Introduction
对HA-CNN的改进版。
Methods
(1) 训练策略:
① Weighted triplet loss with Soft margin:
最初的triplet loss为:
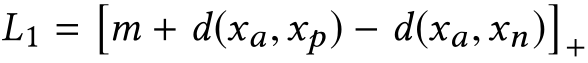
Batch-hard triplet loss选择了难样本对进行损失计算:
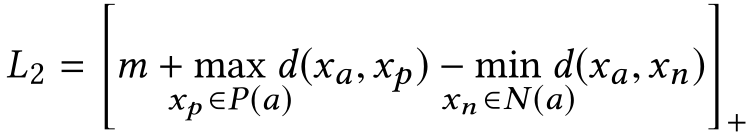
batch-hard的缺点是:对异常样本敏感,硬选择策略可能会丢失重要信息。

对这个公式的权重,我的理解是:对正样本对,越不相似的权重越大;对负样本对,越相似的权重越大。也就是难样本的权重更大。
作者提出的新三元组损失,其中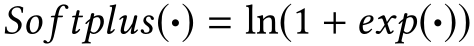 :
:
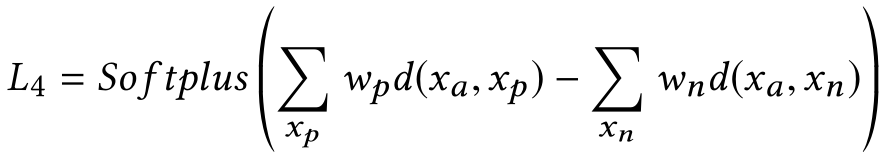
下图可以发现,当正样本对距离已经小于负样本对距离时,依然存在损失值,让两者的间距进一步拉大,达到了之前设置margin的作用。
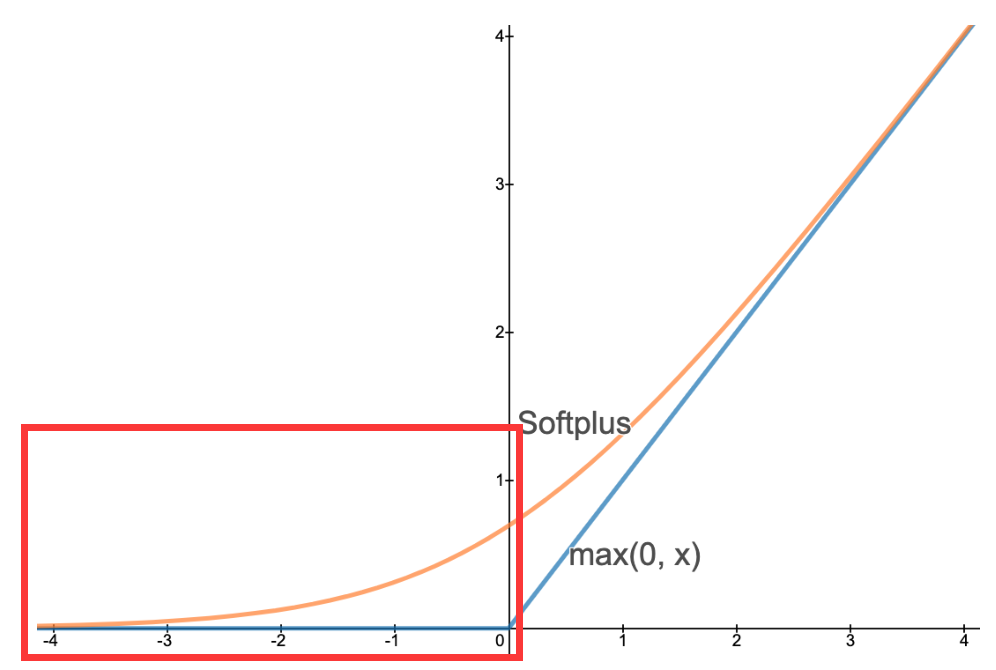
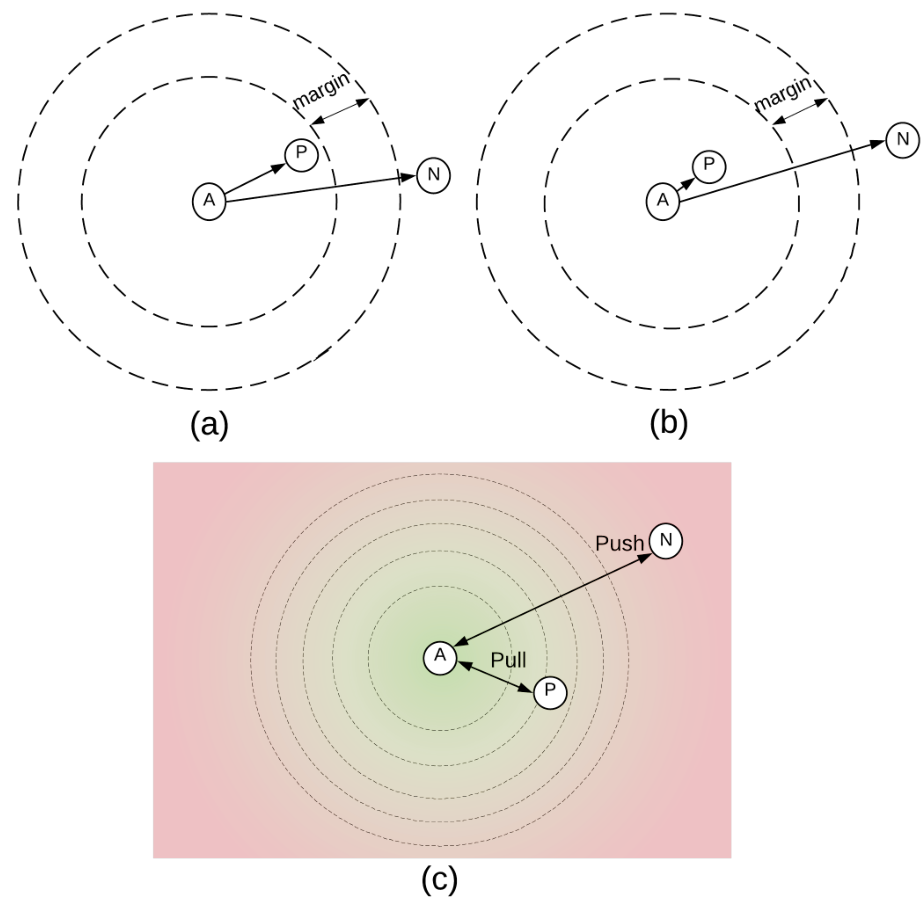
同时,margin的固定使得下面的(a)(b)两种情况的损失均为0,无法评估margin范围内情况。而作者提出的方法(c)克服了这个问题,即使已经满足了正样本对距离<负样本对距离,其距离差异依然能进一步拉大。
② L2 normalization:
③ SWAG:
SWA (Stochastic weight averaging):在优化的末期取k个优化轨迹上的checkpoints,平均他们的权重,得到最终的网络权重,这样就会使得最终的权重位于flat曲面更中心的位置【参考,代码】
SWAG (SWA-Gaussian):使用SWA解作为一阶矩拟合高斯函数,并且从SGD迭代获得低秩加对角协方差,从而在神经网络权重上形成近似后验分布(知识盲区);
学习率上采用余弦退火学习率(cosine annealing learning rate):一种周期性学习率【参考】
④ 其它训练技巧:
随机擦除(Random Erasing Augmentation, REA)、Warmup.
(2) 模型优化:
① Shuffle blocks:
将输入的特征按通道划分为两部分输入两个分支中,级联后进行channel shuffle
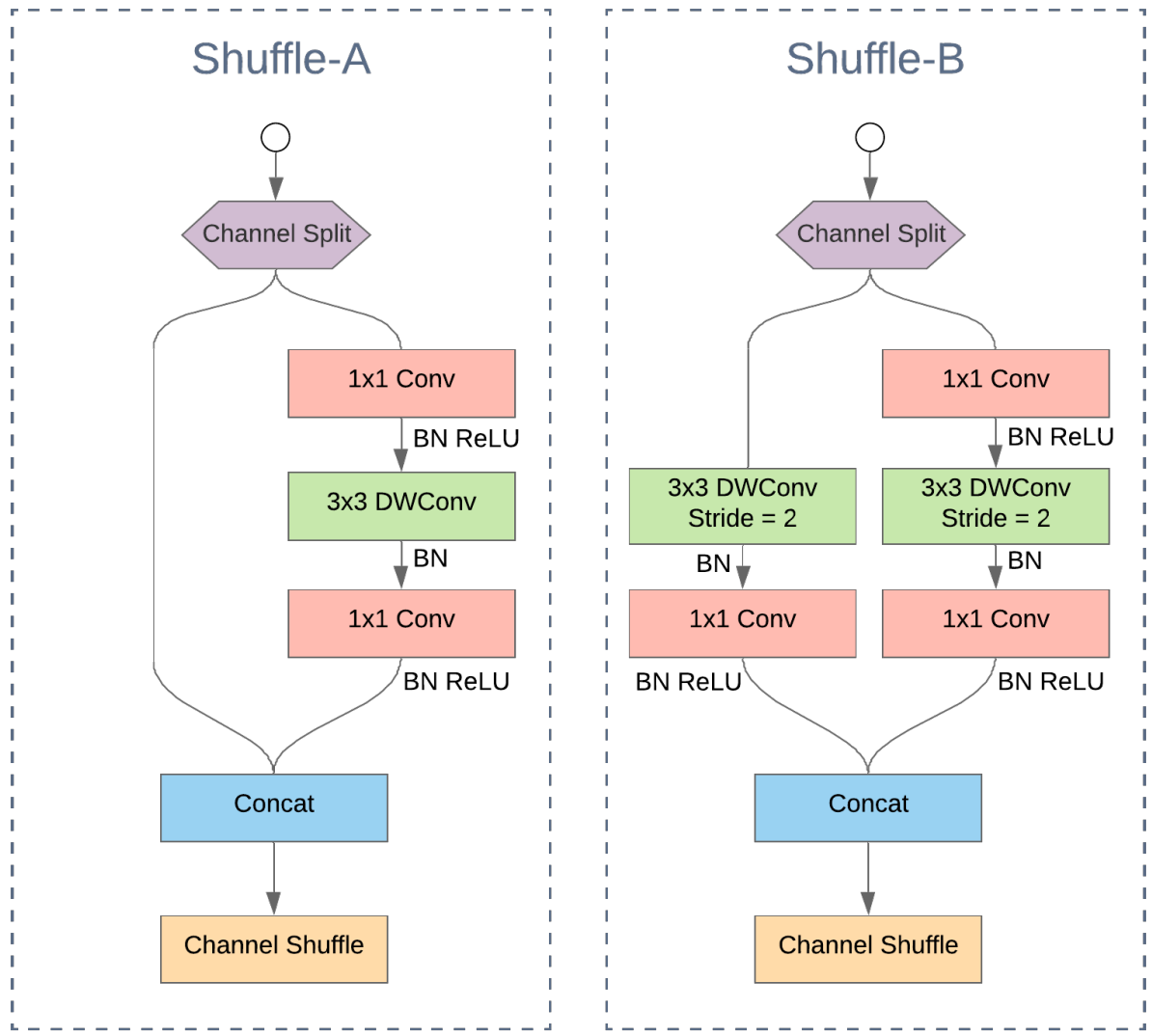
关于channel shuffle的直观理解:

② Generalized Mean (GeM):
在HACNN中,全连接层之前采用了GAP,然而如果用GMP替换,有时带来提升有时带来下降。作者提出了GeM池化,对任意特征图的计算为:
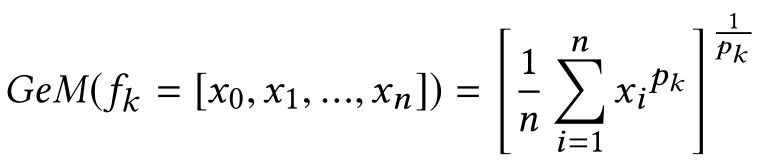
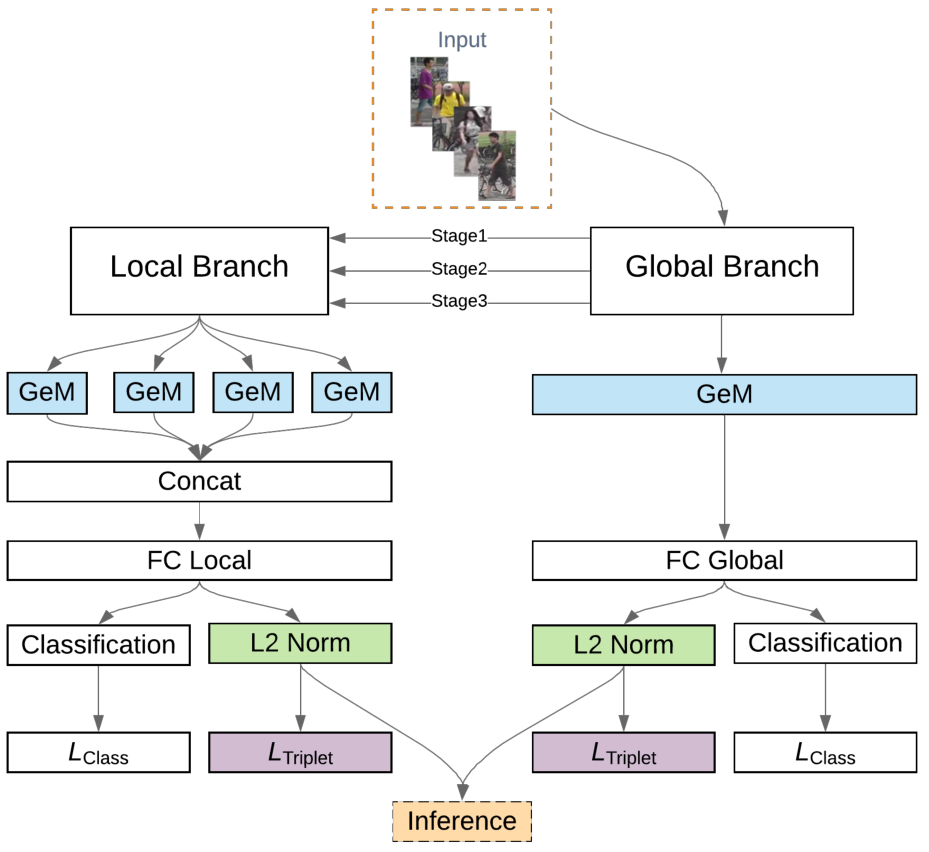
③ 网络架构:
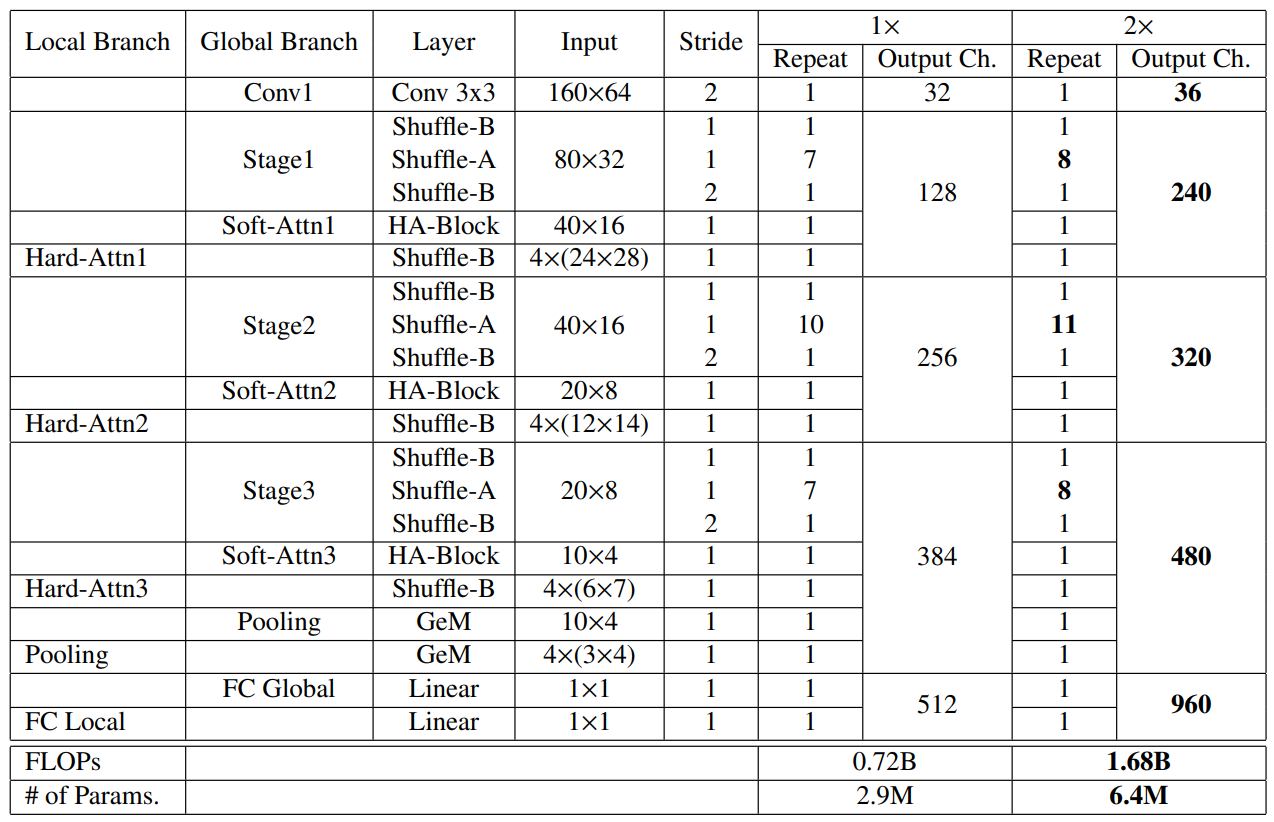
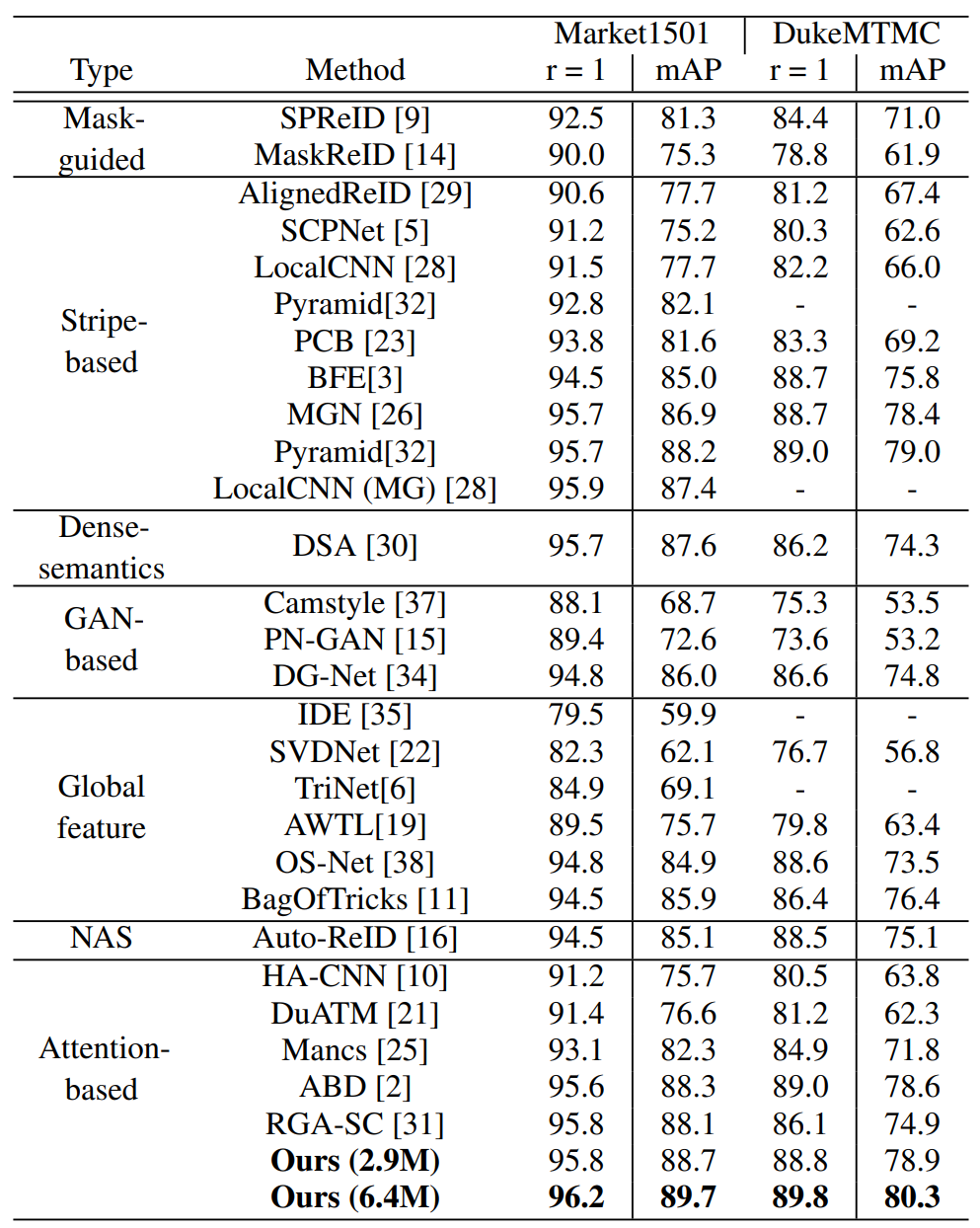
Experimental Results
(1) 实验细节:
图像尺寸:160x64;
优化器:SGD+Warmup(350 epochs) / SWAG(15 cycles of 35 epochs = 525 epochs);
batch: 8 ID x 4 images = 32。
(2) 实验结果: