摘要:
否则,将追究法律责任。树中的层次结构不是预先设置的,但可以相对于数据中心、机架和运行节点进行设置。我们必须认识到Hadoop无法自动发现您的网络拓扑。博主推荐阅读:http://hadoop.apache.org/docs/r2.10.0/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication2、使用命令行验证Rack Sense 1˃将群集的默认副本数设置为1,然后重新启动HDFS群集以使配置有效。我的实验是基于Hadoop的完全分布式部署。请参考我之前关于构建完全分布式HDFS集群的说明。
HDFS的机架感知概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.网络拓扑结构
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率,即带宽稀缺。这里的想法是将两个节点之间的带宽作为距离的衡量标准。不用衡量节点之间的带宽,实际上很难实现(它需要一个稳定的集群,并且在集群中两两节点对数量是节点数量的平方),hadoop为此采用了一个简单的方法:把网络看作一棵树,两个节点之间的距离是他们到最近共同祖先的距离总和。该树中的层次是没有预先设定的, 但是相对与数据中心,机架和正在运行的节点,通常可以设定等级。具体想法是针对以下每个常见,可用带宽依次递减: 1>.同一节点上的进程; 2>.同一机架上的不同节点; 3>.同一数据中心中不同机架上的节点; 4>.不同数据中心的节点; 举个例子,假设有数据中心d1,机架r1中的节点n1。该节点可以表示为“/d1/r1/n1”。利用这种标记,这里给出四种距离描述: 1>.distance(/d1/r1/n1,/d1/r1/n1)=0(同一节点上的进程); 2>.distance(/d1/r1/n1,/d1/r1/n2)=2(同一机架上的不同节点); 3>.distance(/d1/r1/n1,/d1/r2/n3)=4(同一数据中心中不同机架上的节点); 4>.distance(/d1/r1/n1,/d2/r3/n4)=6(不同数据中心中的节点);
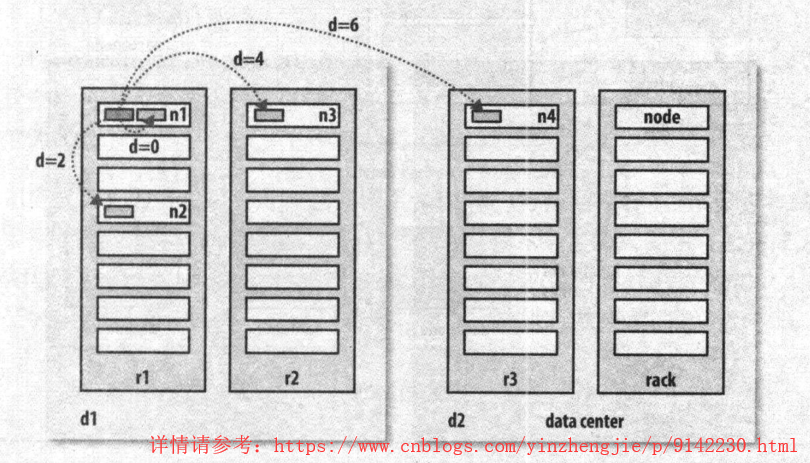
上图摘自《Hadoop权威指南第四版》。我们必须要意识到Hadoop无法自动发现你的网络拓扑结构。它需要一些帮助,不过在默认情况下,假设网络是扁平化的只有一层,换句话说,所有节点在同一数据中心的同一机架上。规模小的集群可能如此,不需要进一步配置。
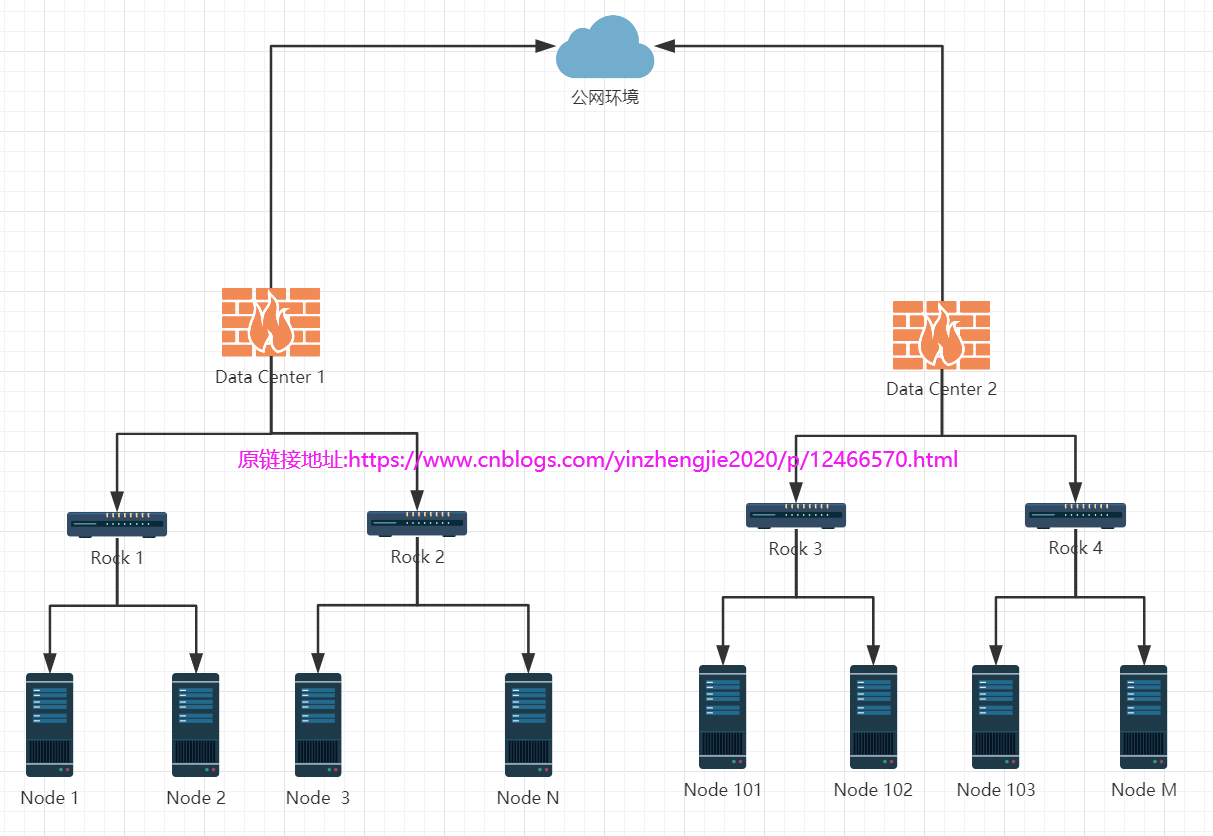
如果大家觉得上面比较难理解也无所谓,我们可以看下图,方便大家记忆
1>."Node 1"到"Node 2"按照上面的说法"同一个机架不同的节点"距离应该为2,很显然,咱们数"线"结果就为2;
2>."Node 1"到"Node 3"按照上面的说法"同一个数据中心的不同机架"距离应该为4,很显然,咱们数"线"结果就为4;
3>."Node 1"到"Node 101"按照上面的说法"不同数据中心的节点"距离应该为6,很显然,咱们数"线"结果为6。
温馨提示: 我们要假设上传的文件要保存3个副本,如果在一个DataNode节点上传数据,那么该节点一定会先保存第一个副本,第二个副本会选择在同一个机架上选择另一个节点保存,而第三个副本会选择不同机架的节点保存。 在生产环境中,我并不建议大家将大数据集群建设到在多个数据中心,尽管你各机房走的专线,其效率未必有用一个数据中心的传输效率高哟,但是你为了安全性考虑的话那就另当别论了,比如你担心这个数据中心断电之类的情况,其实数据中心都有自己的双路PDU(当然也有自己的UPS),尽管整个城市断电这个数据中心也能坚持足够的时间通知你处理业务。 博主推荐阅读: http://hadoop.apache.org/docs/r2.10.0/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
二.使用命令行验证机架感知
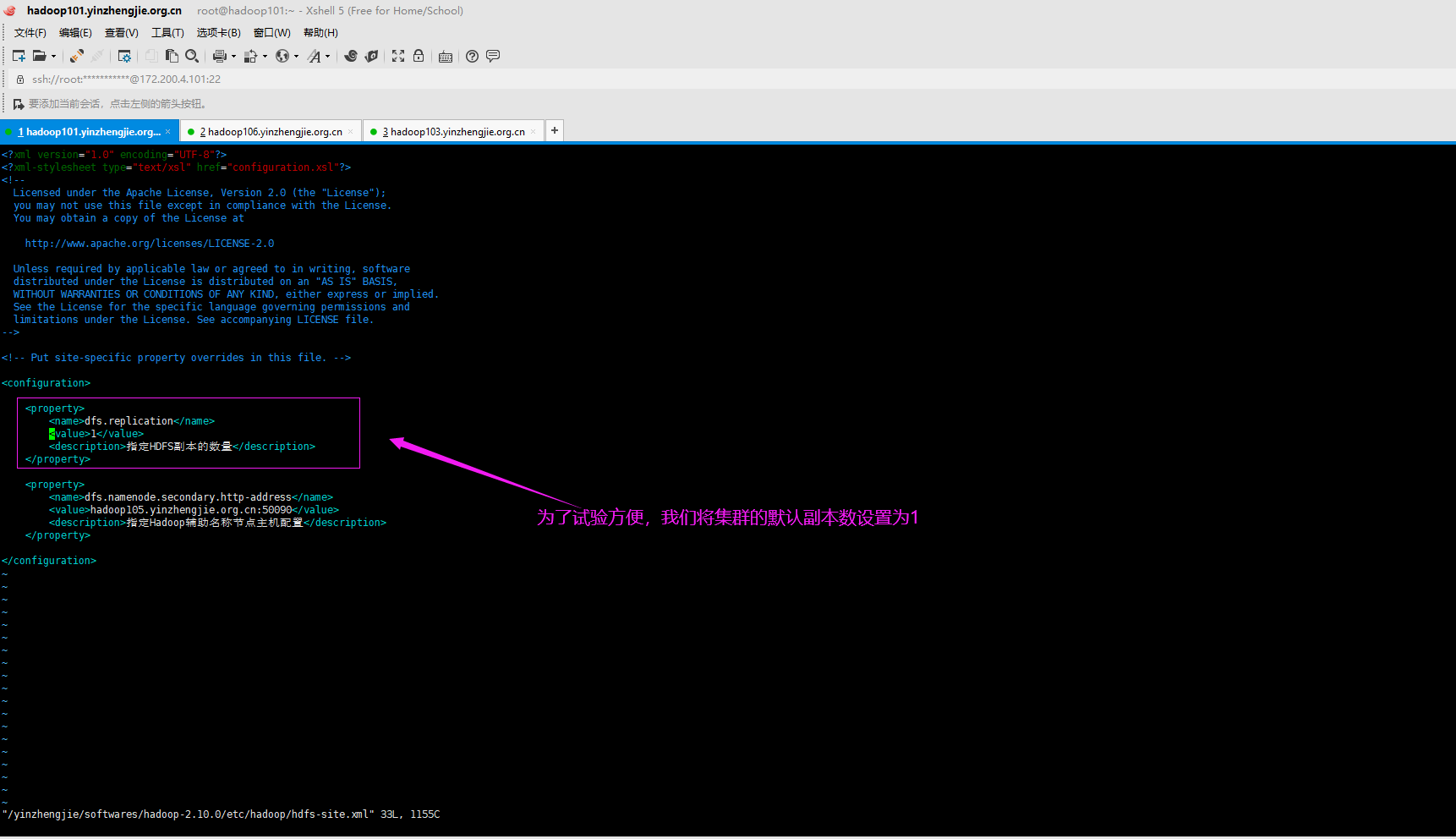
1>.将集群的默认副本数设置为1并重启HDFS集群使得配置生效
我试验的是基于Hadoop的完全分布式部署的,关于搭建HDFS完全分布式集群可参考我之前的笔记。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12424192.html


[root@hadoop101.yinzhengjie.org.cn ~]# echo ${HADOOP_HOME} /yinzhengjie/softwares/hadoop-2.10.0 [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# cat ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>1</value> <description>指定HDFS副本的数量</description> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop105.yinzhengjie.org.cn:50090</value> <description>指定Hadoop辅助名称节点主机配置</description> </property> </configuration> [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# echo ${HADOOP_HOME} /yinzhengjie/softwares/hadoop-2.10.0 [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# rsync-hadoop.sh ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml ******* [hadoop102.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/hdfs-site.xml] ******* 命令执行成功 ******* [hadoop103.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/hdfs-site.xml] ******* 命令执行成功 ******* [hadoop104.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/hdfs-site.xml] ******* 命令执行成功 ******* [hadoop105.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/hdfs-site.xml] ******* 命令执行成功 ******* [hadoop106.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/hdfs-site.xml] ******* 命令执行成功 [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5394 NameNode 8018 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 7461 Jps 5304 SecondaryNameNode hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 4045 DataNode 4110 NodeManager 5342 Jps hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 4043 DataNode 4108 NodeManager 5196 Jps hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5235 Jps 4046 DataNode 4111 NodeManager hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5344 ResourceManager 6268 Jps [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# jps 5394 NameNode 7900 Jps [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# stop-dfs.sh Stopping namenodes on [hadoop101.yinzhengjie.org.cn] hadoop101.yinzhengjie.org.cn: stopping namenode hadoop103.yinzhengjie.org.cn: stopping datanode hadoop102.yinzhengjie.org.cn: stopping datanode hadoop104.yinzhengjie.org.cn: stopping datanode Stopping secondary namenodes [hadoop105.yinzhengjie.org.cn] hadoop105.yinzhengjie.org.cn: stopping secondarynamenode [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# jps 8326 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# jps 8338 Jps [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# start-dfs.sh Starting namenodes on [hadoop101.yinzhengjie.org.cn] hadoop101.yinzhengjie.org.cn: starting namenode, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/hadoop-root-namenode-hadoop101.yinzhengjie.org.cn.out hadoop102.yinzhengjie.org.cn: starting datanode, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/hadoop-root-datanode-hadoop102.yinzhengjie.org.cn.out hadoop104.yinzhengjie.org.cn: starting datanode, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/hadoop-root-datanode-hadoop104.yinzhengjie.org.cn.out hadoop103.yinzhengjie.org.cn: starting datanode, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/hadoop-root-datanode-hadoop103.yinzhengjie.org.cn.out Starting secondary namenodes [hadoop105.yinzhengjie.org.cn] hadoop105.yinzhengjie.org.cn: starting secondarynamenode, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/hadoop-root-secondarynamenode-hadoop105.yinzhengjie.org.cn.out [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# jps 8708 Jps 8459 NameNode [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 7536 SecondaryNameNode 7624 Jps hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8839 Jps 8459 NameNode hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5417 DataNode 5545 Jps 4110 NodeManager hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5436 Jps 5309 DataNode 4111 NodeManager hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5398 Jps 5271 DataNode 4108 NodeManager hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5344 ResourceManager 6328 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
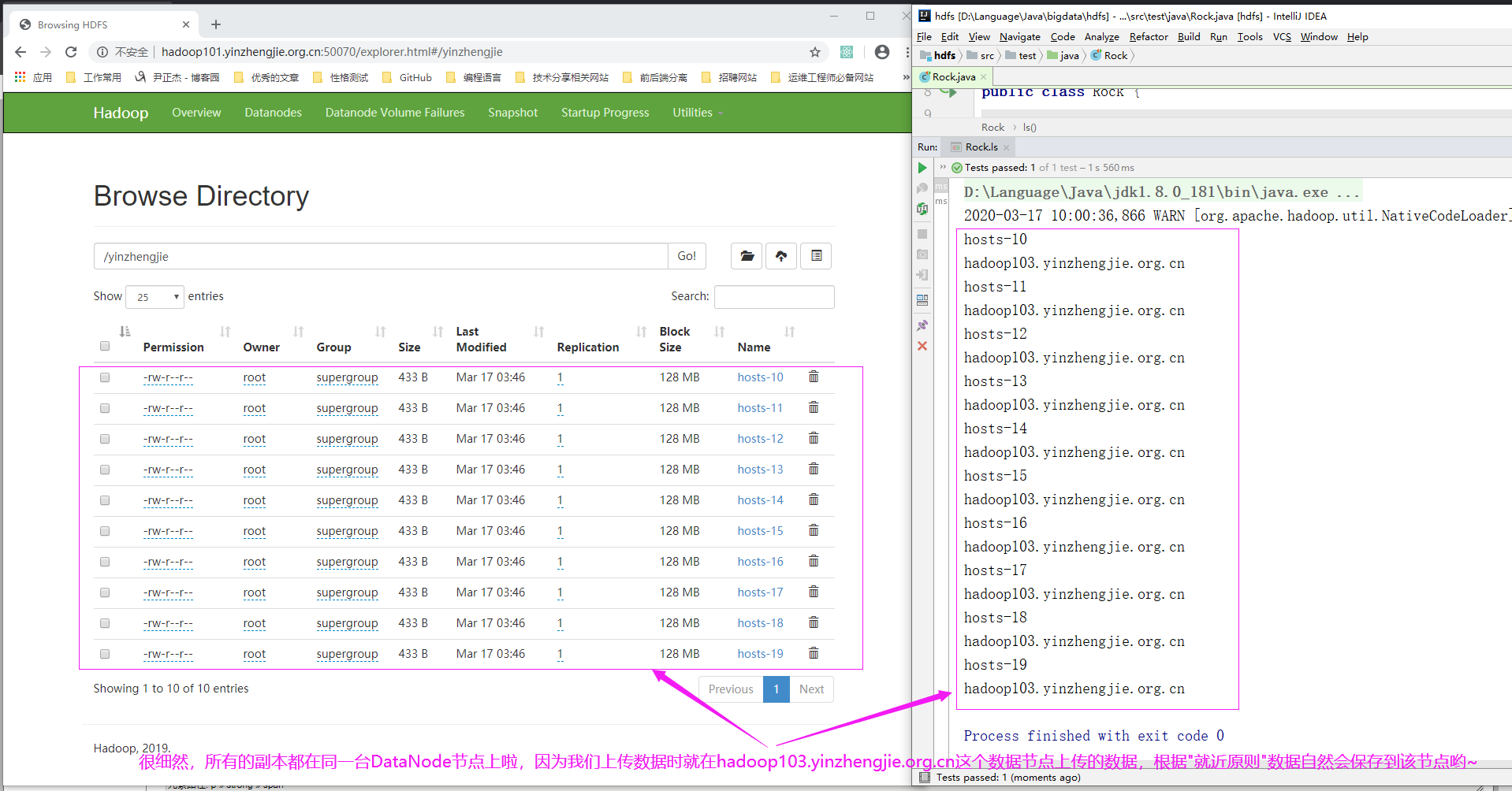
2>.我们选择一台DataNode节点上传数据,发现所有的数据都就近选择啦
