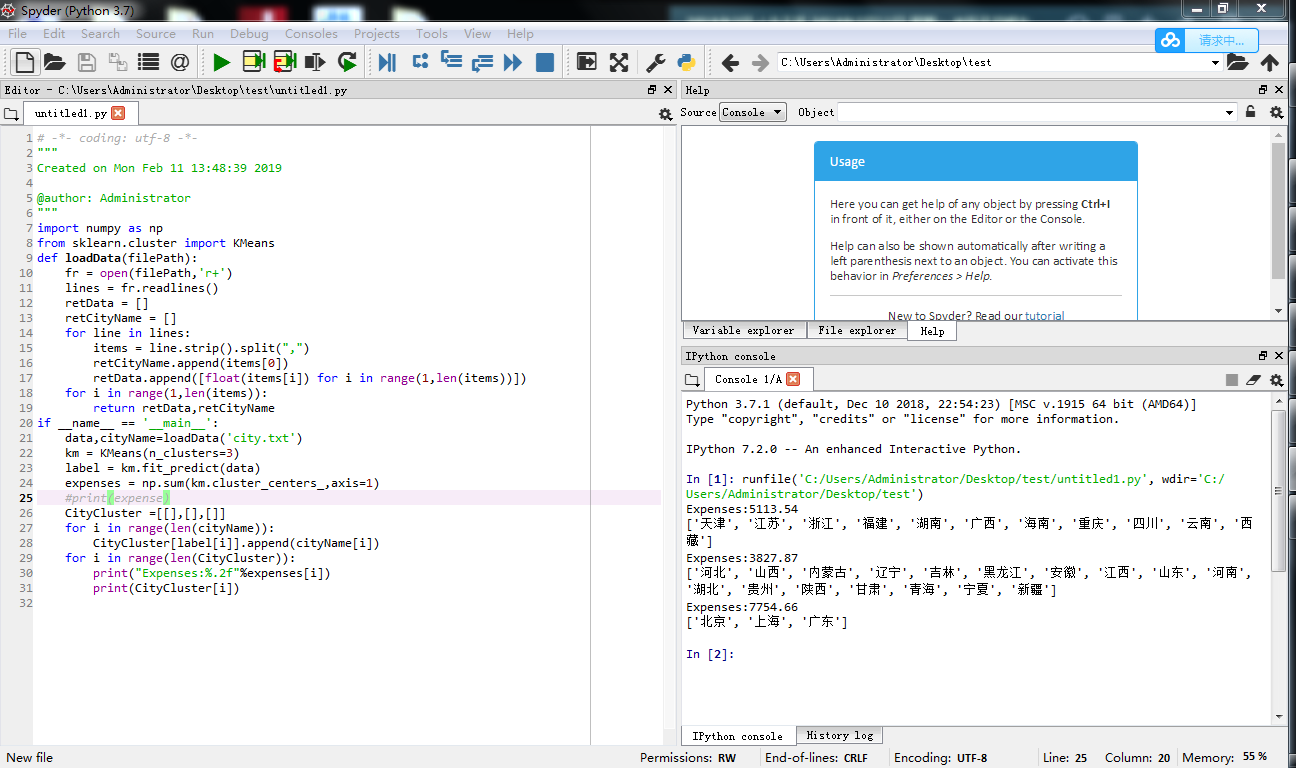
===分三类的=====
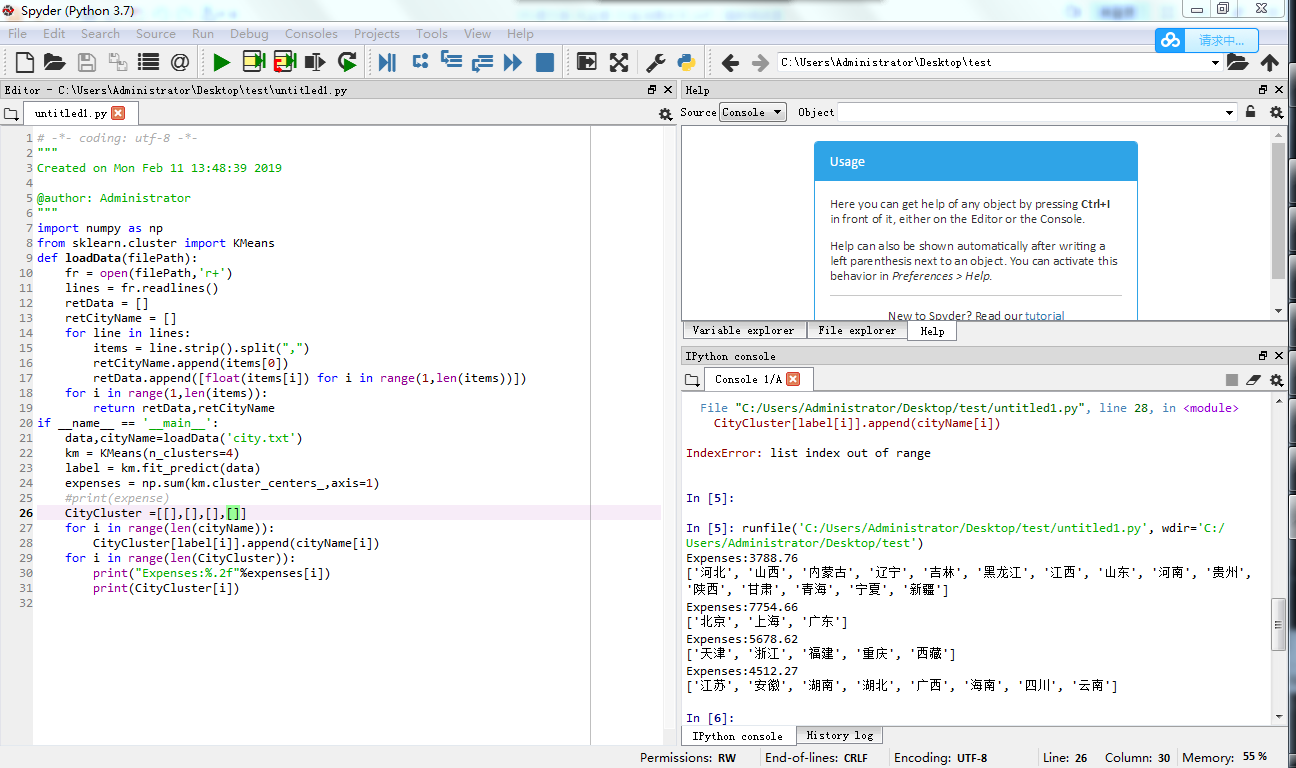
======分四类的========
直接写文件名,那么你的那个txt文件应该是和py文件在同一个路径的
============code===========
import numpy as np
from sklearn.cluster import KMeans
def loadData(filePath):
fr = open(filePath,'r+')
lines = fr.readlines()
retData = []
retCityName = []
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append([float(items[i]) for i in range(1,len(items))])
for i in range(1,len(items)):
return retData,retCityName
if __name__ == '__main__':
data,cityName=loadData('city.txt')
km = KMeans(n_clusters=3)
label = km.fit_predict(data)
expenses = np.sum(km.cluster_centers_,axis=1)
#print(expense)
CityCluster =[[],[],[]]
for i in range(len(cityName)):
CityCluster[label[i]].append(cityName[i])
for i in range(len(CityCluster)):
print("Expenses:%.2f"%expenses[i])
print(CityCluster[i])
=========
- importnumpyasnp
- fromsklearn.clusterimportKMeans
- defloadData(filePath):
- fr=open(filePath,'r+')
- lines=fr.readlines()
- retData=[]
- retCityName=[]
- forlineinlines:
- items=line.strip().split(",")
- retCityName.append(items[0])
- retData.append([float(items[i])foriinrange(1,len(items))])
- returnretData,retCityName
- if__name__=='__main__':
- data,cityName=loadData('city.txt')
- km=KMeans(n_clusters=4)
- label=km.fit_predict(data)
- expenses=np.sum(km.cluster_centers_,axis=1)
- #print(expenses)
- CityCluster=[[],[],[],[]]
- foriinrange(len(cityName)):
- CityCluster[label[i]].append(cityName[i])
- foriinrange(len(CityCluster)):
- print("Expenses:%.2f"%expenses[i])
- print(CityCluster[i])