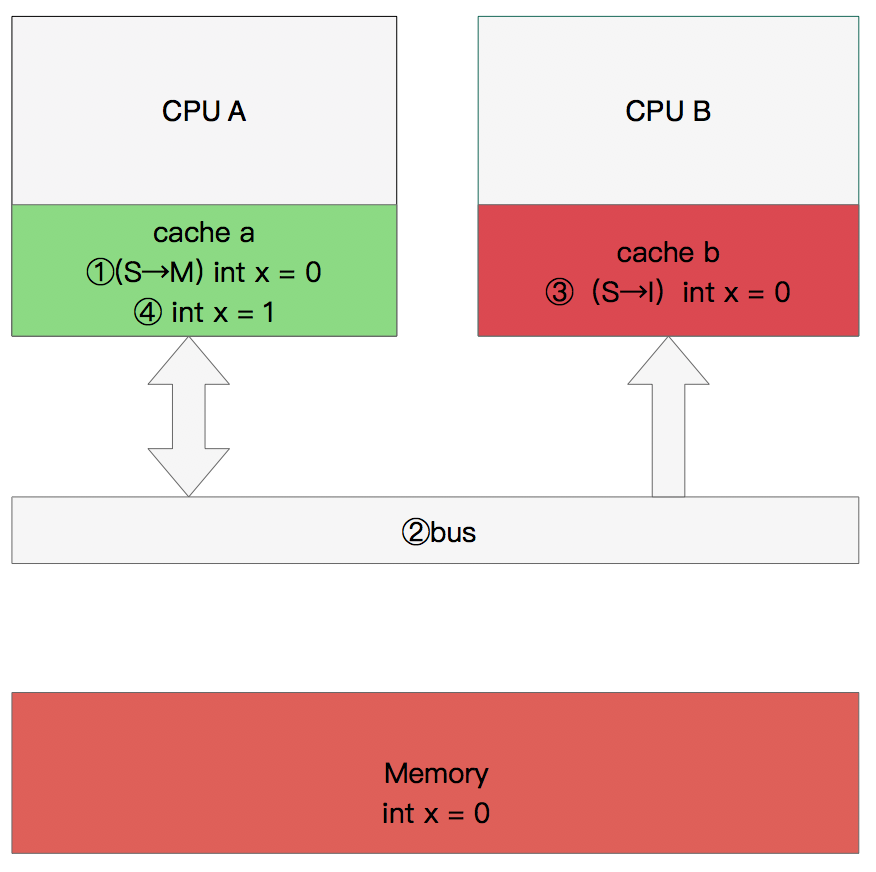
同步数据
那么执行流程是:
CPU B 发出了要读取x的指令。
CPU B 通知CPU A,CPU A将修改后的数据同步到主内存时cache a 修改为E(独享)
CPU A同步CPU B的x,将cache a和同步后cache b中的x设置为S状态(共享)。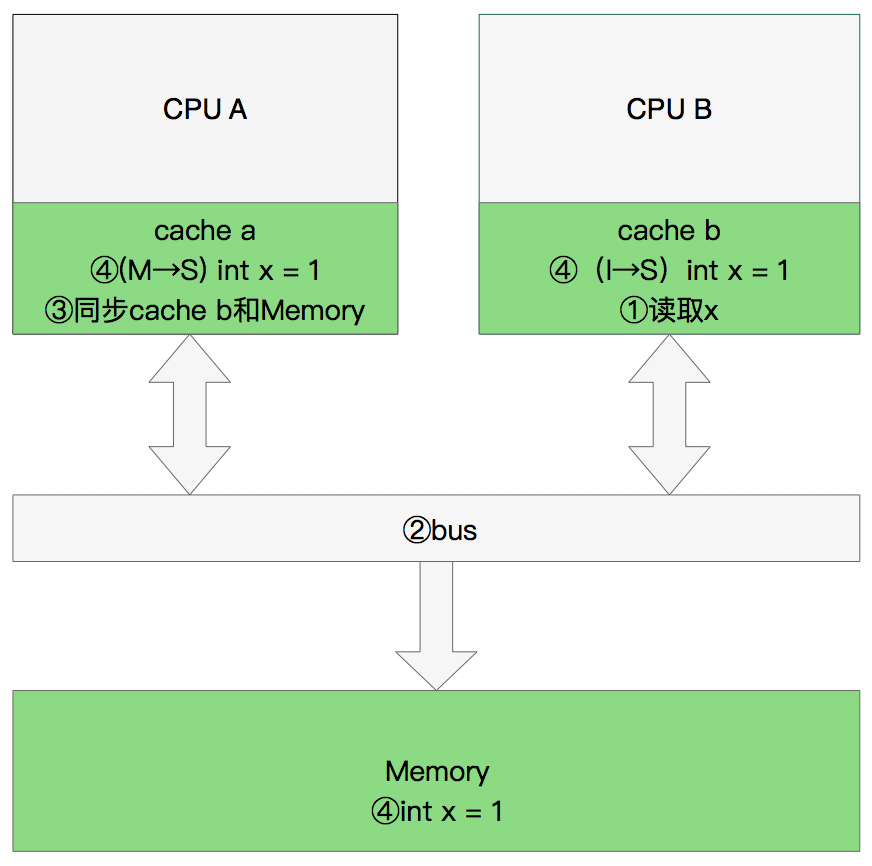
MESI优化和他们引入的问题
缓存的一致性消息传递是要时间的,这就使其切换时会产生延迟。当一个缓存被切换状态时其他缓存收到消息完成各自的切换并且发出回应消息这么一长串的时间中CPU都会等待所有缓存响应完成。可能出现的阻塞都会导致各种各样的性能问题和稳定性问题。
CPU切换状态阻塞解决-存储缓存(Store Bufferes)
比如你需要修改本地缓存中的一条信息,那么你必须将I(无效)状态通知到其他拥有该缓存数据的CPU缓存中,并且等待确认。等待确认的过程会阻塞处理器,这会降低处理器的性能。应为这个等待远远比一个指令的执行时间长的多。
Store Bufferes
为了避免这种CPU运算能力的浪费,Store Bufferes被引入使用。处理器把它想要写入到主存的值写到缓存,然后继续去处理其他事情。当所有失效确认(Invalidate Acknowledge)都接收到时,数据才会最终被提交。
这么做有两个风险
Store Bufferes的风险
第一、就是处理器会尝试从存储缓存(Store buffer)中读取值,但它还没有进行提交。这个的解决方案称为Store Forwarding,它使得加载的时候,如果存储缓存中存在,则进行返回。
第二、保存什么时候会完成,这个并没有任何保证。
value = 3;
void exeToCPUA(){
value = 10;
isFinsh = true;
}
void exeToCPUB(){
if(isFinsh){
//value一定等于10?!
assert value == 10;
}
} 试想一下开始执行时,CPU A保存着finished在E(独享)状态,而value并没有保存在它的缓存中。(例如,Invalid)。在这种情况下,value会比finished更迟地抛弃存储缓存。完全有可能CPU B读取finished的值为true,而value的值不等于10。
