摘要:
javax.management.InstanceAlreadyExistsException:kafka.consumer:type=FetchRequestAndResponseMetrics,name=FetchResponseSize,clientId=iot在CloudearManager中安装kafka时,报了这样一个错:[KafkaServer92],Fatalerrorduring
javax.management.InstanceAlreadyExistsException: kafka.consumer:type=FetchRequestAndResponseMetrics,name=FetchRes
ponseSize,clientId=iot
在CloudearManager中安装kafka时,报了这样一个错:
[Kafka Server 92], Fatal error during KafkaServer startup. Prepare to shutdown java.lang.OutOfMemoryError: Java heap space at java.nio.HeapByteBuffer.<init>(HeapByteBuffer.java:57) at java.nio.ByteBuffer.allocate(ByteBuffer.java:331) at kafka.log.SkimpyOffsetMap.<init>(OffsetMap.scala:45) at kafka.log.LogCleaner$CleanerThread.<init>(LogCleaner.scala:214) at kafka.log.LogCleaner$$anonfun$3.apply(LogCleaner.scala:105) at kafka.log.LogCleaner$$anonfun$3.apply(LogCleaner.scala:105) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.immutable.Range.foreach(Range.scala:160) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at kafka.log.LogCleaner.<init>(LogCleaner.scala:105) at kafka.log.LogManager.<init>(LogManager.scala:78) at kafka.log.LogManager$.apply(LogManager.scala:598) at kafka.server.KafkaServer.startup(KafkaServer.scala:215) at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:44) at kafka.Kafka$.main(Kafka.scala:65) at com.cloudera.kafka.wrap.Kafka$.main(Kafka.scala:76) at com.cloudera.kafka.wrap.Kafka.main(Kafka.scala)
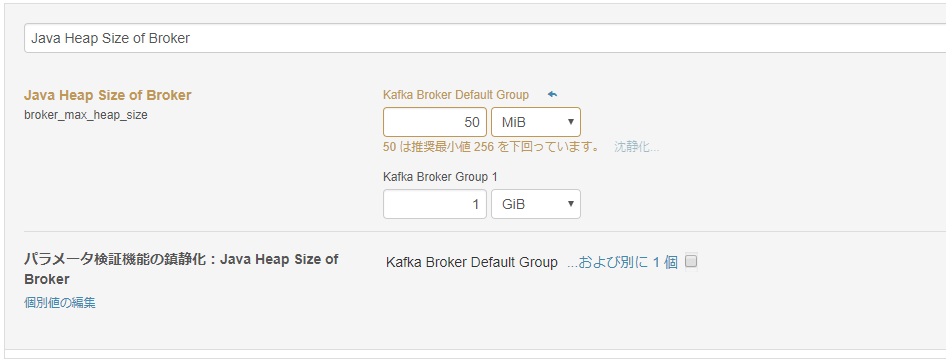
解决办法,就是在ClouderaManager中设定Java Heap Size of Broker的值,将50M改为256M,如下图: