元数据:描述数据的数据
三类:
数据库元数据、参数元数据、结果集元数据
1.数据库元数据 DataBaseMetaData Connection->DataBaseMertaData->.


Class.forName(DRIVER);
Connection connection = DriverManager.getConnection(URL, USERNAME, PASSWORD);
//数据库元信息
DatabaseMetaData dbMetaData = connection.getMetaData();
String dbName = dbMetaData.getDatabaseProductName();
System.out.println("数据库名"+dbName);
String dbversion = dbMetaData.getDatabaseProductVersion();
System.out.println("数据库版本"+dbversion);
String driverName = dbMetaData.getDriverName();
System.out.println("数据库驱动名"+driverName);
String url = dbMetaData.getURL();
System.out.println(url);
String userName = dbMetaData.getUserName();
System.out.println(userName);
System.out.println("---------------");
ResultSet rs = dbMetaData.getPrimaryKeys(null, userName, "STUDENT");
while (rs.next()){
Object tableName=rs.getObject(3);
Object columName=rs.getObject(4);
Object pkName=rs.getObject(4);
System.out.println(tableName+"--"+columName+"--"+pkName);
}
2.参数元数据 ParameterMetaData pstmt->ParameterMetaData->.

Class.forName(DRIVER);
Connection connection = DriverManager.getConnection(URL, USERNAME, PASSWORD);
PreparedStatement pstmt = connection.prepareStatement("select * from student where sno=? and sname=?");
//通过pstmt获取参数元数据
ParameterMetaData metaData = pstmt.getParameterMetaData();
int count=metaData.getParameterCount();
System.out.println("参数个数:"+count);
for(int i=1;i<=count;i++){
String typeName = metaData.getParameterTypeName(i);
System.out.println(typeName);
}
3.结果集元数据 ResultSetMetaData ResultSet->ResultSetMetaData
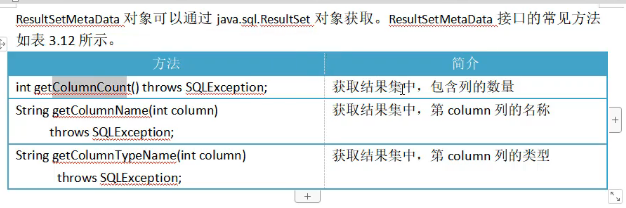
Class.forName(DRIVER);
Connection connection = DriverManager.getConnection(URL, USERNAME, PASSWORD);
PreparedStatement pstmt = connection.prepareStatement("select * from student");
ResultSet rs=pstmt.executeQuery();
ResultSetMetaData metaData = rs.getMetaData();
int count = metaData.getColumnCount();
System.out.println("列的个数"+count);
System.out.println("----");
for (int i=1;i<=count;i++){
String columnName = metaData.getColumnName(i);
String columnTypeName = metaData.getColumnTypeName(i);
System.out.println(columnName+" "+columnTypeName);
}
while (rs.next()){
for (int i=1;i<=count;i++){
System.out.print(rs.getObject(i)+" ");
}
System.out.println();
}