[root@hadoop103.yinzhengjie.org.cn ~]# jps 5969 Jps 5417 DataNode 4110 NodeManager [root@hadoop103.yinzhengjie.org.cn ~]# [root@hadoop103.yinzhengjie.org.cn ~]# vim upload.sh [root@hadoop103.yinzhengjie.org.cn ~]# [root@hadoop103.yinzhengjie.org.cn ~]# cat upload.sh #!/bin/bash # #******************************************************************** #Author: yinzhengjie #QQ: 1053419035 #Date: 2019-11-28 #FileName: upload.sh #URL: http://www.cnblogs.com/yinzhengjie #Description: The test script #Copyright notice: original works, no reprint! Otherwise, legal liability will be investigated. #******************************************************************** #先创建一个测试目录 hdfs dfs -mkdir /yinzhengjie #接下来我们往创建的测试目录写入数据 for ((index=10;index<20;index++)) do hdfs dfs -put /etc/hosts /yinzhengjie/hosts-${index} done [root@hadoop103.yinzhengjie.org.cn ~]# [root@hadoop103.yinzhengjie.org.cn ~]# bash upload.sh [root@hadoop103.yinzhengjie.org.cn ~]#
3>.验证数据存储的位置信息
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.junit.Test; import java.io.IOException; import java.net.URI; public class Rock { @Test public void ls() throws IOException, InterruptedException { //获取文件系统 FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),new Configuration(),"root"); //获取文件详情 RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/yinzhengjie"), true); while (listFiles.hasNext()){ LocatedFileStatus status = listFiles.next(); //获取文件名称 System.out.println(status.getPath().getName()); BlockLocation[] blockLocations = status.getBlockLocations(); for (BlockLocation block : blockLocations){ //获取块存储的主机节点 String[] hosts = block.getHosts(); for (String host:hosts){ System.out.println(host); } } } //释放资源 fs.close(); } }
三.使用Java源码验证机架感知
博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/9142230.html