摘要:
如果您想使用plsql连接到Oracle,可以使用类似的工具连接到Impala:ClouderaImpalaODBC32.msi下载地址:http://www.cloudera.com/downloads/connectors/impala/odbc/2-5-36.html--注意:不能使用64位,否则稍后使用SqlDbx.exe连接到odbs时将报告错误!(未验证)1。Win7双击安装:Clouder
想要使用plsql连接oracle一样,使用类似工具连接impala的方法:
ClouderaImpalaODBC32.msi
下载地址:http://www.cloudera.com/downloads/connectors/impala/odbc/2-5-36.html
--注意:不能使用64位的,否则后面使用SqlDbx.exe连接odbs时候会报错!(未验证)
1、Win7双击安装:ClouderaImpalaODBC32.msi
2 、开始—>所有程序—>Cloudera ODBC Driver for Impala-->32-bit ODBC Administrator
3、配置数据源:
选择用户DSN-->点击添加
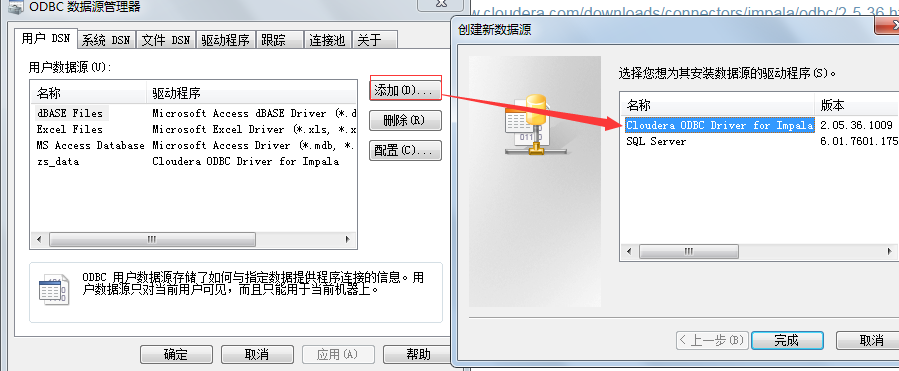
点击完成:
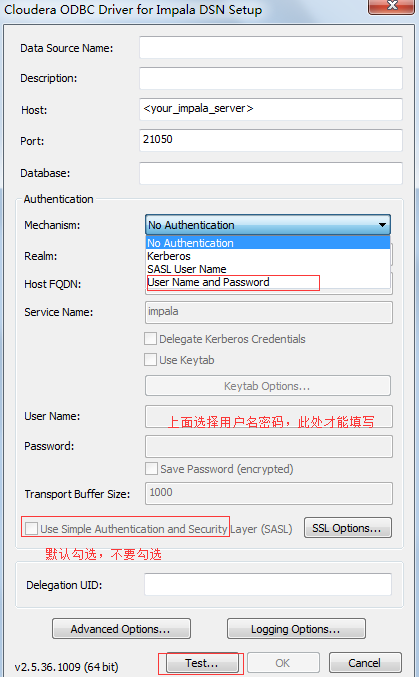
点击测试是否能链接成功,若提示success则表示链接成功,点击ok
4、数据源配置完成后,使用SqlDbx.exe 工具连接impala
SqlDbx下载地址:http://www.sqldbx.com/personal_edition.htm
下载完成后直接解压双击SqlDbx.exe打开
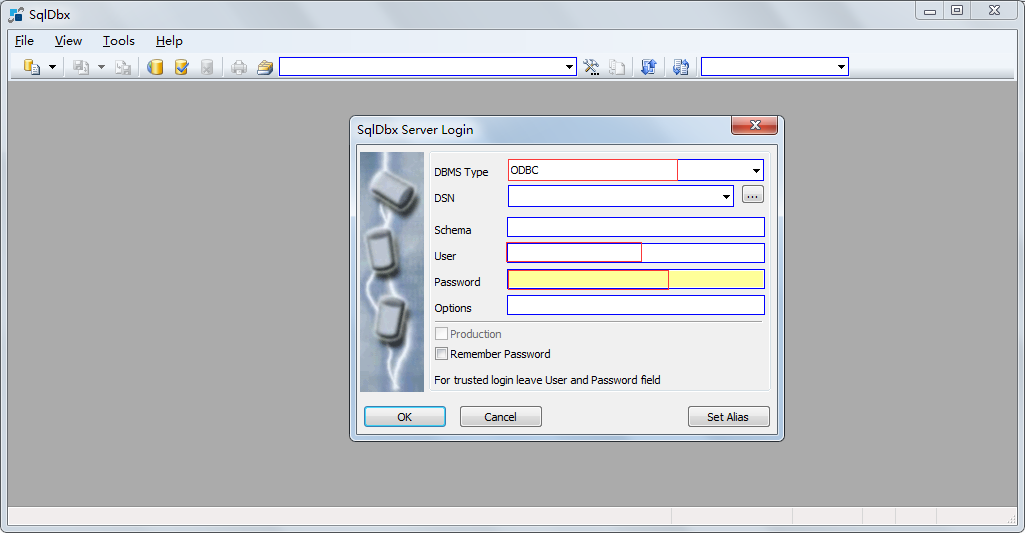
DBMS type选择ODBC,下面填写数据库用户名和密码即可