#### ### ## 背景
最近有小伙伴在做落地、推动三方包漏洞检测时遇到了一些问题:与devops工具侧同学以及业务线研发同学沟通时,存在双方不理解对方表述,鸡同鸭讲的情况;
解答了几次相关问题后,发现这些问题有一些共性:都会涉及到研发流程、CICD、工程化的一些点;
(比如CICD具体是哪些,commit、build这些阶段是属于哪个阶段,具体是什么含义,哪个是合适的安全检测触发点,有实现安全左移么?工具侧同学说的gitlab-ci、runner、.gitlab-ci.yml、pipeline又是什么,安全检测与这些又是什么关系;等等),这些知识对安全同学一定成度上来说是陌生的,但又是研发安全在企业里落地推动时的基础;
在网上查到的资料基本上是单独描述这些名词概念,并没有与安全结合,所以稍作整理,也许有点分享价值;
问题:
问题一:CI/CD该如何理解,包含哪些过程及产出,会涉及哪些工具;
CI(Continuous Integration)持续集成,这里引用《持续集成是什么?》(作者:阮一峰)中的解释来看一下:
持续集成指的是,频繁地(一天多次)将代码集成到主干。
(1)快速发现错误。每完成一点更新,就集成到主干,可以快速发现错误,定位错误也比较容易。
(2)防止分支大幅偏离主干。如果不是经常集成,主干又在不断更新,会导致以后集成的难度变大,甚至难以集成。
持续集成的目的,就是让产品可以快速迭代,同时还能保持高质量。它的核心措施是,代码集成到主干之前,必须通过自动化测试。只要有一个测试用例失败,就不能集成。
Martin Fowler说过,"持续集成并不能消除Bug,而是让它们非常容易发现和改正。"
个人觉得CI可以直观的理解为包含:代码提交合并、build构建、打包出包(出包就是可以进行部署的文件,如jar、exe、docker镜像等等)的一个过程;
打包完成后的产物就可以进行部署,通俗来说 部署可以理解成将应用程序安装到服务器上运行,提供服务;
CD有两种解释,“持续交付”与“持续部署”,这里引用《持续集成是什么?》(作者:阮一峰)中的解释来看一下:
持续交付(Continuous delivery)指的是,频繁地将软件的新版本,交付给质量团队或者用户,以供评审。如果评审通过,代码就进入生产阶段。
持续交付可以看作持续集成的下一步。它强调的是,不管怎么更新,软件是随时随地可以交付的。
持续部署(continuous deployment)是持续交付的下一步,指的是代码通过评审以后,自动部署到生产环境。
