哈希表
先从数组说起
任何一个程序员,基本上对数组都不会陌生,这个最常用的数据结构,说到它的优点,最明显的就是两点:
- 简单易用,数组的简易操作甚至让大多数程序员依赖上了它,在资源富足的情况下,我们甚至会无意识地忽略其它更适用的数据结构而使用数组(别说你没这么干过..)。
- 查找的快速性,数组中查找元素可以直接通过下标进行定位,速度快。
我在刚开始写程序的时候,也会经常用到数组,而且往往数组中的元素都是预定义好的,当元素少的时候,常用的做法是使用宏定义来定义下标:
#define ZHANGSAN 0
#define LISI 1
...
这样,就可以通过ZHANGSAN这个宏定义作为下标访问到"张三"。我们就产生了一种数组就是这么使用的错觉。
但是,如果数组内的元素是预先不知情的,或者数量庞大呢?宏定义这种做法明显不再合适了。
比如要存储学生相关信息时,便使用结构体数组,在查找时就轮询每一个结构体中"学号"字段,来判断是否命中。在这种情况下,数组就完全失去了快速查找的优势。
hash函数的使用
其实,在上述情况中,我们需要解决的问题就是建立 "元素和数组下标" 之间的映射关系,hash函数就担任了这么一个角色(但是hash函数并不仅仅在hash表中使用)。
哈希函数到哈希表
hash函数,又称为散列函数,但是这个hash函数并没有什么统一标准,它的核心思想就是就是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。
这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数,这个消息可能是字符、数组、字符串等等。
拥有这样的hash存储结构的数据结构称为散列表,或者叫哈希表。
哈希表一般基于数组实现,特定情况下结合链表,但是数组是哈希表基础数据结构。
示例
定义总是臭又长,我们来举个例子:有100个学生,我们需要用一个容量为100的哈希表来存下他们的信息,使用他们的名字来进行hash计算,输出0-99的下标值,我们可以这样,我们可以尝试定义这样一个最简单的hash函数:
int hash_func(char* name)
{
sum = name中每个字符值相加
return sum%100
}
这是个非常简单的hash函数实现,每个名称都会对应返回0-99的数组下标。
但是细心的朋友肯定能发现其中的问题:这个函数并不能保证每个name计算出来的值都不一样,100个学生刚好填满哈希表,而且还不考虑重名的情况,如果两个名字计算出来的hash值相同,这就产生了冲突,毕竟一个坑只能放一个萝卜。
很显然,这是个"很烂"的hash函数。(事实上我们并不能撇开应用场景来单纯地判断一个hash函数的好坏,在某些情况下,线性映射能达到很好的效果,而某些情况下需要更复杂的hash函数)。
hash函数的要求
那么,一个hash函数需要满足什么要求呢?
- 接受一个单一的参数,这个参数可以是任何类型,但是只能是一个
- 返回一个整型值(一般情况下)
- 不抛出异常
- 对于两个相同的输入,输出必须相同
- 对于两个不同的输入,输出相同的概率需要做到非常小。
- hash的计算不能过于复杂,时间复杂度尽可能地低。
常用的hash函数
既然自己想不到比较好的hash算法,我们就来看看别人是怎么做的吧,下面是一些常用的hash算法:
直接定址法
取key的线性函数值作为hash值,value = a * key + b,a,b为常数。这一类散列码的特点是:对输入为整型数据而言,不会产生下标冲突。不产生冲突当然是最完美的状态,但是这种方式要求输入的key遵循一定的线性规律。
除留余数法
除留余数法:假设数组的长度为l,value = key % l,这一种散列码实现简单,运用比较多,但是如果输入的元素集合不具有一定的规律,比较容易产生冲突。数组的长度最好是质数,被除数为质数在一定程度上可以缓解数据堆积的问题。
数字分析法
数字分析法即对关键字进行分析,取关键字的若干位进行或者组合进行hash计算,这一类散列码的特点是比较灵活,通常是结合其他hash函数来计算,可根据实际情况来做出调整,具有想当的灵活性。
平方取中法
取关键字平方后中间几位作哈希地址。适于关键字长度不统一的情况,而且对于元素连续的输入,可以很好的将其散列均匀,而且相对于除法而言,乘法的执行速度更快,这个由硬件决定。
处理冲突的方法
从hash函数的要求可以看到,事实上我们只能定义对于两个不同的输入,输出相同的概率尽可能小,而不能做到完全杜绝冲突,所以我们必须提前想好处理冲突的措施。
开放定址法
开放地址法是比较常用的处理冲突算法之一,通常分为几种:
- 线性探测:当需要插入的元素发现与已有元素下标冲突时,就依次往后遍历,直到找到一个空槽,这时候将元素插入进去,由此可以看出,插入的操作非常简单。
但是如果我要查找一个元素时,将Key经过hash运算之后得到的hash值作为下标找到的不一定是对应的元素(因为插入时的冲突导致往后移),这时候有几种处理方案:
* 在只增不删的hash表中,从计算出的hash下标处往后一个一个进行对比(对比函数就是用的key_equal()函数),直到找到元素或者找到一个空槽表示未找到,因为冲突时都是往后一个槽一个槽地找。
* 在可删除的hash表中,删除一个槽时,会导致中间有空槽存在,这个时候查找在插入时遇到冲突的元素的时候,最坏的情况下需要遍历整个hash表,才能确定是否存在。或者在删除时,将之前因冲突而放置在其他槽的元素取回,这里的操作较为复杂。
二次探测:在线性探测的基础上,从依次往后遍历变成按照 +(1²),+(2²),+(3²),+(4²)的规律进行探测,在线性探测的基础上,可以缓解数据堆积问题,提升效率,操作上一致。
伪随机数再散列:在线性探测的基础上,将往后遍历下标的值取一个伪随机数,并将伪随机数序列记录下来,以供查找时使用。
示例
插入时解决冲突
光说不练假把式,还是得通过具体的示例才能更清楚地理解这三种处理方式:
模拟一个商场会员管理系统,目前有以下会员信息:
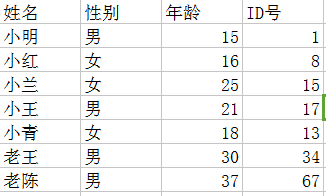
首先,我们选取ID号作为hash函数的输入,因为可能存在重复的人名,在前期我们就应该避免会引发冲突的情况。
然后选取一个hash函数,这里我们就选择一个简单的除留余数法,会员目标的信息是未知的,所以得定一个比当前数据量大一些的数组,数组大小为11(实际情况要大得多,虽然这很不符合实际情况,原谅我!这只是个简单示例!).而数组类型为结构体数组或者指针数组(数组元素都是指针,为了优化空间,当插入元素时再动态分配内存,指针放置在数组中)。
hash函数的实现如下:
int hash(int key){
return key%11;
}
好了 一切准备就绪,我们就可以开始了,为了大家的理解,我们先计算出来ID与下标的对应:

然后再一个个地插入元素,先插入小明,是这样的:

接着插入,插入完小青之后,是这样的:

接着插入老王和老陈,但是发现老王和老陈的hash值都是1,而且之前小明已经占了1的坑,这时候插入就要解决冲突。
线性探测解决冲突
老王需要写入的时候,发现1已经被小明占了,没办法,只好往后找位置,但是又发现2号下标被小青占了,只好再往后找,发现3号位置是空的,放在3号位置。
老陈进行同样的操作,发现234号位置都已经被占,放置在5号位置。这时候的表空间这样的:

二次探测解决冲突
老王要写入,1号被占用,看一下2号位置(1+1),发现被小青占了,继续看5(1+4)号,5号为空,放置在5号。
老陈进行同样的操作,1,2,5号被占用,再看10(1+9)号位置,10号位置为空,放置在10号。这时候的表空间是这样的:

伪随机再散列解决冲突
我们选取一个伪随机序列{2,5,9},
老王要写入,1号被占用,找到3(1+2)号,3号为空,放入3号位置。
老陈进行同样的操作,1,3号被占用,找到6(1+5)号,6号被占用,找到10(1+9)号,放置在10号,这时候的表空间是这样的:

实际情况是复杂多变的,博主也不指望一个简单的示例能代表所有情况,但是从这个示例还是可以看出,对于解决冲突,线性探测容易产生堆积,而二次探测可缓解堆积现象(乘法可以将间距放大)。而对于伪随机再散列,所产生的结果是不定的,因为谁也不知道生成的随机序列是否合适,但是一旦数据规模增大,这种方式更有优势,因为伪随机同时代表着分布均匀。
查找效率
别忘了,hash表建立的目的可不是为了插入,而是为了更方便地查找使用(增删改伴随着查找),那这三种方式的查找效率怎么样呢?
情况1:只支持查找、更改,不支持删除
查找其实就是按照插入的方式进行查找,在这里我们考虑一下比较极端的情况,如果我们要查找ID为67(老陈)的信息:
线性探测:老陈的hash计算后对应1号,对比之后发现1号并不是老陈的信息,往后一个个对比,如果遍历到空位置,表示表内没有对应,在这里,找到5号位置时,命中。
二次探测:与线性探测一致,只是将往后逐个遍历变成遍历1,5,10,如果遍历到空位置,表示表内没有对应,在这里找到10号位置时,命中。
伪随机再散列:同上,遍历1,3,10,如果遍历到空位置,表示表内没有对应,在这里找到10号位置,命中。
(可以想一想为什么遍历过程中遇到空位置时表示表内没有此元素)
情况2:同时支持增删改查
在可以删除的情况下,就更为复杂了,如果我们删除了ID为1(小明)的信息,这时候1号为空,查找老陈信息时就不能简单地依据遍历到空元素表示表内没有此元素。如果我们要查找一个ID的信息,而这个ID并不存在于这个表内,我们得遍历整个表才能确定.(或者可以置一些被删除的标志位来识别,但是当删除频繁时加大软件难度和出错概率)
有一种解决方案是,当我们删除一个元素时,将其他的冲突元素移回来,这样就可以保持 查找时以遍历到空元素来确定此元素不存在的属性了。
开放定址法总结
即使没有任何示例,从直觉上来看,上述三种方式处理冲突不够优雅,处理方式明显不适合大规模的数据存储,一旦数据规模增大,散列很可能出现多次冲突的情况,查找时的往后遍历所花费的时间是不可接受的,
同时,如果涉及到数据规模的增大,当面临几十上百K的数据规模时,因为数组的不可扩展性,我们在刚开始就得定义一个足够大(在不知道具体数据规模时甚至定义一个远大于数据规模)的数组以满足需求,又或者涉及到动态增长,这种存储方式对空间的浪费是非常严重的。
鉴于数组的不可扩展,内存连续的属性,这种hash表并不能满足大型数据规模的应用场景,那么有什么办法能解决数组空间的浪费以及扩展问题呢?
说到可扩展性,当然就应该想到链表!!!
链地址法
我们都知道链表的缺点是查找速度慢,一般情况下需要遍历链表进行查找,既然数组拥有查找速度快的优点,链表具有可扩展性好,空间利用率高的特点,那有没有一种东西既有数组查找的优点,又能继承链表的动态扩展性呢?
答案就是hash中的链地址法。
链地址法其实理解起来非常简单,数组中每一个元素通常放置一个链表头(也可以是栈或其他,取决于应用场景),然后将所有hash值一致的元素以节点的形式链接在链表后面,按照这种方式,上面的示例中结果是这样的:
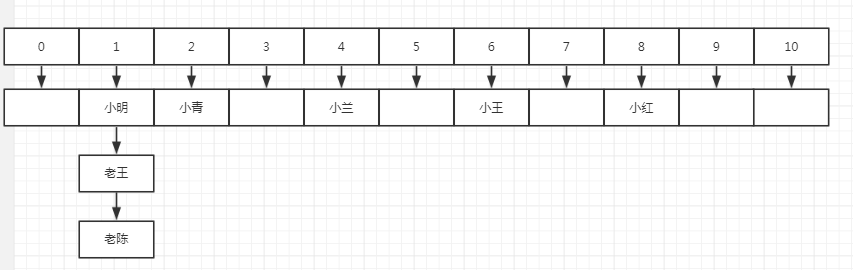
链地址法的优缺点
1、处理冲突简单,平均查找时间较短。
2、相比于数组的实现,链地址法的扩展性明显要更强
3、相对于开放定址法,定义的数组必须大于数据规模,容易造成浪费,而链地址法则不用,在一定程度上节省空间。但是开放定址法由于冲突时向后遍历的方式,更容易将数组填满,在这个角度上开放定址法更节省空间,所以在已知数据规模的情况下,且规模较小时,开放定址法比链地址法节省空间,链地址法的指针域同时会浪费一些空间。
4、更方便地支持增删改查操作。
不常用的方法
再建hash
在构造hash表时同时构造多个hash函数,当发生冲突时使用下一个hash函数,直到不发生冲突。这种处理方式与开放定址法相似,但是很明显的缺点是:在这种方式下,一旦发生冲突,将会有多次计算hash值的行为,甚至计算所带来的时间消耗反倒远远超过查找本身。
建立公共溢出区
将hash表分为基本表和冲突表,当元素发生冲突时,将冲突元素放入溢出表中。但是当发生重复冲突时,就会面临溢出区溢出的问题,这时候可能需要结合其他冲突处理方式再进行处理,如果每溢出一次,就建立一个新表,那对于空间的浪费也是不可接受的。
最好的冲突处理方式
其实最好的冲突处理方式应该是选择一个更好的hash函数,使元素对应hash值分布更为均匀,减少冲突的存在。防范大于救火!
C++ STL中unordered container的hash实现方式
在C++ STL中,unordered_map 和 unordered_set 解决冲突的方法即为链地址法。
bucket
在其提供的接口函数中,将所有hash值相同的元素放入同一个bucket,bucket与上述提到的链表相当,在这里可以理解为一种容器。
hash_func()
unordered_map 和 unordered_set对于很多内置类型和STL 容器有默认的hash函数,但用户也可以提供自己的hash函数。
key_equal()
如上所述,在查找时我们不能以hash值相同来判断两个key值相等,需要进行二次确认,即使用key_equal()函数判断两个key值是否完全相等。
小节
由于hash表的基础数据结构是数组,在查找时可以直接使用下标寻址,有查找速度非常快的特点,理想中的hash表查找的时间复杂度是O(1)。
但是,相比于同样在表单界十分受欢迎的红黑树而言,hash表依旧有着一些缺点:
- 不稳定,hash表极其依赖hash函数的表现,带来的结果就是在大型应用场景需要大量的时间测试和调试。
- 占用空间较多,容易造成空间浪费。
- 红黑树相对来说使用简单,不存在太多空间浪费问题,由于遵循二分查找法,在查找上的时间复杂度是O(logn),插入时最多对整棵树调整三次,由于其综合、稳定的性能,以及易用性,在实际应用中要比hash表受欢迎。
好了,关于hash表的讨论就到此为止啦,如果朋友们对于这个有什么疑问或者发现有文章中有什么错误,欢迎留言
原创博客,转载请注明出处!
祝各位早日实现项目丛中过,bug不沾身.