一、js的工作原理:引擎、运行时与调用栈概述
JavaScript引擎的一个流行示例是Google的V8引擎。比如,V8引擎用于Chrome和Node.js。
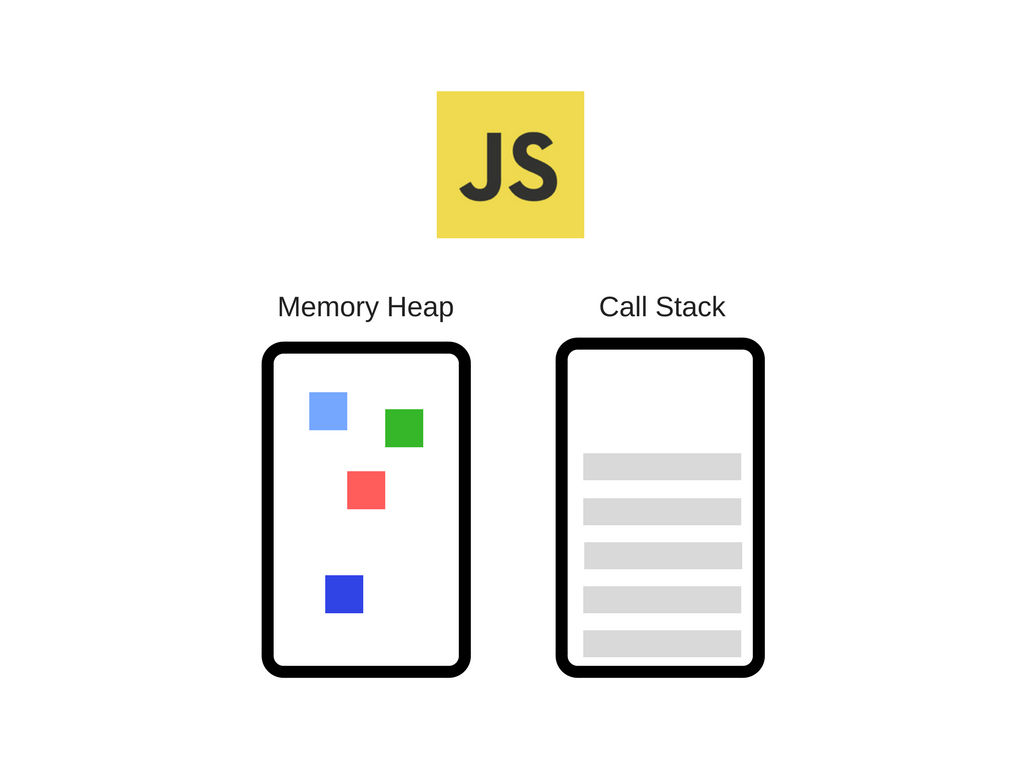
该引擎包括两个主要组件:
*内存堆-这是内存分配的地方
*调用堆栈-这是代码执行时堆栈帧的位置
浏览器中有几乎所有JavaScript开发人员都在使用的API(例如“ setTimeout”)。但是,引擎不提供这些API。
那么,它们来自哪里?
事实证明,现实有点复杂。
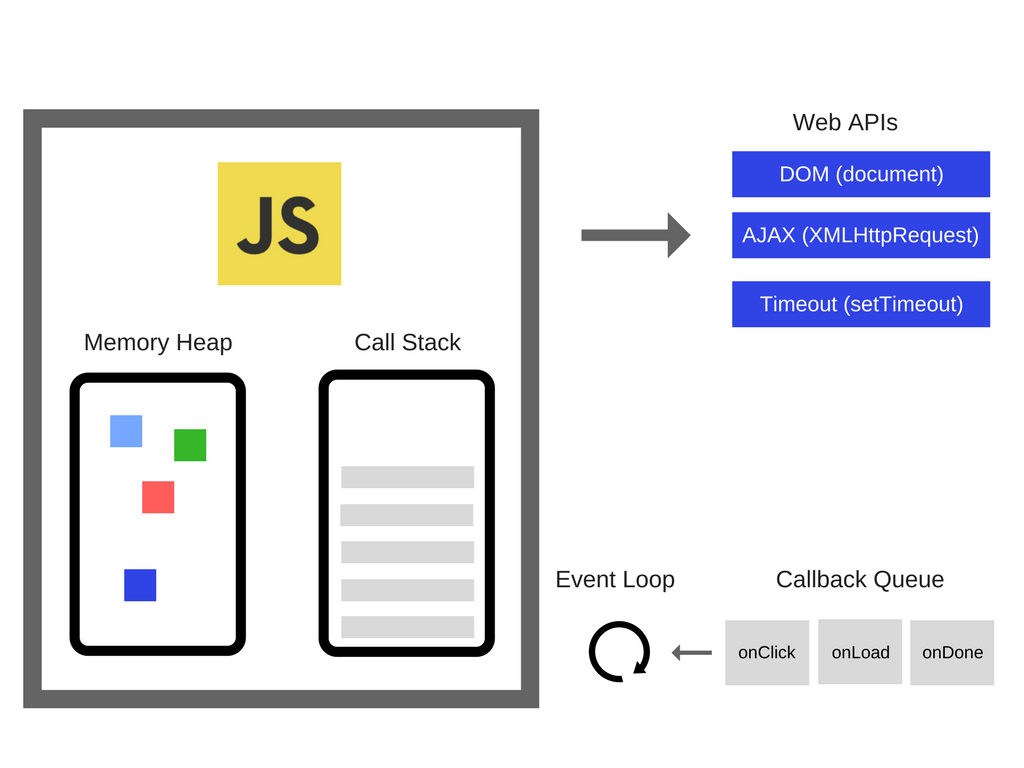
因此,我们有引擎,但实际上还有更多。我们拥有由浏览器提供的称为Web API的东西,例如DOM,AJAX,setTimeout等。
然后,我们有了非常流行的事件循环和回调队列。
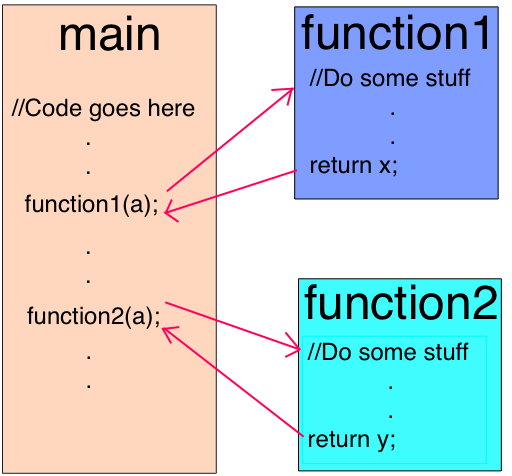
调用堆栈JavaScript是一种单线程编程语言,这意味着它具有单个调用堆栈。因此,它一次只能做一件事。
调用堆栈是一种数据结构,它基本上记录了我们在程序中的位置。如果进入函数,则将其放在堆栈的顶部。如果我们从函数返回,则会弹出堆栈顶部。这就是堆栈所能做的。
让我们来看一个例子。看下面的代码:
function multiply(x, y) { return x * y; } function printSquare(x) { var s = multiply(x, x); console.log(s); } printSquare(5);
当引擎开始执行此代码时,调用堆栈将为空。之后,将执行以下步骤:
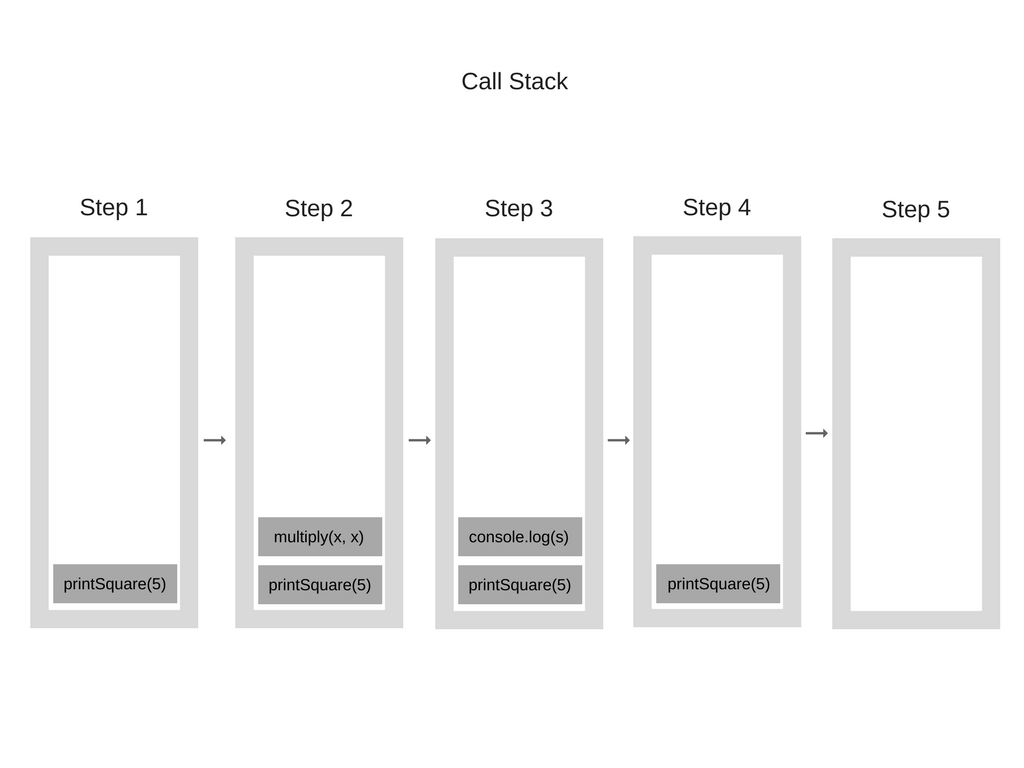
调用堆栈中的每个条目都称为堆栈帧。
这正是抛出异常时构造堆栈跟踪的方式-基本上,这是异常发生时调用堆栈的状态。看下面的代码:
function foo() { throw new Error('SessionStack will help you resolve crashes :)'); } function bar() { foo(); } function start() { bar(); } start();
如果在Chrome中执行此操作(假设此代码位于名为foo.js的文件中),则会生成以下堆栈跟踪:

“ 炸毁堆栈 ” —当您达到最大呼叫堆栈大小时,就会发生这种情况。这很容易发生,特别是如果您使用递归而不对代码进行大量测试的话。看一下以下示例代码:
function foo() { foo(); } foo();
当引擎开始执行此代码时,它首先调用函数“ foo”。但是,此函数是递归的,并且在没有任何终止条件的情况下开始调用自身。因此,在执行的每个步骤中,都将相同的函数一遍又一遍地添加到调用堆栈中。看起来像这样:
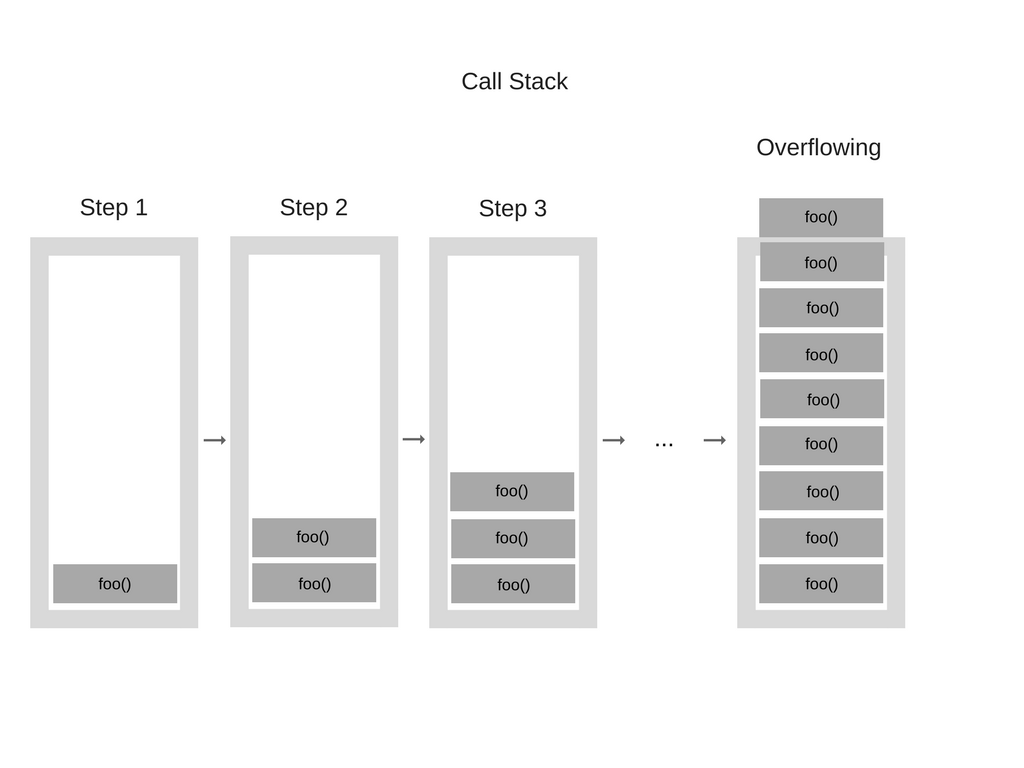
但是,在某些时候,“调用堆栈”中的函数调用数量超过了“调用堆栈”的实际大小,浏览器决定通过抛出错误来采取措施,该错误看起来像这样:

在单个线程上运行代码非常容易,因为您不必处理多线程环境中出现的复杂情况,例如死锁。
但是在单线程上运行也有很大的限制。由于JavaScript具有单个调用堆栈,所以当事情变慢时会发生什么?
并发与事件循环当在调用堆栈中进行函数调用要花费大量时间才能处理时,会发生什么情况?例如,假设您想在浏览器中使用JavaScript进行一些复杂的图像转换。
您可能会问-为什么这甚至是问题?问题在于,尽管调用堆栈具有要执行的功能,但浏览器实际上无法执行其他任何操作-它被阻塞了。这意味着浏览器无法渲染,无法运行任何其他代码,只是卡住了。如果您想要在应用程序中使用流畅的用户界面,则会产生问题。
这不是唯一的问题。一旦您的浏览器开始处理“调用堆栈”中的许多任务,它可能会在很长一段时间内停止响应。而且大多数浏览器都会通过引发错误来采取行动,询问您是否要终止网页。
现在,那不是最好的用户体验,不是吗?
那么,如何在不阻塞UI并使浏览器无响应的情况下执行繁重的代码呢?好吧,解决方案是异步回调。
二、JavaScript的工作原理:V8引擎内部+ 5条有关编写优化代码的技巧
几周前,我们开始了一系列旨在深入研究JavaScript及其实际工作的系列:我们认为,通过了解JavaScript的构建基块以及它们如何一起发挥作用,您将能够编写更好的代码和应用程序。该系列的第一篇文章重点介绍了引擎,运行时和调用堆栈的概述。第二篇文章将深入探讨Google V8 JavaScript引擎的内部部分。我们还将提供一些有关在构建产品时如何编写更好的JavaScript代码的快速提示。
总览
JavaScript引擎是一个程序或执行JavaScript代码的解释器。JavaScript引擎可以实现为标准解释器,也可以作为即时编译器将JavaScript编译为某种形式的字节码。
这是实现JavaScript引擎的热门项目的列表:
- V8-由Google开发的开放源代码,用C++编写
- Rhin o-由Mozilla基金会管理,开源,完全使用Java开发
- SpiderMonkey-第一个JavaScript引擎,其功能可以追溯到Netscape Navigator时代,而今天则为Firefox提供动力
- JavaScriptCore —开源,由Nitro销售,由Apple为Safari开发
- KJS — KDE的引擎,最初由Harri Porten为KDE项目的Konqueror Web浏览器开发
- Chakra(JScript9) — Internet Explorer
- Chakra(JavaScript) -Microsoft Edge
- Nashorn,作为OpenJDK的一部分开放源代码,由Oracle Java Languages and Tool Group编写
- JerryScript —是用于物联网的轻量级引擎。
为什么创建V8引擎?
由Google构建的V8引擎是开源的,并使用C++编写。该引擎在Google Chrome内部使用。但是,与其他引擎不同,V8还用于流行的Node.js运行。

V8最初旨在提高Web浏览器中JavaScript执行的性能。为了获得速度,V8将JavaScript代码转换为更有效的机器代码,而不是使用解释器。它通过像许多现代JavaScript引擎(例如SpiderMonkey或Rhino(Mozilla))一样实现JIT(即时)编译器,在执行时将JavaScript代码编译为机器代码。这里的主要区别是V8不会产生字节码或任何中间代码。
V8曾经有两个编译器
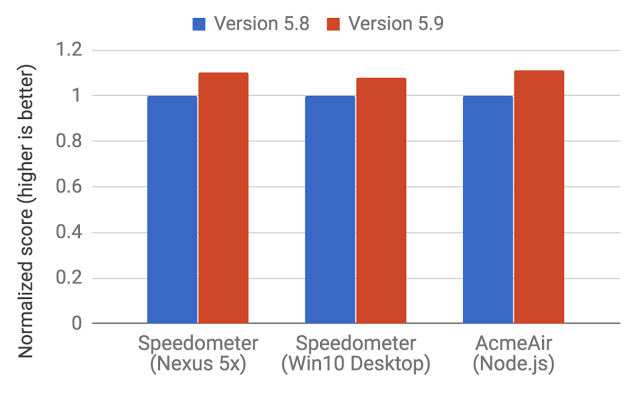
在V8 5.9版本(今年早些时候发布)发布之前,该引擎使用了两个编译器:
- full-codegen(完整代码生成器)—一个简单且非常快速的编译器,它生成了简单且相对较慢的机器代码。
- 曲轴-一种更复杂的(按时间排列)优化的编译器,可以生成高度优化的代码。
V8引擎还在内部使用多个线程:
- 主线程完成了您所期望的:获取代码,对其进行编译,然后执行
- 还有一个单独的编译线程,因此主线程可以在执行代码优化时继续执行
- Profiler线程将告诉运行时我们在哪些方法上花费了大量时间,以便曲轴可以优化它们
- 一些线程来处理垃圾收集器
首次执行JavaScript代码时,V8会利用完整的代码生成器,该代码生成器将已解析的JavaScript直接转换为机器代码,而无需进行任何转换。这使它可以非常快速地开始执行机器代码。请注意,V8不会以这种方式使用中间字节码表示,从而无需解释器。
当您的代码运行了一段时间后,探查器线程已经收集了足够的数据来告诉您应该优化哪种方法。
接下来,曲轴优化从另一个线程开始。它将JavaScript抽象语法树转换为称为Hydrogen的高级静态单一分配(SSA)表示形式,并尝试优化该Hydrogen图。大多数优化都在此级别上完成。
内联
第一个优化是预先内联尽可能多的代码。内联是将调用站点(调用函数的代码行)替换为被调用函数的主体的过程。这个简单的步骤可使后续优化变得更有意义。
隐藏类
JavaScript是基于原型的语言:没有使用克隆过程创建的类和对象。JavaScript还是一种动态编程语言,这意味着可以在实例化对象后轻松地添加或删除属性。
大多数JavaScript解释器使用类似字典的结构(基于哈希函数)将对象属性值的位置存储在内存中。与在非动态编程语言(例如Java或C#)中使用JavaScript相比,使用这种结构检索属性的值在计算上更加昂贵。在Java中,所有对象属性均由编译前的固定对象布局确定,并且无法在运行时动态添加或删除(嗯,C#具有动态类型是另一个主题)。结果,属性的值(或指向这些属性的指针)可以作为连续缓冲区存储在内存中,并且在每个缓冲区之间具有固定偏移量。可以根据属性类型轻松确定偏移量的长度,但是在JavaScript中这是不可能的,因为JavaScript在运行时可以更改属性类型。
由于使用字典查找对象属性在内存中的位置效率很低,因此V8改用了另一种方法:隐藏类。隐藏类的工作方式类似于Java之类的语言中使用的固定对象布局(类),但它们是在运行时创建的。现在,让我们看看它们的实际外观:
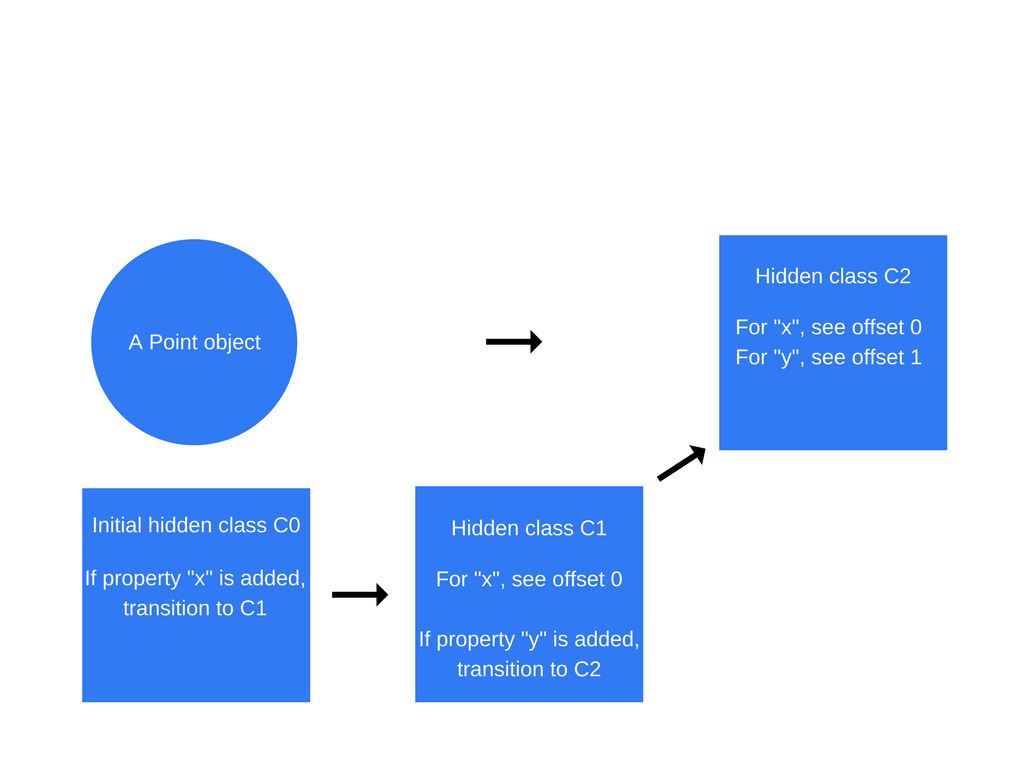
function Point(x, y) { this.x = x; this.y = y; } var p1 = new Point(1, 2);
一旦发生“new Point(1,2)”调用,V8将创建一个名为“ C0”的隐藏类。
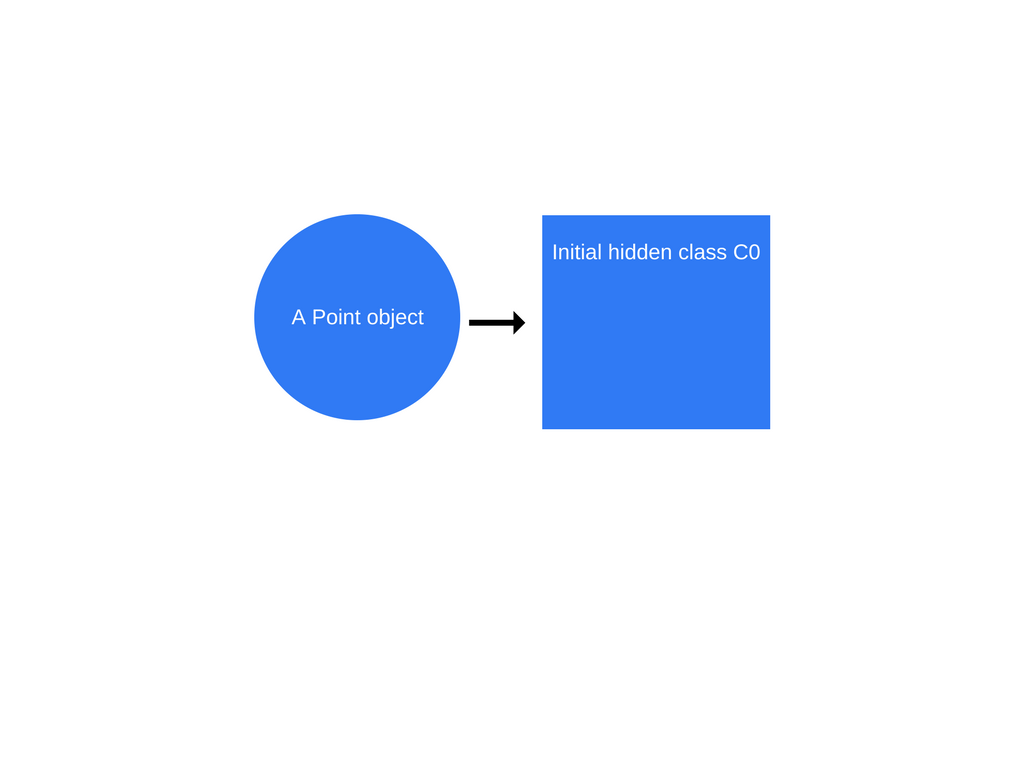
尚未为Point定义任何属性,因此“ C0”为空。
一旦执行了第一个语句“ this.x = x”(在“ Point”函数内部),V8将创建一个基于“ C0”的第二个隐藏类“ C1”。“ C1”描述了在内存中(相对于对象指针)可以找到属性x的位置。在这种情况下,“ x”存储在偏移量0处,这意味着在将内存中的点对象作为连续缓冲区查看时,第一个偏移量将对应于属性“ x”。V8还将使用“类转换”更新“ C0”,该类转换指出如果将属性“ x”添加到点对象,则隐藏的类应从“ C0”切换为“ C1”。现在,下面的点对象的隐藏类为“ C1”。
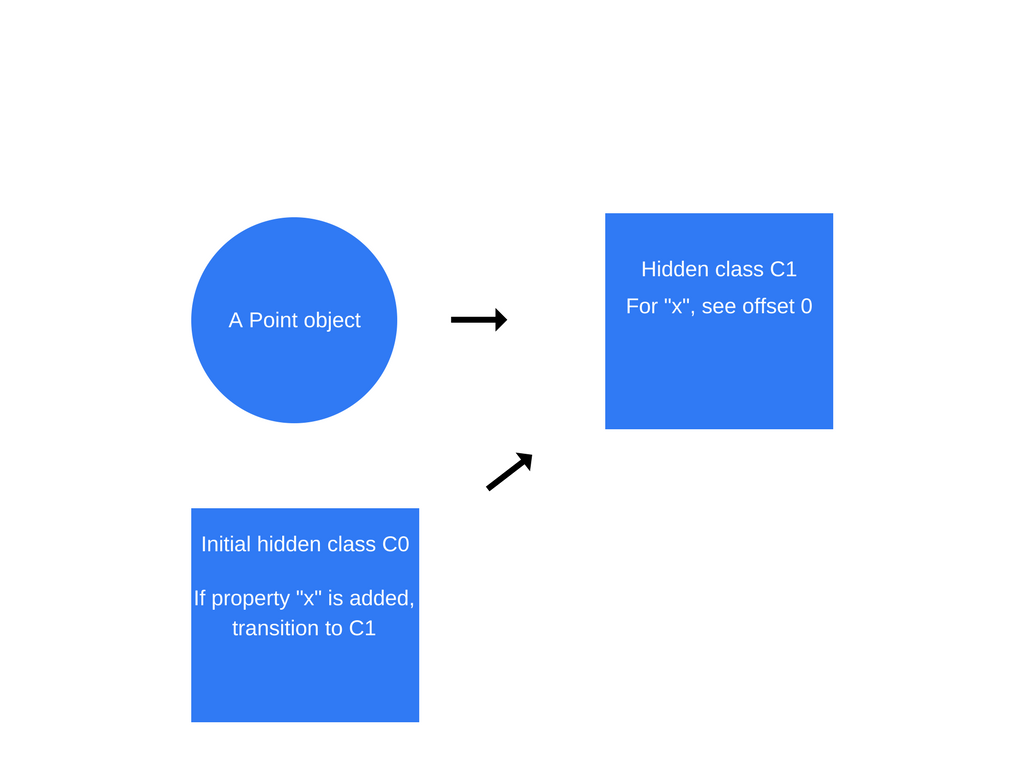
每次将新属性添加到对象时,都会使用到新隐藏类的过渡路径来更新旧的隐藏类。隐藏类转换非常重要,因为它们允许隐藏类在以相同方式创建的对象之间共享。如果两个对象共享一个隐藏类,并且向它们两个都添加了相同的属性,则过渡将确保两个对象都接收到相同的新隐藏类以及随之而来的所有优化代码。
当执行语句“ this.y = y”(同样在Point函数内部,在“ this.x = x”语句之后)时,将重复此过程。
创建了一个名为“ C2”的新隐藏类,将一个类转换添加到“ C1”,表明如果将属性“ y”添加到Point对象(已经包含属性“ x”),则该隐藏类应更改为“ C2”,并且点对象的隐藏类更新为“ C2”。
隐藏的类转换取决于将属性添加到对象的顺序。看一下下面的代码片段:
function Point(x, y) { this.x = x; this.y = y; } var p1 = new Point(1, 2); p1.a = 5; p1.b = 6; var p2 = new Point(3, 4); p2.b = 7; p2.a = 8;
现在,您假定对于p1和p2,将使用相同的隐藏类和转换。好吧,不是真的。对于“ p1”,将首先添加属性“ a”,然后添加属性“ b”。但是,对于“ p2”,首先分配“ b”,然后分配“ a”。因此,“ p1”和“ p2”由于不同的过渡路径而最终具有不同的隐藏类。在这种情况下,最好以相同的顺序初始化动态属性,以便可以重用隐藏的类。
内联缓存
V8利用了另一种用于优化动态类型语言的技术,称为内联缓存。内联缓存依赖于这样的观察,即对相同类型的对象倾向于重复调用相同的方法。可以在此处找到有关内联缓存的深入说明。
我们将介绍内联缓存的一般概念(以防您没有时间进行上面的深入说明)。
那么它是怎样工作的?V8维护最近的方法调用中作为参数传递的对象类型的缓存,并使用此信息对将来将作为参数传递的对象的类型做出假设。如果V8能够很好地假设将传递给方法的对象的类型,则它可以绕过找出如何访问对象属性的过程,而可以使用先前查找到对象的存储信息。隐藏的类。
那么隐藏类和内联缓存的概念如何相关?每当在特定对象上调用方法时,V8引擎都必须对该对象的隐藏类执行查找,以确定用于访问特定属性的偏移量。在对相同的隐藏类成功两次调用相同的方法之后,V8会省略隐藏类查找,而只是将属性的偏移量添加到对象指针本身。对于该方法的所有将来调用,V8引擎假定隐藏类未更改,并使用从以前的查询存储的偏移量直接跳到特定属性的内存地址。这大大提高了执行速度。
内联缓存也是同样重要的原因,因为相同类型的对象共享隐藏的类。如果创建两个具有相同类型且具有不同隐藏类的对象(如我们在前面的示例中所做的那样),则V8将无法使用内联缓存,因为即使这两个对象属于同一类型,它们的对应隐藏类为它们的属性分配不同的偏移量。

这两个对象基本相同,但是“ a”和“ b”属性是按不同顺序创建的。
编译机器码
优化Hydrogen图后,曲轴将其降低到一个称为Lithium的较低级表示形式。大多数Lithium实现都是特定于体系结构的。寄存器分配发生在此级别。
最后,锂被编译为机器代码。然后发生了另一件事,称为OSR:堆栈替换。在我们开始编译和优化之前,我们可能已经在运行它。V8不会忘记它只是缓慢执行以重新启动优化版本。相反,它将转换我们拥有的所有上下文(堆栈,寄存器),以便我们可以在执行过程中切换到优化版本。考虑到在其他优化中,V8最初已内联代码,这是一项非常复杂的任务。V8不是唯一能够做到这一点的引擎。
有一种称为反优化的保护措施,可以进行相反的转换,并在假设引擎不再适用的情况下还原为未优化的代码。
垃圾收集
对于垃圾收集,V8使用标记清除的传统世代方法来清理旧世代。标记阶段应该停止JavaScript执行。为了控制GC成本并使执行更加稳定,V8使用了增量标记:不是遍历整个堆而是尝试标记每个可能的对象,是遍历堆的一部分,然后恢复正常执行。下一个GC停止将从上一个堆漫游已停止的位置继续。这允许在正常执行期间非常短的暂停。如前所述,清除阶段由单独的线程处理。
Ignition和TurboFan
随着2017年初V8 5.9的发布,引入了新的执行管道。这个新的管道在实际的 JavaScript应用程序中实现了更大的性能改进并显着节省了内存。
新的执行管道基于V8的解释器Ignition和V8的最新优化编译器TurboFan构建。
您可以在此处查看 V8团队有关该主题的博客文章。
自V8的5.9版问世以来,由于V8团队一直在努力跟上新的JavaScript语言功能,并且V8团队一直在努力与之同步,因此完整代码源和Crankshaft(自2010年起为V8服务的技术)不再被V8用于JavaScript执行。这些功能所需的优化。
这意味着整个V8将会拥有更简单,更易于维护的体系结构。
这些改进仅仅是开始。新的Ignition和TurboFan管道为进一步优化铺平了道路,这些优化将在未来几年内提高JavaScript性能并缩小V8在Chrome和Node.js中的占用空间。
最后,这是有关如何编写经过优化的更好JavaScript的一些技巧。您可以从上面的内容中轻松获得这些内容,但是,为方便起见,以下是摘要:
如何编写优化的JavaScript
- 对象属性的顺序:始终以相同的顺序实例化对象属性,以便可以共享隐藏的类以及随后优化的代码。
- 动态属性:实例化后向对象添加属性将强制更改隐藏类,并减慢为上一个隐藏类优化的所有方法。而是在其构造函数中分配对象的所有属性。
- 方法:重复执行相同方法的代码将比仅执行一次许多不同方法的代码(由于内联缓存)运行得更快。
- 数组:避免键不是增量数字的稀疏数组。里面没有所有元素的稀疏数组是一个哈希表。这种阵列中的元素访问起来更昂贵。另外,请尝试避免预先分配大数组。最好随身携带。最后,不要删除数组中的元素。它使键稀疏。
- 标记的值:V8代表32位的对象和数字。它使用一个位来知道它是一个对象(标志= 1)还是一个称为SMI(小整数)的整数(标志= 0),因为它有31位。然后,如果数值大于31位,则V8会将数字装箱,将其变成双精度并创建一个新对象以将数字放入其中。尽可能使用31位带符号的数字,以避免对JS对象进行昂贵的装箱操作。
三、JavaScript的工作方式:内存管理+如何处理4个常见的内存泄漏
几周前,我们开始了一系列旨在更深入地研究JavaScript及其实际工作的系列:我们认为,通过了解JavaScript的构造块以及它们如何一起发挥作用,您将能够编写更好的代码和应用程序。
该系列的第一篇文章重点介绍了引擎,运行时和调用栈的概述。Thе 第二后仔细研究谷歌的V8 JavaScript引擎的内部零件,也提供了有关如何写出更好的JavaScript代码的一些提示。
在这第三篇文章中,我们将讨论另一个关键主题,由于每天使用的编程语言的日趋成熟和复杂性日益增加,因此开发人员越来越不重视它了,即内存管理。我们还将提供一些有关如何处理SessionStack中JavaScript内存泄漏的技巧,因为我们需要确保SessionStack不会导致内存泄漏或不会增加集成的Web应用程序的内存消耗。
总览
像C这样的语言具有诸如malloc()和的低级内存管理原语free()。这些原语由开发人员用来在操作系统之间显式分配和释放内存。
同时,JavaScript在创建事物(对象,字符串等)时分配内存,并在不再使用它们时“自动”释放内存,此过程称为垃圾回收。释放资源的这种看似“自动”的特性引起了混乱,并给JavaScript(和其他高级语言)开发人员带来了错误的印象,他们可以选择不关心内存管理。 这是一个大错误。
即使使用高级语言,开发人员也应该对内存管理有所了解(或至少是基础知识)。有时,自动内存管理存在一些问题(例如错误或垃圾收集器中的实现限制等),开发人员必须了解这些问题,以便正确处理它们(或找到一种适当的解决方法,并以最小的权衡和代码来实现)。
内存生命周期
无论您使用哪种编程语言,内存生命周期几乎总是相同的:
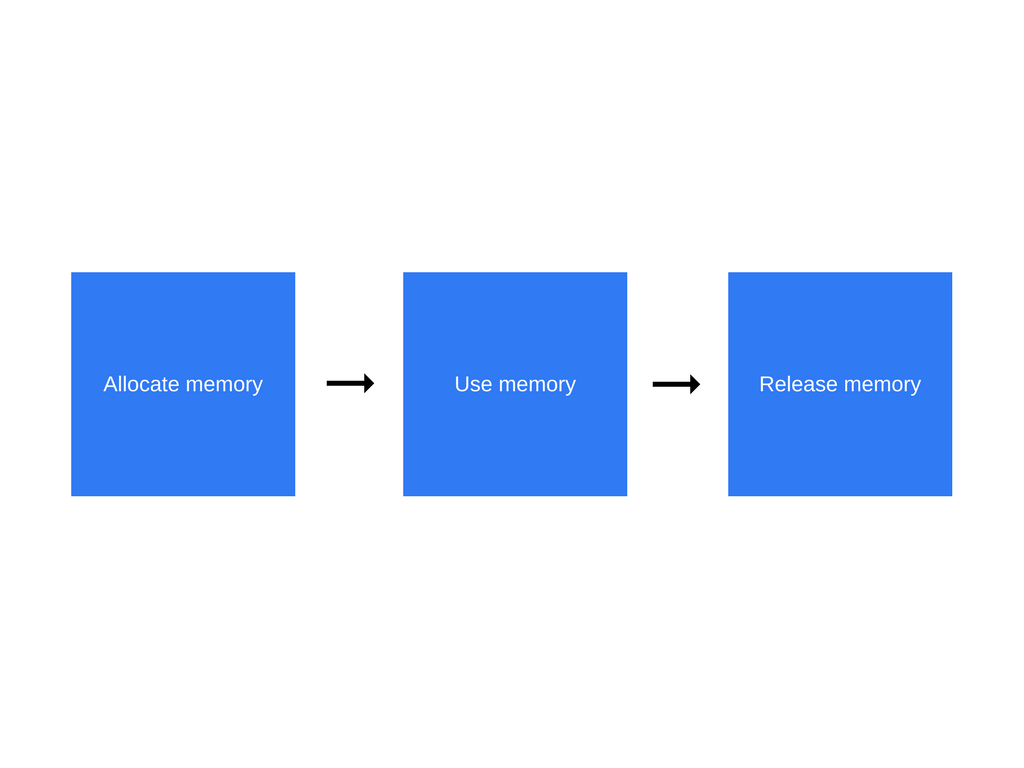
以下是在每个周期步骤中发生的情况的概述:
- 分配内存 -内存是由操作系统分配的,允许您的程序使用它。在低级语言(例如C)中,这是开发人员应处理的显式操作。但是,在高级语言中,这会为您解决。
- 使用内存-这是您的程序实际使用先前分配的内存的时间。读取和写入操作都为你使用在代码中分配的变量发生。
- 释放内存 -现在是释放不需要的全部内存的时候了,这样它就可以释放并再次可用。与分配内存操作一样,此操作在底层语言中是显式的。
什么是内存?
在直接进入JavaScript的内存之前,我们将简要讨论一下一般的内存以及其概述。
在硬件级别上,计算机内存由大量触发器组成。每个触发器包含几个晶体管,并且能够存储一位。单个触发器可通过唯一标识符寻址,因此我们可以读取和覆盖它们。因此,从概念上讲,我们可以将整个计算机内存视为可以读取和写入的一个巨大的位数组。
由于作为人类,我们并不擅长以位为单位进行所有思维和算术运算,因此我们将它们组织为更大的组,这些组可以一起用来表示数字。8位称为1个字节。除了字节,还有字(有时为16,有时为32位)。
很多东西都存储在此内存中:
- 所有程序使用的所有变量和其他数据。
- 程序的代码,包括操作系统的代码。
编译器和操作系统一起工作,可以为您处理大部分内存管理,但是我们建议您了解幕后的情况。
当您编译代码时,编译器可以检查原始数据类型并提前计算它们将需要多少内存。然后将所需的数量分配到调用堆栈空间中的程序。分配这些变量的空间称为堆栈空间,因为在调用函数时,它们的内存会添加到现有内存的顶部。当它们终止时,将按照LIFO(后进先出)的顺序删除它们。例如,考虑以下声明:
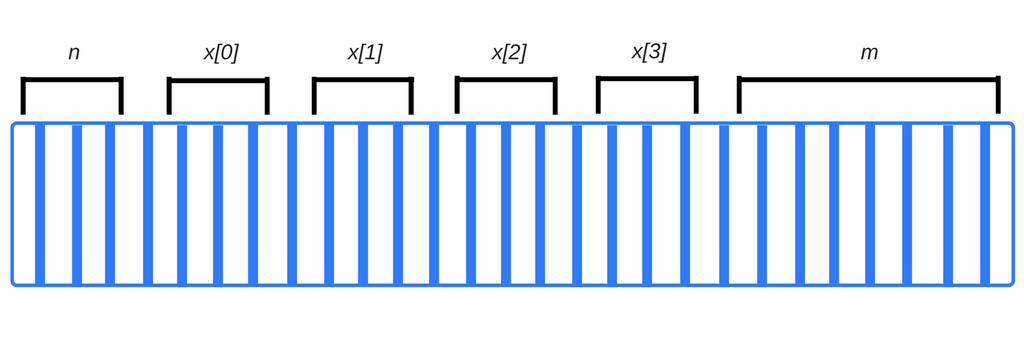
int n; // 4 bytes int x[4]; // array of 4 elements, each 4 bytes double m; // 8 bytes
编译器可以立即看到该代码需要
4 + 4×4 + 8 = 28个字节。
这就是使用整数和双精度数的当前大小的方式。大约20年前,整数通常是2个字节,是4个字节的两倍。您的代码现在永远不必依赖基本数据类型的大小。
编译器将插入与操作系统交互的代码,以请求在堆栈上存储所需要的变量字节数。
在上面的示例中,编译器知道每个变量的确切内存地址。实际上,每当我们写入变量时n,它就会在内部翻译为类似“内存地址4127963”的内容。
注意,如果尝试在x[4]此处访问,我们将访问与m关联的数据。这是因为我们正在访问数组中不存在的元素-它比数组中最后一个实际分配的元素x[3]要高4个字节,并可能最终读取(或覆盖)某些m的bit。这几乎肯定会对程序的其余部分产生非常不利的后果。
当函数调用其他函数时,每个函数在调用时都会获得自己的堆栈块。它将所有局部变量都保留在那里,还有一个程序计数器,它记住执行它的位置。功能完成后,其存储块将再次用于其他目的。
动态分配
不幸的是,当我们在编译时一个不知道需要多少内存的变量时,事情就变得不那么容易了。假设我们要执行以下操作:
int n = readInput(); // reads input from the user ... // create an array with "n" elements
在这里,在编译时,编译器不知道该数组需要多少内存,因为它由用户提供的值确定。
因此,它不能为堆栈上的变量分配空间。相反,我们的程序需要在运行时明确要求操作系统提供适当的空间量。该内存是从堆空间分配的。下表总结了静态和动态内存分配之间的区别:

为了完全理解动态内存分配是如何工作的,我们需要花更多的时间在指针上。
JavaScript中的分配
现在,我们将说明第一步(分配内存)在JavaScript中的工作方式。
JavaScript减轻了开发人员处理内存分配的责任-JavaScript自己完成,同时声明了值。
var n = 374; // allocates memory for a number var s = 'sessionstack'; // allocates memory for a string var o = { a: 1, b: null }; // allocates memory for an object and its contained values var a = [1, null, 'str']; // (like object) allocates memory for the // array and its contained values function f(a) { return a + 3; } // allocates a function (which is a callable object) // function expressions also allocate an object someElement.addEventListener('click', function() { someElement.style.backgroundColor = 'blue'; }, false);
一些函数调用也会导致对象分配:
var d = new Date(); // allocates a Date object var e = document.createElement('div'); // allocates a DOM element
方法可以分配新的值或对象:
var s1 = 'sessionstack'; var s2 = s1.substr(0, 3); // s2 is a new string // Since strings are immutable, // JavaScript may decide to not allocate memory, // but just store the [0, 3] range. var a1 = ['str1', 'str2']; var a2 = ['str3', 'str4']; var a3 = a1.concat(a2); // new array with 4 elements being // the concatenation of a1 and a2 elements
在JavaScript中使用内存
基本上,在JavaScript中使用分配的内存意味着对其进行读写。
这可以通过读取或写入变量或对象属性的值,甚至将参数传递给函数来完成。
当不再需要内存时释放
大多数内存管理问题都在此阶段出现。
这里最困难的任务是弄清何时不再需要分配的内存。它通常要求开发人员确定程序中不再需要该内存的位置,然后释放它。
高级语言嵌入了一个称为垃圾收集器的软件,该软件的工作是跟踪内存分配和使用情况,以查找何时不再需要分配的内存,在这种情况下,它将自动释放内存。
不幸的是,这个过程是一个近似值,因为知道是否需要一些一块内存的一般问题是不可判定(无法通过算法来解决)。
大多数垃圾收集器通过收集无法访问的内存来工作,例如,指向该内存的所有变量都超出范围。但是,这是可以收集的一组存储空间的近似值,因为在任何时候,某个存储位置在范围上仍可能有一个指向它的变量,但是将永远不会再次访问它。
垃圾收集
由于无法确定是否“不再需要”某些内存,因此垃圾回收对一般问题实施了解决方案的限制。本节将解释必要的概念,以了解主要的垃圾收集算法及其局限性。
内存参考
垃圾收集算法所依赖的主要概念是参考之一。
在内存管理的上下文中,如果一个对象可以访问另一个对象(可以隐式或显式),则称该对象引用另一个对象。例如,JavaScript对象具有对其原型的引用(隐式引用)及其属性的值(显式引用)。
在这种情况下,“对象”的概念扩展到比常规JavaScript对象更广泛的范围,并且还包含函数作用域(或全局词法作用域)。
词法作用域定义了如何在嵌套函数中解析变量名:即使父函数已返回,内部函数也包含父函数的范围。
引用计数垃圾收集
这是最简单的垃圾收集算法。如果指向该对象的引用为零,则该对象被视为“垃圾可收集” 。
看下面的代码:
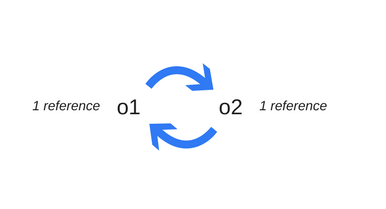
var o1 = { o2: { x: 1 } }; // 2 objects are created. // 'o2' is referenced by 'o1' object as one of its properties. // None can be garbage-collected var o3 = o1; // the 'o3' variable is the second thing that // has a reference to the object pointed by 'o1'. o1 = 1; // now, the object that was originally in 'o1' has a // single reference, embodied by the 'o3' variable var o4 = o3.o2; // reference to 'o2' property of the object. // This object has now 2 references: one as // a property. // The other as the 'o4' variable o3 = '374'; // The object that was originally in 'o1' has now zero // references to it. // It can be garbage-collected. // However, what was its 'o2' property is still // referenced by the 'o4' variable, so it cannot be // freed. o4 = null; // what was the 'o2' property of the object originally in // 'o1' has zero references to it. // It can be garbage collected.
周期制造问题
循环有一个限制。在下面的示例中,创建了两个对象并互相引用,从而创建了一个循环。它们将在函数调用后走出循环,因此它们实际上是无用的并且可以被释放。但是,引用计数算法认为,由于两个对象中的每个对象都至少被引用了一次,因此都无法进行垃圾回收。
function f() { var o1 = {}; var o2 = {}; o1.p = o2; // o1 references o2 o2.p = o1; // o2 references o1. This creates a cycle. } f();
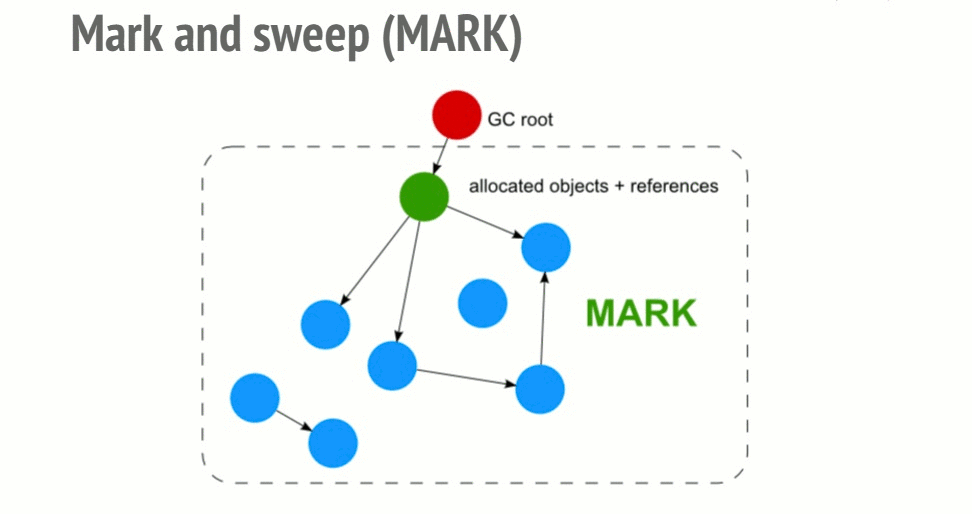
扫频算法
为了确定是否需要对象,该算法确定该对象是否可到达。
标记扫描算法通过以下三个步骤:
- 根:根通常是在代码中引用的全局变量。例如,在JavaScript中,可以充当根的全局变量是“窗口”对象。Node.js中相同的对象称为“全局”。垃圾收集器将构建所有根的完整列表。
- 然后,该算法将检查所有根及其子级并将其标记为活动状态(这意味着它们不是垃圾)。根无法到达的任何内容都将被标记为垃圾。
- 最后,垃圾收集器释放所有未标记为活动的内存,并将该内存返回给OS。
该算法比上一个算法更好,因为“一个对象具有零参考”导致该对象不可访问。
截至2012年,所有现代浏览器都附带了标记清除垃圾收集器。过去几年在JavaScript垃圾收集领域(世代/增量/并行/并行垃圾收集)所做的所有改进都是该算法(标记扫描)的实现改进,但不是垃圾收集算法本身的改进,也不是其目标是确定对象是否可到达。
在本文中,您可以详细了解有关跟踪垃圾收集的内容,该垃圾收集还涵盖了标记清除及其优化。
周期不再是问题
在上面的第一个示例中,在函数调用返回之后,全局对象可访问的对象不再引用这两个对象。因此,将发现垃圾回收器无法访问它们。
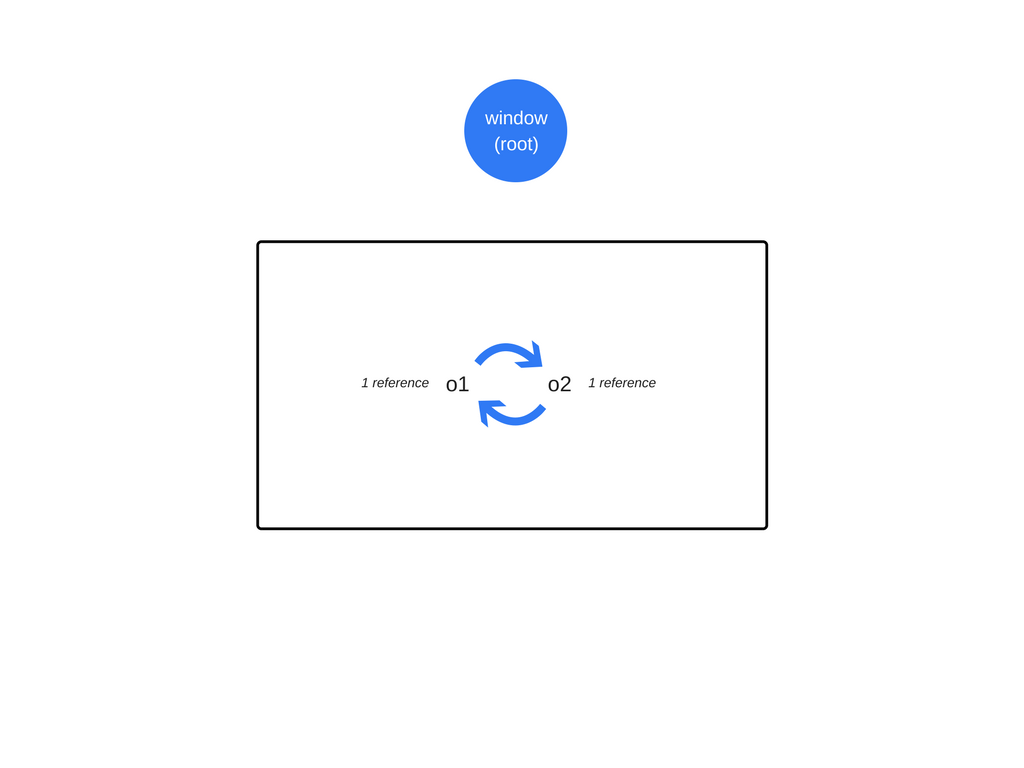
即使在对象之间存在引用,也无法从根目录访问它们。
反垃圾收集器的直观行为
尽管垃圾收集器很方便,但它们还是有自己的权衡。其中之一是不确定性。换句话说,GC是不可预测的。您无法真正确定何时执行收集。这意味着在某些情况下程序会使用实际需要的更多内存。在其他情况下,短暂停可能在特别敏感的应用中很明显。尽管不确定性意味着无法确定何时执行收集,但是大多数GC实现在分配过程中共享执行收集遍历的通用模式。如果不执行任何分配,则大多数GC保持空闲状态。请考虑以下情形:
- 执行大量分配。
- 这些元素中的大多数(或全部)都标记为不可访问(假设我们将指向不再需要的缓存的引用为空)。
- 不再执行任何分配。
在这种情况下,大多数GC将不再运行任何进一步的收集过程。换句话说,即使有不可达的引用可用于收集,收集器也不会主张这些引用。这些并不是严格的泄漏,但是仍然会导致内存使用率高于正常水平。
什么是内存泄漏?
