Facebook为了解决海量日志数据的分析而开发了hive,后来开源给了Apache基金会组织。 hive是一种用SQL语句来协助读写、管理存储在HDFS上的大数据集的数据仓库软件。
Hive 特点
1 是基于 Hadoop 的一个数据仓库工具;
2 Hive 最大的特点是将 Hive SQL语句转换为 MapReduce、Tez 或者 spark 等任务执行,使得大数据分析更容易。
3 可以将结构化的数据映射为一张数据库表,库和表的元数据信息一般存在关系型数据库上(比如MySQL);
4 底层数据是存储在 HDFS 上,hive本身并不提供数据的存储功能;
5 数据存储方面:他能够存储很大的数据集,并且对数据完整性、格式要求并不严格;
6 数据处理方面:不适用于实时计算和响应,使用于离线分析。
为什么使用Hive
1 直接使用 MapReduce、Tez、Spark学习成本太高,因为需要了解底层具体执行引擎的处理逻辑,而且需要一定的编码基础;而Hive提供直接使用类sql语言即可进行数据查询和处理的平台或接口,只要使用者熟悉sql语言即可;
2 MapReduce、Tez、Spark实现复杂查询逻辑开发难度大,因为需要自己写代码实现整个处理逻辑以及完成对数据处理过程的优化,而hive将很多数据统计逻辑封装成了可直接使用的窗口函数,且支持自定义窗口函数来进行扩展,而且hive有逻辑和物理优化器,会对执行逻辑进行自动优化。
Hive 架构
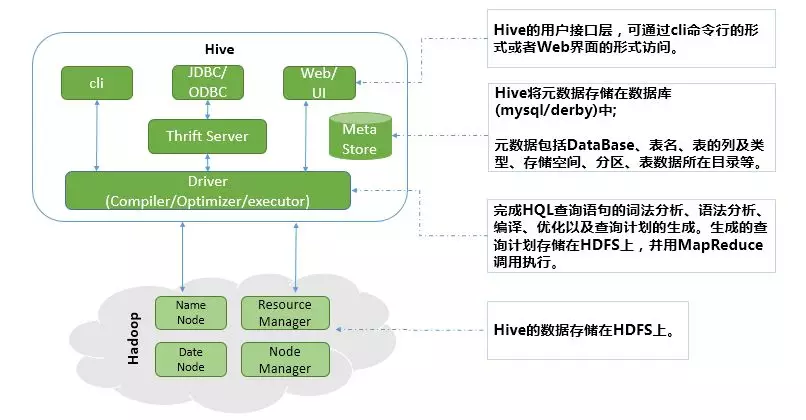
Hive的内部架构总共分为四大部分:
1 用户接口层(cli、JDBC/ODBC、Web UI)
(1) cli (Command Line Interface),shell终端命令行,通过命令行与hive进行交互;
(2) JDBC/ODBC,是 Hive 的基于 JDBC 操作提供的客户端,用户(开发员,运维人员)通过客户端连接至 Hive server 服务;
(3) Web UI,通过浏览器访问hive。
2 元数据存储系统
(1) 元数据 ,通俗的讲,就是存储在 Hive 中的数据的描述信息;
(2) Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和 外部表),表中数据所在的目录;
(3) Metastore 默认存在自带的 Derby 数据库或者我们自己创建的 MySQL 库中;
(4) Hive 和 MySQL或Derby 之间通过 MetaStore 服务交互。
3 Thrift Server-跨语言服务
Hive集成了Thrift Server,让用户可以使用多种不同语言来操作hive。
4 Driver(Compiler/Optimizer/Executor)
Driver完成HQL查询语句的词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS上,并由MapReduce调用执行。
整个过程的执行步骤如下:
(1) 解释器完成词法、语法和语义的分析以及中间代码生成,最终转换成抽象语法树;
(2) 编译器将语法树编译为逻辑执行计划;
(3) 逻辑层优化器对逻辑执行计划进行优化,由于Hive最终生成的MapReduce任务中,而Map阶段和Reduce阶段均由OperatorTree组成,所以大部分逻辑层优化器通过变换OperatorTree,合并操作符,达到减少MapReduce Job和减少shuffle数据量的目的;
(4) 物理层优化器进行MapReduce任务的变换,生成最终的物理执行计划;
(5) 执行器调用底层的运行框架执行最终的物理执行计划。
Hive 数据组织
1 Hive 的存储结构包括 数据库、表、视图、分区和表数据 等。数据库,表,分区等都对应HDFS上的一个目录。表数据对应 HDFS 对应目录下的文件。
2 Hive 中包含以下数据模型:
database:在 HDFS 中表现为${hive.metastore.warehouse.dir}或者指定的目录下的一个文件夹; table :在 HDFS 中表现为某个 database目录下一个文件夹; external table :与 table 类似,在 HDFS 中也表现为某个 database目录下一个文件夹; partition :在 HDFS 中表现为 table目录下的子目录; bucket :在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件; view :与传统数据库类似,只读,基于基本表创建。
3 Hive 中的表分为内部表、外部表、分区表和 Bucket 表。
内部表和外部表的区别:
1.内部表数据由Hive自身管理,外部表数据由HDFS管理;
2.删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
分区表和分桶表的区别:
1.分区表,Hive 数据表可以根据某些字段进行分区操作,细化数据管理,让部分查询更快;
2.分桶表:表和分区也可以进一步被划分为桶,分桶表中的数据是按照某些分桶字段进行 hash 散列形成的多个文件。
Hive 数据类型
1 Hive的内置数据类型可以分为两大类
① 基础数据类型包括:TINYINT、SMALLINT、INT、BIGINT、BOOLEAN、FLOAT、DOUBLE、STRING、BINARY、TIMESTAMP、DECIMAL、CHAR、VARCHAR、DATE。
② 复杂类型包括ARRAY、MAP、STRUCT、UNION,这些复杂类型是由基础类型组成的。
数据类型 所占字节 开始支持版本 TINYINT 1byte: -128 ~ 127 SMALLINT 2byte:-32,768 ~ 32,767 INT 4byte:-2,147,483,648 ~ 2,147,483,647 BIGINT 8byte:-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807BOOLEAN FLOAT4byte单精度 DOUBLE8byte双精度 STRING BINARY 从Hive0.8.0开始支持 TIMESTAMP 从Hive0.8.0开始支持 DECIMAL 从Hive0.11.0开始支持 CHAR 从Hive0.13.0开始支持 VARCHAR 从Hive0.12.0开始支持 DATE 从Hive0.12.0开始支持
2 Hive表结构中的数据类型与MySQL对应列有如下关系
MySQL(bigint) --> Hive(bigint) MySQL(tinyint) --> Hive(tinyint) MySQL(int) --> Hive(int) MySQL(double) --> Hive(double) MySQL(bit) --> Hive(boolean) MySQL(varchar) --> Hive(string) MySQL(decimal) --> Hive(decimal) MySQL(date/timestamp) --> Hive(date) MySQL(timestamp) --> Hive(timestamp) 注: Mysql[decimal(12,2)]-->Hive[decimal]会导致导入后小数丢失
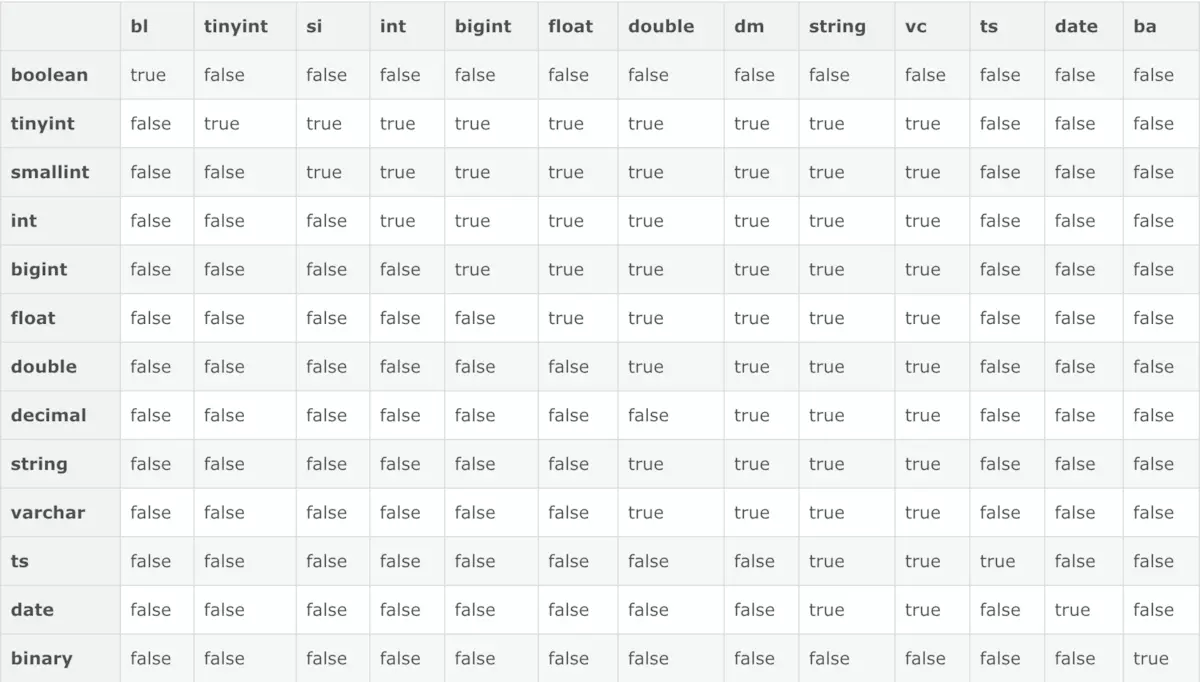
3 数据类型转化关系表
Hive DDL操作
1 存储格式:
压缩表和非压缩表
- textfile是Hive建表时默认使用的存储格式,数据不做压缩,本质上textfile就是以文本的形式将数据存放在hdfs中。
- orcfile 列式存储格式,查询更快。
2 表类型:
2.1 分区表和非分区表,分桶表
一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下
2.2 外部表和内部表
- 管理表 默认创建的表都是管理表,也被称为内部表,删除管理表时,Hive 也会删除这个表中数据
- 外部表 删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉
3 hive -f/-e操作
hive -f 后面指定的是一个文件,然后文件里面直接写sql
hive -e 后面是直接用双引号拼接hivesql,然后就可以执行命令
4 建库