持续部署的目标是,代码在任何时刻都是可部署的,可以进入生产阶段。
持续部署的前提是能自动化完成测试、构建、部署等步骤。
这里有个背景是:集成的工作一般会比较细碎繁琐,为了不影响开发效率,在以前,集成这个环节只会等到项目后期才进行,而不是频繁发生。但是如果等到后期才发现并解决问题,代价就很大,有可能导致项目延期或者失败(比如像安全漏洞这种高优问题~ :)。因此,为了尽早发现软件错误,应当鼓励团队成员应该经常集成他们的工作,通常每个成员每天应该至少集成一次。这就是所说的持续集成。所以说,持续集成是一种软件开发实践。这一点上与我们所说的sdl/devsecops是相似的,都是讲求项目质量把控;
那CICD,说白了还是在多人合作的工程化项目中,在集成、部署时产生了众多问题,比如合并提交代码,涉及不同的代码分支、随时的提交、合并、发布、部署产生的bug等,这些集成或部署工作以前是由人工完成的。但是现在鼓励持续集成,那岂不是要累死人,还影响开发效率。所以希望实现自动化的软件集成解决方案,也就是持续集成系统CICD;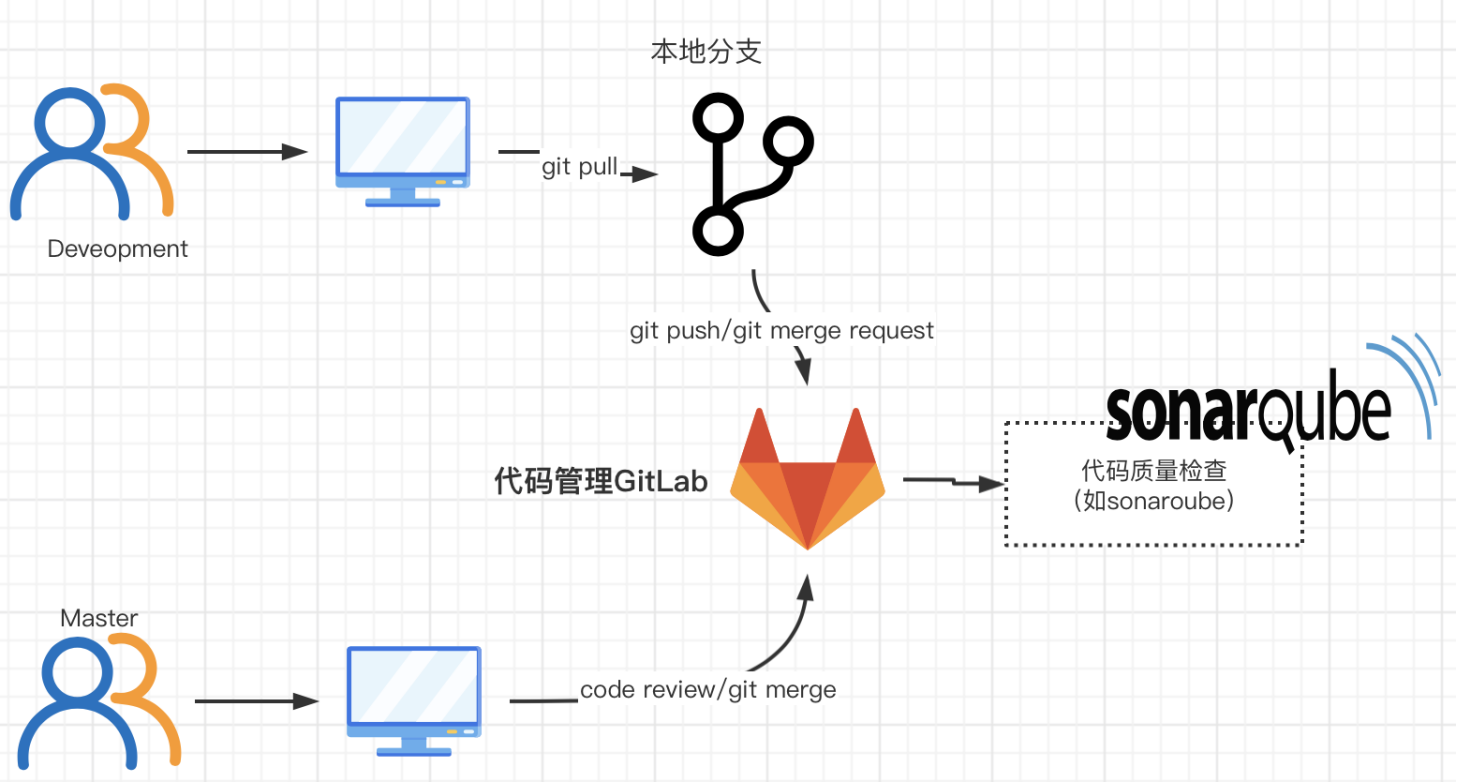
要实现持续集成、持续交付、持续部署,前提是要有相应的工具链来进行支撑(当然同时还需要研发流程的统一、涉及人员对工具流程的熟悉)
涉及到的流程及工具可以通过图示有更直观的理解: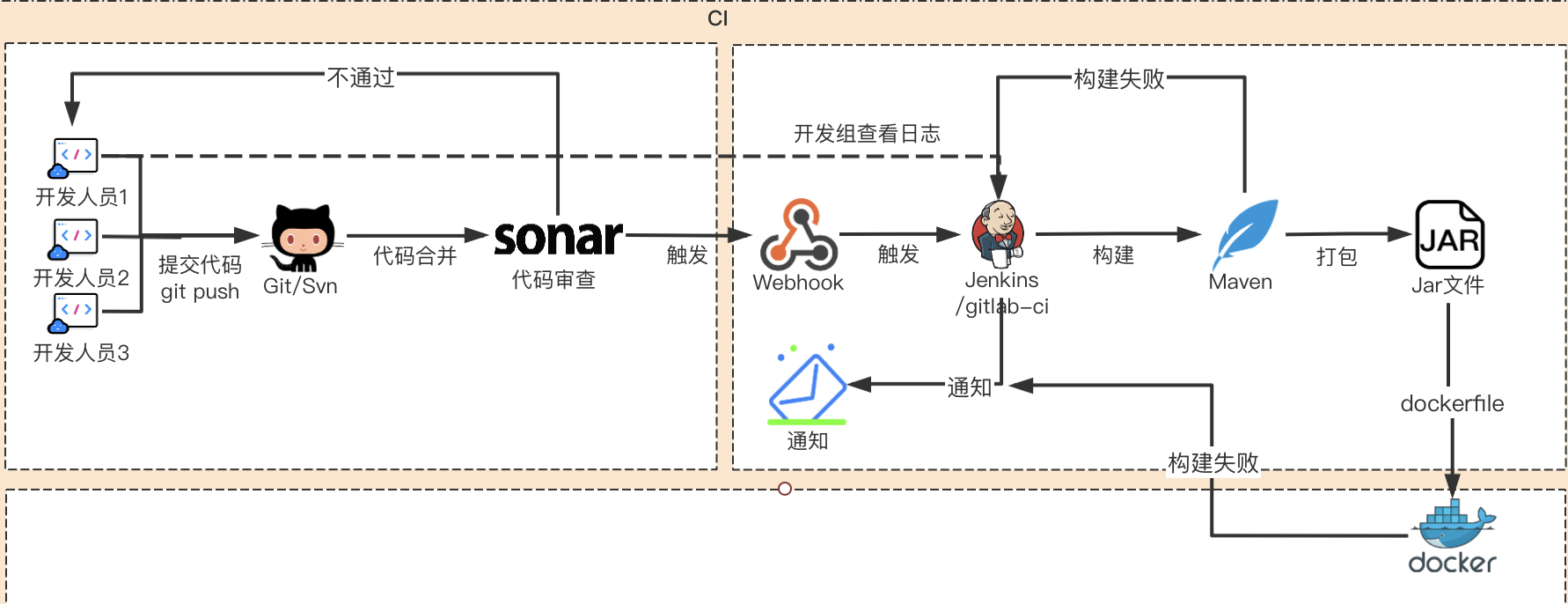
图一中的,代码管理平台就是代码仓库,具体有图二中的git或svn(其实SVN的年代已经过去了,现在更多是git,同时gitlab目前也提供了完善的CICD能力,有内置工具,如gitlab-ci,就可以替换上图中的Jenkins;另外gitlab UI可以将所有步骤可视化(包括质量检测、安全检测等),这样比起来,使用gitlab更丝滑~其完整的CICD工作流程如下图所示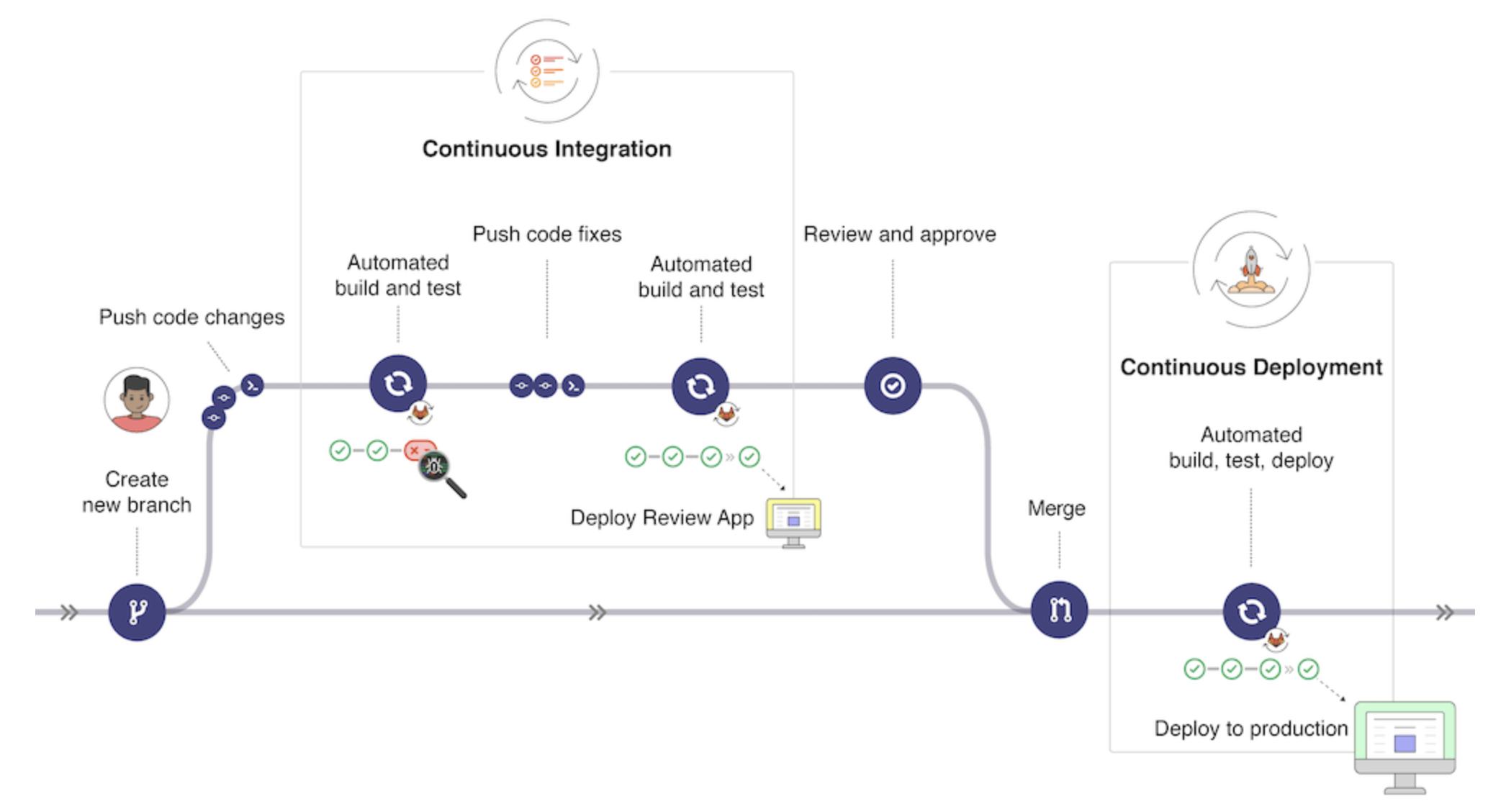
问题二 :三方包检测如何实现,在CICD中哪个阶段比较好;
首先 对于安全同学来说,三方包的实现机制应该还是比较清楚的:应用所依赖的三方库与漏洞库(cve、cnvd等)做对比,看是否有使用有漏洞的三方库版本;
这样拆分出三个需求:获得应用所依赖的三方库、获得漏洞库、做对比得出结果并通知修复;