即isFinsh的赋值在value赋值之前。
这种在可识别的行为中发生的变化称为重排序(reordings)。注意,这不意味着你的指令的位置被恶意(或者好意)地更改。
它只是意味着其他的CPU会读到跟程序中写入的顺序不一样的结果。
顺便提一下NIO的设计和Store Bufferes的设计是非常相像的。
硬件内存模型
执行失效也不是一个简单的操作,它需要处理器去处理。另外,存储缓存(Store Buffers)并不是无穷大的,所以处理器有时需要等待失效确认的返回。这两个操作都会使得性能大幅降低。为了应付这种情况,引入了失效队列。它们的约定如下:
- 对于所有的收到的Invalidate请求,Invalidate Acknowlege消息必须立刻发送
- Invalidate并不真正执行,而是被放在一个特殊的队列中,在方便的时候才会去执行。
- 处理器不会发送任何消息给所处理的缓存条目,直到它处理Invalidate。
即便是这样处理器已然不知道什么时候优化是允许的,而什么时候并不允许。
干脆处理器将这个任务丢给了写代码的人。这就是内存屏障(Memory Barriers)。
写屏障 Store Memory Barrier(a.k.a. ST, SMB, smp_wmb)是一条告诉处理器在执行这之后的指令之前,应用所有已经在存储缓存(store buffer)中的保存的指令。
读屏障Load Memory Barrier (a.k.a. LD, RMB, smp_rmb)是一条告诉处理器在执行任何的加载前,先应用所有已经在失效队列中的失效操作的指令。
void executedOnCpu0() {
value = 10;
//在更新数据之前必须将所有存储缓存(store buffer)中的指令执行完毕。
storeMemoryBarrier();
finished = true;
}
void executedOnCpu1() {
while(!finished);
//在读取之前将所有失效队列中关于该数据的指令执行完毕。
loadMemoryBarrier();
assert value == 10;
}现在确实安全了。完美无暇!