就像内存暗示的那样,内存泄漏是应用程序使用过但不再需要并且尚未返还到操作系统或空闲内存池的内存。
编程语言支持不同的内存管理方式。但是,是否使用某个内存实际上是一个不确定的问题。换句话说,只有开发人员才能弄清楚是否可以将一块内存返回给操作系统。
某些编程语言提供的功能可帮助开发人员执行此操作。其他人则希望开发人员完全清楚何时未使用内存。维基百科上有很多有关手动和自动内存管理的文章。
常见的JavaScript泄漏的四种类型
1:全局变量
JavaScript以一种有趣的方式处理未声明的变量:当引用未声明的变量时,将在全局对象中创建一个新变量。在浏览器中,全局对象为window,这意味着
function foo(arg) { bar = "some text"; }
等价于:
function foo(arg) { window.bar = "some text"; }
假设的目的bar是仅在foo函数中引用变量。但是,如果不使用var它来声明它,则会创建一个冗余的全局变量。在上述情况下,这不会造成太大伤害。您当然可以想象一个更具破坏性的场景。
您也可以使用this以下方式意外创建全局变量:
function foo() { this.var1 = "potential accidental global"; } // Foo called on its own, this points to the global object (window) // rather than being undefined. foo();
您可以通过
‘use strict’;在JavaScript文件的开头添加来避免所有这些情况,这将打开更为严格的JavaScript解析模式,以防止意外创建全局变量。
意外的全局变量无疑是一个问题,但是,您的代码经常会被显式的全局变量所感染,根据定义,这些变量不能被垃圾收集器收集。需要特别注意用于临时存储和处理大量信息的全局变量。如有必要,请使用全局变量存储数据,但在执行此操作时,请确保将其分配为null或在完成处理后将其重新分配。(手动清理内存)
2:被遗忘的计时器或回调
让我们setInterval举个例子,因为它经常在JavaScript中使用。
提供观察者和接受回调的其他工具的库通常会确保一旦实例也无法访问,所有对回调的引用都将变得不可访问。不过,下面的代码并非罕见:
var serverData = loadData(); setInterval(function() { var renderer = document.getElementById('renderer'); if(renderer) { renderer.innerHTML = JSON.stringify(serverData); } }, 5000); //This will be executed every ~5 seconds.
上面的代码片段显示了使用计时器引用不再需要的节点或数据的后果。
该renderer对象可以被替换或者在某些时候这将使由间隔处理机冗余封装块移除。如果发生这种情况,则将不收集处理程序或其依赖项,因为将需要首先停止该间隔(请记住,该间隔仍处于活动状态)。归根结底serverData,肯定存储和处理数据负载的事实也不会被收集。
使用观察者时,您需要确保对它们进行一次明确的调用以将其删除(不再需要观察者,否则该对象将变得不可访问)。
幸运的是,大多数现代浏览器都会为您完成这项工作:一旦观察到的对象变得不可访问,即使您忘记删除侦听器,它们也会自动收集观察者处理程序。过去,某些浏览器无法处理这些情况(较旧的IE6)。
尽管如此,一旦对象过时,删除观察者仍然符合最佳实践。请参见以下示例:
var element = document.getElementById('launch-button'); var counter = 0; function onClick(event) { counter++; element.innerHtml = 'text ' + counter; } element.addEventListener('click', onClick); // Do stuff element.removeEventListener('click', onClick); element.parentNode.removeChild(element); // Now when element goes out of scope, // both element and onClick will be collected even in old browsers // that don't handle cycles well.
您不再需要removeEventListener在使节点不可访问之前进行调用,因为现代浏览器支持可以检测这些周期并适当处理它们的垃圾收集器。
如果您使用jQueryAPI(其他库和框架也支持此功能),则也可以在使节点过时之前删除侦听器。该库还将确保即使应用程序在较旧的浏览器版本下运行,也不会发生内存泄漏。
3:闭包
JavaScript开发的关键方面是闭包:内部函数可以访问外部(封闭的)函数的变量。由于JavaScript运行时的实现细节,可能通过以下方式泄漏内存:
var theThing = null; var replaceThing = function () { var originalThing = theThing; var unused = function () { if (originalThing) // a reference to 'originalThing' console.log("hi"); }; theThing = { longStr: new Array(1000000).join('*'), someMethod: function () { console.log("message"); } }; }; setInterval(replaceThing, 1000);
一旦replaceThing调用,theThing将获得一个由大数组和新闭包(someMethod)组成的新对象。但是,originalThing被unused变量所持有的闭包引用,(the Thing是之前replaceThing调用的变量)。要记住的是,一旦为同一个父域中的闭包创建了闭包域,就将共享该域。
这个代码片段做了一件事:每次replaceThing被调用的时候,theThing获取到一个包括一个大数组和新闭包(somMethod)的新对象。同时,变量unused保留了一个有originalThing(theThing从之前的对replaceThing的调用)引用的闭包。已经有点疑惑了,哈?重要的是一旦一个作用域被在同个父作用域下的闭包创建,那个作用域是共享的。这种情况下,为闭包somMethod创建的作用域被unused共享了。unused有一个对originalThing的引用。即使unused从来没被用过,someMethod可以通过theTing被使用。由于someMethod和unused共享了闭包作用域,即使unused从来没被用过,它对originalThing的引用迫使它停留在活跃状态(不能回收)。当这个代码片段重复运行的时候,可以看到内存使用稳步的增长。GC运行的时候,这并不会减轻。本质上,一组关联的闭包被创建(同unused变量在表单中的根节点一起),这些闭包作用域中每个带了大数组一个非直接的引用,导致了大型的泄漏。
所有这些都会导致相当大的内存泄漏。当上述代码片段一遍又一遍地运行时,您可能会看到内存使用量激增。当垃圾收集器运行时,它的大小不会缩小。创建一个闭包的链表(theThing在这种情况下,其根是可变的),每个闭包作用域都对大数组进行间接引用。
流星团队发现了此问题,他们有一篇很棒的文章详细介绍了该问题。
4:超出DOM引用
有时存储DOM节点到数据结构中可能有用。假设你想要迅速的更新一个表格几行内容。存储每个DOM行节点的引用到一个字典或数组会起作用。当这发生是,两个对于同个DOM元素的引用被留存:一个在DOM树中,另外一个在字典中。如果在将来的某些点你决定要移除这些行,需要让两个引用都不可用。
var elements = { button: document.getElementById('button'), image: document.getElementById('image'), text: document.getElementById('text') }; function doStuff() { image.src = 'http://some.url/image'; button.click(); console.log(text.innerHTML); // Much more logic } function removeButton() { // The button is a direct child of body. document.body.removeChild(document.getElementById('button')); // At this point, we still have a reference to #button in the global // elements dictionary. In other words, the button element is still in // memory and cannot be collected by the GC. }
在引用DOM树中的内部或叶节点时,还需要考虑其他因素。如果您<td>在代码中保留对表单元格(标记)的引用,并决定从DOM中删除表,但仍保留对该特定单元格的引用,则可能会发生大量内存泄漏。您可能会认为垃圾收集器将释放除该单元格之外的所有内容。但是,事实并非如此。由于单元格是表的子节点,并且子级保留对其父级的引用,因此对表单元格的单个引用会将整个表保留在内存中。
本文译自:
1.https://blog.sessionstack.com/how-does-javascript-actually-work-part-1-b0bacc073cf