4.1 创建库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS]database_name [COMMENT database_comment] //关于数据块的描述 [LOCATION hdfs_path] //指定数据库在HDFS上的存储位置 [WITH DBPROPERTIES (property_name=property_value, ...)]; //指定数据块属性
4.2 查看有哪些数据库
dfs -ls /hive/warehouse/; show databases;
4.3 显示数据库的详细属性信息
desc database [extended] dbname;
4.4 查看正在使用哪个库
select current_database();4.5 查看创建库的详细语句
show create database t3;
4.6 删库(默认情况下,hive 不允许删除包含表的数据库, 使用 cascade 关键字)
drop database if existsdbname; drop database if exists dbname cascade;
4.7 切换库
use database_name;5 建表
5.1 创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS]table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTOnum_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]; •CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOTEXIST 选项来忽略这个异常 •EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION) •LIKE允许用户复制现有的表结构,但是不复制数据 •COMMENT可以为表与字段增加描述 •PARTITIONED BY指定分区 •ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候, 用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。 •STORED ASSEQUENCEFILE //序列化文件 | TEXTFILE //普通的文本文件格式 | RCFILE //行列存储相结合的文件 | INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname //自定义文件格式 如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED ASSEQUENCE 。 •LOCATION指定表在HDFS的存储路径
5.2 创建内部表
create tablestudent( id int, name string ) row format delimited fields terminated by "001" stored as textfile;
5.3 创建外部表
create external tablestudent_ext( id int, name string ) row format delimited fields terminated by"," location "/hive/student";
5.4 创建分区外部表
如果不指定数据库,hive会把表创建在default数据库下。分区表现为这张表的数据存储目录下的一个子目录,如果是分区表。那么数据文件一定要存储在某个分区中,而不能直接存储在表中。
create external tabletmp.table_add_column_test( a string comment '原始数据1', b string comment '原始数据2') comment '表注释'partitioned by(dt string) row format delimited fields terminated by '