从上面的情况可以看出,在设计数据结构的时候,应该尽量将只读数据与读写数据分开,并具尽量将同一时间访问的数据组合在一起。这样 CPU 能一次将需要的数据读入。
如:
Struct __a
{
Int id; // 不易变
Int factor;// 易变
Char name[64];// 不易变
Int value;// 易变
} ;
这样的数据结构就很不利。
在 X86 下,可以试着修改和调整它
Struct __a
{
Int id; // 不易变
Char name[64];// 不易变
Char __Align[32 – sizeof(int)+sizeof(name)*sizeof(name[0])%32]
Int factor;// 易变
Int value;// 易变
Char __Align2[32 –2* sizeof(int)%32]
} ;五. CPU Cache 是如何存放数据的
你会怎么设计Cache的存放规则
我们先来尝试回答一下那么这个问题:
假设我们有一块4MB的区域用于缓存,每个缓存对象的唯一标识是它所在的物理内存地址。每个缓存对象大小是64Bytes,所有可以被缓存对象的大小总和(即物理内存总大小)为4GB。那么我们该如何设计这个缓存?
如果你和博主一样是一个大学没有好好学习基础/数字电路的人的话,会觉得最靠谱的的一种方式就是:Hash表。把Cache设计成一个Hash数组。内存地址的Hash值作为数组的Index,缓存对象的值作为数组的Value。每次存取时,都把地址做一次Hash然后找到Cache中对应的位置操作即可。
这样的设计方式在高等语言中很常见,也显然很高效。因为Hash值得计算虽然耗时(10000个CPU Cycle左右),但是相比程序中其他操作(上百万的CPU Cycle)来说可以忽略不计。而对于CPU Cache来说,本来其设计目标就是在几十CPU Cycle内获取到数据。如果访问效率是百万Cycle这个等级的话,还不如到Memory直接获取数据。当然,更重要的原因是在硬件上要实现Memory Address Hash的功能在成本上是非常高的。
为什么Cache不能做成Fully Associative
Fully Associative 字面意思是全关联。在CPU Cache中的含义是:如果在一个Cache集内,任何一个内存地址的数据可以被缓存在任何一个Cache Line里,那么我们成这个cache是Fully Associative。从定义中我们可以得出这样的结论:给到一个内存地址,要知道他是否存在于Cache中,需要遍历所有Cache Line并比较缓存内容的内存地址。而Cache的本意就是为了在尽可能少得CPU Cycle内取到数据。那么想要设计一个快速的Fully Associative的Cache几乎是不可能的。
为什么Cache不能做成Direct Mapped
和Fully Associative完全相反,使用Direct Mapped模式的Cache给定一个内存地址,就唯一确定了一条Cache Line。设计复杂度低且速度快。那么为什么Cache不使用这种模式呢?让我们来想象这么一种情况:一个拥有1M L2 Cache的32位CPU,每条Cache Line的大小为64Bytes。那么整个L2Cache被划为了1M/64=16384条Cache Line。我们为每条Cache Line从0开始编上号。同时32位CPU所能管理的内存地址范围是2^32=4G,那么Direct Mapped模式下,内存也被划为4G/16384=256K的小份。也就是说每256K的内存地址共享一条Cache Line。
但是,这种模式下每条Cache Line的使用率如果要做到接近100%,就需要操作系统对于内存的分配和访问在地址上也是近乎平均的。而与我们的意愿相反,为了减少内存碎片和实现便捷,操作系统更多的是连续集中的使用内存。这样会出现的情况就是0-1000号这样的低编号Cache Line由于内存经常被分配并使用,而16000号以上的Cache Line由于内存鲜有进程访问,几乎一直处于空闲状态。这种情况下,本来就宝贵的1M二级CPU缓存,使用率也许50%都无法达到。
什么是N-Way Set Associative
为了避免以上两种设计模式的缺陷,N-Way Set Associative缓存就出现了。他的原理是把一个缓存按照N个Cache Line作为一组(set),缓存按组划为等分。这样一个64位系统的内存地址在4MB二级缓存中就划成了三个部分(见下图),低位6个bit表示在Cache Line中的偏移量,中间12bit表示Cache组号(set index),剩余的高位46bit就是内存地址的唯一id。这样的设计相较前两种设计有以下两点好处:
- 给定一个内存地址可以唯一对应一个set,对于set中只需遍历16个元素就可以确定对象是否在缓存中(Full Associative中比较次数随内存大小线性增加)
- 每2^18(256K)*64=16M的连续热点数据才会导致一个set内的conflict(Direct Mapped中512K的连续热点数据就会出现conflict)

为什么N-Way Set Associative的Set段是从低位而不是高位开始的
下面是一段从How Misaligning Data Can Increase Performance 12x by Reducing Cache Misses摘录的解释:
The vast majority of accesses are close together, so moving the set index bits upwards would cause more conflict misses. You might be able to get away with a hash function that isn’t simply the least significant bits, but most proposed schemes hurt about as much as they help while adding extra complexity.
由于内存的访问通常是大片连续的,或者是因为在同一程序中而导致地址接近的(即这些内存地址的高位都是一样的)。所以如果把内存地址的高位作为set index的话,那么短时间的大量内存访问都会因为set index相同而落在同一个set index中,从而导致cache conflicts使得L2, L3 Cache的命中率低下,影响程序的整体执行效率。
了解N-Way Set Associative的存储模式对我们有什么帮助
了解N-Way Set的概念后,我们不难得出以下结论:2^(6Bits <Cache Line Offset> + 12Bits <Set Index>) = 2^18 = 512K。即在连续的内存地址中每512K都会出现一个处于同一个Cache Set中的缓存对象。也就是说这些对象都会争抢一个仅有16个空位的缓存池(16-Way Set)。而如果我们在程序中又使用了所谓优化神器的“内存对齐”的时候,这种争抢就会越发增多。效率上的损失也会变得非常明显。具体的实际测试我们可以参考: How Misaligning Data Can Increase Performance 12x by Reducing Cache Misses 一文。
这里我们引用一张Gallery of Processor Cache Effects 中的测试结果图,来解释下内存对齐在极端情况下带来的性能损失。

该图实际上是我们上文中第一个测试的一个变种。纵轴表示了测试对象数组的大小。横轴表示了每次数组元素访问之间的index间隔。而图中的颜色表示了响应时间的长短,蓝色越明显的部分表示响应时间越长。从这个图我们可以得到很多结论。当然这里我们只对内存带来的性能损失感兴趣。有兴趣的读者也可以阅读原文分析理解其他从图中可以得到的结论。
从图中我们不难看出图中每1024个步进,即每1024*4即4096Bytes,都有一条特别明显的蓝色竖线。也就是说,只要我们按照4K的步进去访问内存(内存根据4K对齐),无论热点数据多大它的实际效率都是非常低的!按照我们上文的分析,如果4KB的内存对齐,那么一个80MB的数组就含有20480个可以被访问到的数组元素;而对于一个每512K就会有set冲突的16Way二级缓存,总共有512K/20480=25个元素要去争抢16个空位。那么缓存命中率只有64%,自然效率也就低了。
想要知道更多关于内存地址对齐在目前的这种CPU-Cache的架构下会出现的问题可以详细阅读以下两篇文章:
- How Misaligning Data Can Increase Performance 12x by Reducing Cache Misses
- Gallery of Processor Cache Effects
Cache淘汰策略
在文章的最后我们顺带提一下CPU Cache的淘汰策略。常见的淘汰策略主要有LRU和Random两种。通常意义下LRU对于Cache的命中率会比Random更好,所以CPU Cache的淘汰策略选择的是LRU。当然也有些实验显示在Cache Size较大的时候Random策略会有更高的命中率
参考来源:
1. CPU高速缓存行 https://blog.csdn.net/boyuejiang/article/details/8908335
2. 关于CPU Cache和Cache Line https://blog.csdn.net/midion9/article/details/49487919
3. CPU缓存一致性协议MESI https://www.cnblogs.com/yanlong300/p/8986041.html