这里主要说下第一个需求如何实现--获得应用所依赖的三方库:应用程序如果使用了开源三方库,一般会在配置文件中列出依赖包及其版本,所以最简单的方式就是去读取分析这个配置文件来获取依赖项信息;(当然还有二次依赖的问题,无法解决,这里不做讨论;题外话:sdl/devsecops建议先做覆盖率跑起来,再做优化)
不同的语言有不同的配置文件:
go.sum(golang),pom.xml(java-maven),bulid.gradle (java-gredle)、requirements.txt(python),package.json(nodejs),composer.lock(php);
| 语言 | 配置文件 |
|---|---|
| golang | go.sum |
| java | pom.xml |
| java | bulid.gradle |
| python | requirements.txt |
| nodejs | package.json |
| php | composer.lock |
那在CICD的哪个阶段来实现呢,我们做sdl核心的思想是“安全左移”,要让研发同学尽早感知到安全问题,尽早解决,从这个点来说当然是越早越好,比如在研发同学本地开发时,可以通过在本地环境中集成插件来实现,比如在maven项目中,可以在pom文件中增加配置即可,具体可以看https://yq.aliyun.com/articles/698621;
但这个方法不太好做做企业层面的推广,你无法要求每个人都在自己的本地环境/本地分支来增加配置,这种方式在个人开发或小团队比较适用(这种场景一般也不会有CICD啦~)
如果在build构建时进行检测,对于项目成员来说会觉得有点晚了,因为此时已经要打包了,再回头去改就比较麻烦;
对我们来说最合适的是在commit阶段,代码提交到代码管理平台(对我们来说是gitlab仓库)时就触发,研发同学就能知道并有时间作出及时的更新;这样是符合安全左移,也符合CI的思想:“快速发现错误。每完成一点更新,就集成到主干,可以快速发现错误,定位错误也比较容易。”
我们也是经过了几种方式的变动尝试得出了适合我们的方式,大家可以根据自己的实际情况来制定;
问题三:“工具侧同学说的gitlab-ci、runner、.gitlab-ci.yml、pipeline又是什么,安全检测与这些又是什么关系”
在明确了检测机制、确定了检测节点,需要在CICD/devops工具链中集成实现,这个时候需要跟平台工具侧同学沟通,就需要了解CICD的基本知识和实现机制:CICD是基于自动化脚本的,那如何将这个脚本串联触发,最终形成“持续”的效果?那就是如Jenkins的job概念、如gitlab-ci中的runner、.gitlab-ci.yml、pipeline这些概念;
这里主要说下gitlab-ci相关的:(网上资料较多,这里概括说一下)
- pipeline:是一个概念--任务流,没有具体的实体;在gitlab侧边栏中是可以看到这个的,其实就是构建中的阶段(stages)集合,比如自动构建、自动进行单元测试、代码审计等等,会按照顺序执行,所有阶段(stages)执行成功后,才算构建任务(pipeline)执行成功,如果某一个stage失败,后续不再执行,构建任务失败;而一个阶段(stage)可以包含多个job,这些job可以并行执行,某个失败即stage失败;这些stages、job都是定义在.gitlab-ci.yml中的;
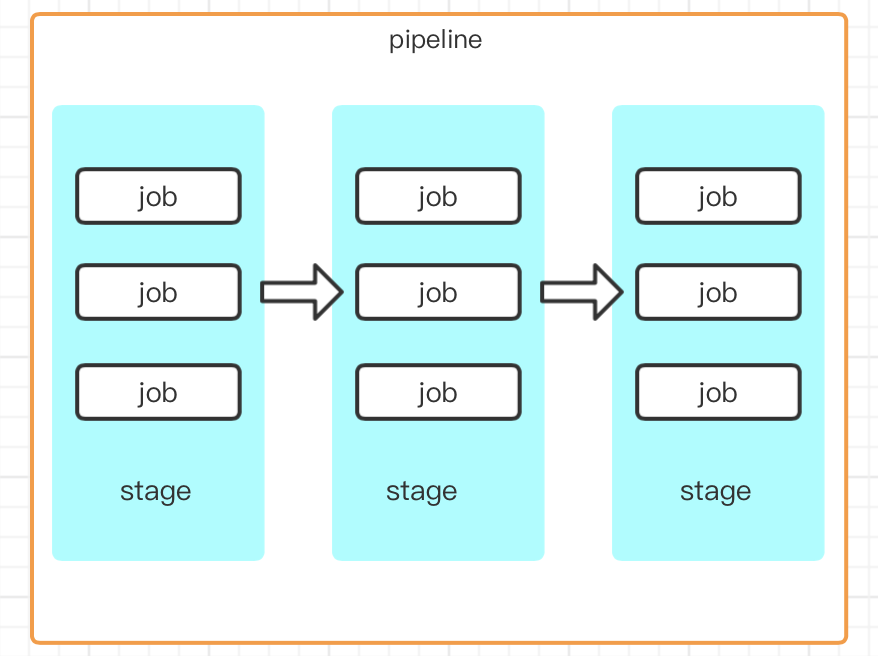 * runner:一般每个gitlab工程都会定义一个属于这个工程的软件集成脚本,用来自动化的完成软件集成工作,而gitlab-runner就是用来执行这些脚本的,可理解为jobs的执行器;使用Runner需要进行安装和注册,我们这里知道有这样的一个机制就好,具体的方法可以看这篇文章https://www.cnblogs.com/cnundefined/p/7095368.html 讲的非常详细了;
* runner:一般每个gitlab工程都会定义一个属于这个工程的软件集成脚本,用来自动化的完成软件集成工作,而gitlab-runner就是用来执行这些脚本的,可理解为jobs的执行器;使用Runner需要进行安装和注册,我们这里知道有这样的一个机制就好,具体的方法可以看这篇文章https://www.cnblogs.com/cnundefined/p/7095368.html 讲的非常详细了; - .gitlab-ci.yml:用来指定构建、测试和部署流程、以及CI触发条件的脚本,Gitlab检测到.gitlab-ci.yml文件,若当前提交(commit)符合文件中指定的触发条件,则会使用配置的gitlab-runner服务运行该脚本进行测试等工作;存在于项目根目录下;
示例如下
stages:
- build
- test
- deploy
# 定义 job(任务)
job1:
stage: test
tags:
- XX #只有标签为XX的runner才会执行这个任务
only:
- dev #只有dev分支提交代码才会执行这个任务。也可以是分支名称或触发器名称
- /^future-.*$/ #正则表达式,只有future-开头的分支才会执行
script:
- echo "I am job1"
- echo "I am in test stage"
# 定义 job
job2:
stage: test #如果此处没有定义stage,其默认也是test
only:
- master #只有master分支提交代码才会执行这个任务
script:
- echo "I am job2"
- echo "I am in test stage"
allow_failure: true #允许失败,即不影响下步构建
# 定义 job
job3:
stage: build
except:
- dev #除了dev分支,其它分支提交代码都会执行这个任务
script:
- echo "I am job3"
- echo "I am in build stage"
when: always #不管前面几步成功与否,永远会执行这一步。它有几个值:on_success (默认值)on_failurealwaysmanual(手动执行)
# 定义 job
.job4: #对于临时不想执行的job,可以选择在前面加个".",这样就会跳过此步任务,否则你除了要注释掉这个jobj外,还需要注释上面为deploy的stage
stage: deploy
script:
- echo "I am job4"
# 模板,相当于公用函数,有重复任务时很有用
.job_template: &job_definition # 创建一个锚,'job_definition'
image: ruby:2.1
services:
- postgres
- redis
test1:
<<: *job_definition # 利用锚'job_definition'来合并
script:
- test1 project
test2:
<<: *job_definition # 利用锚'job_definition'来合并
script:
- test2 project
#下面几个都相当于全局变量,都可以添加到具体job中,这时会被子job的覆盖
before_script:
- echo "每个job之前都会执行"
after_script:
- echo "每个job之后都会执行"
variables: #变量
DATABASE_URL: "postgres://postgres@postgres/my_database" #在job中可以用${DATABASE_URL}来使用这个变量。常用的预定义变量有CI_COMMIT_REF_NAME(项目所在的分支或标签名称),CI_JOB_NAME(任务名称),CI_JOB_STAGE(任务阶段)
GIT_STRATEGY: "none" #GIT策略,定义拉取代码的方式,有3种:clone/fetch/none,默认为clone,速度最慢,每步job都会重新clone一次代码。我们一般将它设置为none,在具体任务里设置为fetch就可以满足需求,毕竟不是每步都需要新代码,那也不符合我们测试的流程
cache: #缓存
#因为缓存为不同管道和任务间共享,可能会覆盖,所以有时需要设置key
key: ${CI_COMMIT_REF_NAME} # 启用每分支缓存。
#key: "$CI_JOB_NAME/$CI_COMMIT_REF_NAME" # 启用每个任务和每个分支缓存。需要注意的是,如果是在windows中运行这个脚本,需要把$换成%
untracked: true #缓存所有Git未跟踪的文件
paths: #以下2个文件夹会被缓存起来,下次构建会解压出来
- node_modules/
- dist/
以我们的三方库漏洞检测为例,就需要添加如下示例代码,以java-maven项目为例
stages:
- build
variables:
PROJECT_NAME: xxx.test
# 需要发送的安全依赖文件 pom.xml
DEPEND_FILE: pom.xml
build:
stage: build
tags:
- rider-shared-shell
script:
# 发送安全依赖文件 执行xxx(检测、通知)
- file=` $DEPEND_FILE `
- echo xxx
only:
- branches
- tags
很多场景下,写配置文件都用YML,也有YML工程师的戏称;
以上基本就是三方库漏洞检测落地推广时涉及到CICD相关的一些基础知识、问题和解决思路,
“如何将安全契合进研发”,这个问题以及解决逻辑会一直伴随SDL/Devsecops的推动落地,理解这些有助于我们落地,推广;
希望对SDL萌新们有所帮助吧~