聚集索引与非聚集索引的区别:
- 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。
- 聚集索引的叶节点就是最终的数据节点,而非聚集索引的叶节仍然是索引节点,但它有一个指向最终数据的指针。
- 使用聚集索引来做查询操作时速度很快,但是做插入操作时就较为费时。
InnoDB支持聚集索引,MyISAM不支持聚集索引。InnoDB按照主键进行聚集,如果没有定义主键,InnoDB会试着使用唯一的非空索引来代替。如果没有这种索引,InnoDB就会定义隐藏的主键然后在上面进行聚集。
MySQL中如果定义了主键,那么聚集索引就是主键。
MySQL的索引分为B+树索引和hash索引与全文索引。MyISAM数据库引擎和InnoDB数据库引擎的索引都是基于B+树的。
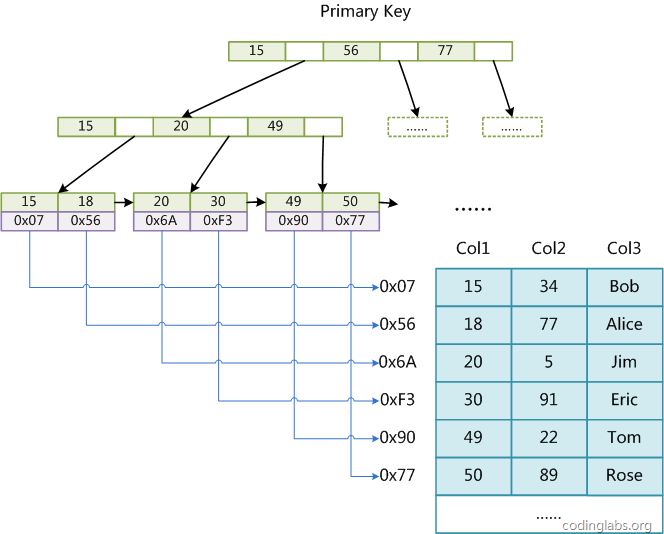
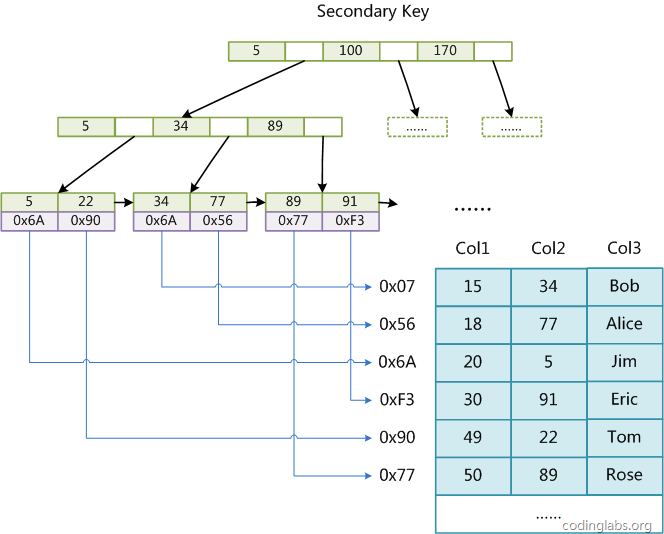
MyISAM是不支持聚集索引的,所以MyISAM中的索引的存储格式如下所示,都是在叶子节点中存储着数据所对应的指针。
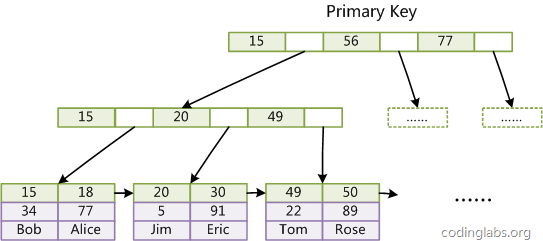
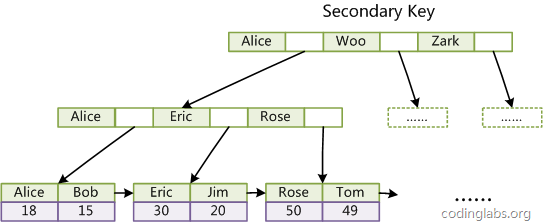
InnoDB是不支持聚集索引的,所以InnoDB中的索引的存储格式如下所示,主键的存储方式和非主键的存储方式是不同的。
关于索引的使用与优化有下面的一些准则:
- 当在建立了索引的列上使用精确匹配,使用“=”或者“in”时是会使用索引的。
- 最左匹配原则,在a和b上建立了联合索引,whereb=?时是不会使用告警的。
- 通配符%不能放在开头,也就是说,like%abc%是不会使用索引的,likeabc%是会使用索引的。
- 范围列(>,<,betweenand)可以用到索引,但是范围列后面的列无法用到索引。同时,索引最多用于一个范围列,因此如果查询条件中有两个范围列则无法全用到索引。
- 如果使用了函数或者表达式,则不会使用索引。例如,left(title,6)='Senior'将不会使用到索引,可以使用like代替。
- groupby的优化需要松散索引扫描和紧凑索引扫描,单独地进行说明。
关于索引的建立,还有下面一些需要注意的地方:
- 索引要建立在数值分布均匀的列上,如果在性别,只有男和女2个取值的列上建立索引,对于查询速度的提升不会有很大帮助。
- 另一种与索引选择有关的优化策略叫做前缀索引,就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。
ALTERTABLEemployees.employeesADDINDEX`first_name_last_name4`(first_name,last_name(4));
- 在使用InnoDB存储引擎时,如果没有特别的需要,请永远使用一个与业务无关的自增字段作为主键。使用业务无关的自增长字段作为主键的好处是,底层的数据会很紧凑,增加新的数据时磁盘的移动操作也更少。
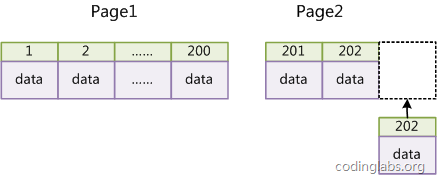
而使用业务相关的主键时,数据可能是松散分布的,且增加新的数据时,磁盘操作会更多。
当你删除数据时,MySQL并不会回收,已被删除数据占据的存储空间,以及索引位。而是空在那里,而是等待新的数据来弥补这个空缺。
如果一时半会,没有数据来填补这个空缺,那这样就太浪费资源了。所以对于写操作比较频烦的表,要定期进行optimize,一个月一次,看实际情况而定了。
如果您已经删除了表的一大部分,或者如果您已经对含有可变长度行的表(含有VARCHAR,BLOB或TEXT列的表)进行了很多更改,则应使用OPTIMIZETABLE。被删除的记录被保持在链接清单中,后续的INSERT操作会重新使用旧的记录位置。您可以使用OPTIMIZETABLE来重新利用未使用的空间,并整理数据文件的碎片。
在多数的设置中,您根本不需要运行OPTIMIZETABLE。即使您对可变长度的行进行了大量的更新,您也不需要经常运行,每周一次或每月一次即可,只对特定的表运行。
OPTIMIZETABLE只对MyISAM,BDB和InnoDB表起作用,但是OPTIMIZETABLE运行过程中,MySQL会锁定表。
使用OPTIMIZETABLE时还有一点需要助于,如果开启了独立表空间,即每张表都有ibdfile。这个时候如果删除了大量的行,索引会重组并且会释放相应的空间因此不必优化。
共享表空间所有表的数据与索引都存放于ibddata1文件中,随着数据量的增长会导致该文件越来越大。超过10G的时候查询速度就非常慢,因此在编译的时候最好开启独享表空间。
mysql>showvariableslike"innodb_file_per_table";
ON代表独立表空间管理,OFF代表共享表空间管理;
独立表空间和共享表空间是可以转换的,修改innodb_file_per_table的参数值即可,但是修改不能影响之前已经使用过的共享表空间和独立表空间;
innodb_file_per_table=1为使用独占表空间
innodb_file_per_table=0为使用共享表空间
顺序读,随机读和预读取
顺序读是指顺序的读取磁盘上的block,随机读指访问磁盘上的块是不连续的,需要磁盘的磁头的不断转动,在数据库中,顺序读指的是根据索引的叶子节点数据就能顺序的读到所需的行数据,
随机读是指需要访问非聚集索引和聚集索引两个共同才能读到所需的数据.
为了提高读取的性能,innodb中引入了预读取技术,通过一次的io请求将多个页读到缓冲池中,有两种方式,随机预读取和线性预读取,
但预读取在实际测试中效果不是很好,从innodbplugin1.0.4后,随机访问只保留了线性的预读取.