十年河东,十年河西,莫欺少年穷
学无止境,精益求精
CSDN上资源下载地址:https://download.csdn.net/download/wolongbb/15420395 【包括kafka /java8/ ZooKeeper】并且和本博客所用版本一致。
一、安装JAVA JDK1、下载安装包
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
注意:根据32/64位操作系统下载对应的安装包
2、添加系统变量:JAVA_HOME=C:Javajdk1.8.0_40
二、安装ZooKeeperkafka依赖ZooKeeper,因此,在启动kafka之前,应先安装启动ZooKeeper,启动ZooKeeper之前,应先配置ZooKeeper的环境变量。
1、 下载安装包 http://zookeeper.apache.org/releases.html#download
2、 解压并进入ZooKeeper目录,我的目录为:D: oolkafkaapache-zookeeper-3.6.2-bin
3、 在目录中的conf文件夹中找到zoo_sample.cfg,并将“zoo_sample.cfg”重命名为“zoo.cfg”
4、 打开“zoo.cfg”找到并编辑 dataDir=./zookeeper-3.4.13/data
5、admin.serverPort端口默认为8080,如果8080被占用,需要指定admin.serverPort端口,在zoo.cfg最后一行增加:admin.serverPort=8001
6、audit.enable 默认为 false,我们设置为 true,在zoo.cfg最后一行增加:audit.enable=true
7、添加系统变量:ZOOKEEPER_HOME=D: oolkafkaapache-zookeeper-3.6.2-bin
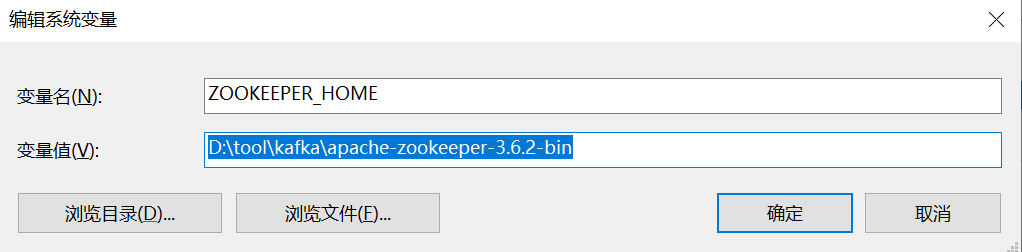
8、编辑path系统变量,添加路径:%ZOOKEEPER_HOME%in
9、在zoo.cfg文件中修改默认的Zookeeper端口(默认端口2181),如果端口2181未被占用,则无需修改。
10、打开新的cmd,输入“zkServer“,运行Zookeeper,cmd需要指定目录:D: oolkafkaapache-zookeeper-3.6.2-bin 【注意:我的文件夹命名中带有bin,而不是指向bin文件夹】,也可以在D: oolkafkaapache-zookeeper-3.6.2-bin 文件夹中,按住 shift 键,右键鼠标,打开:windows power shell。
11、按照第10步,输入 zkServe 后,如果出现如下界面,则证明ZooKeeper启动成功。
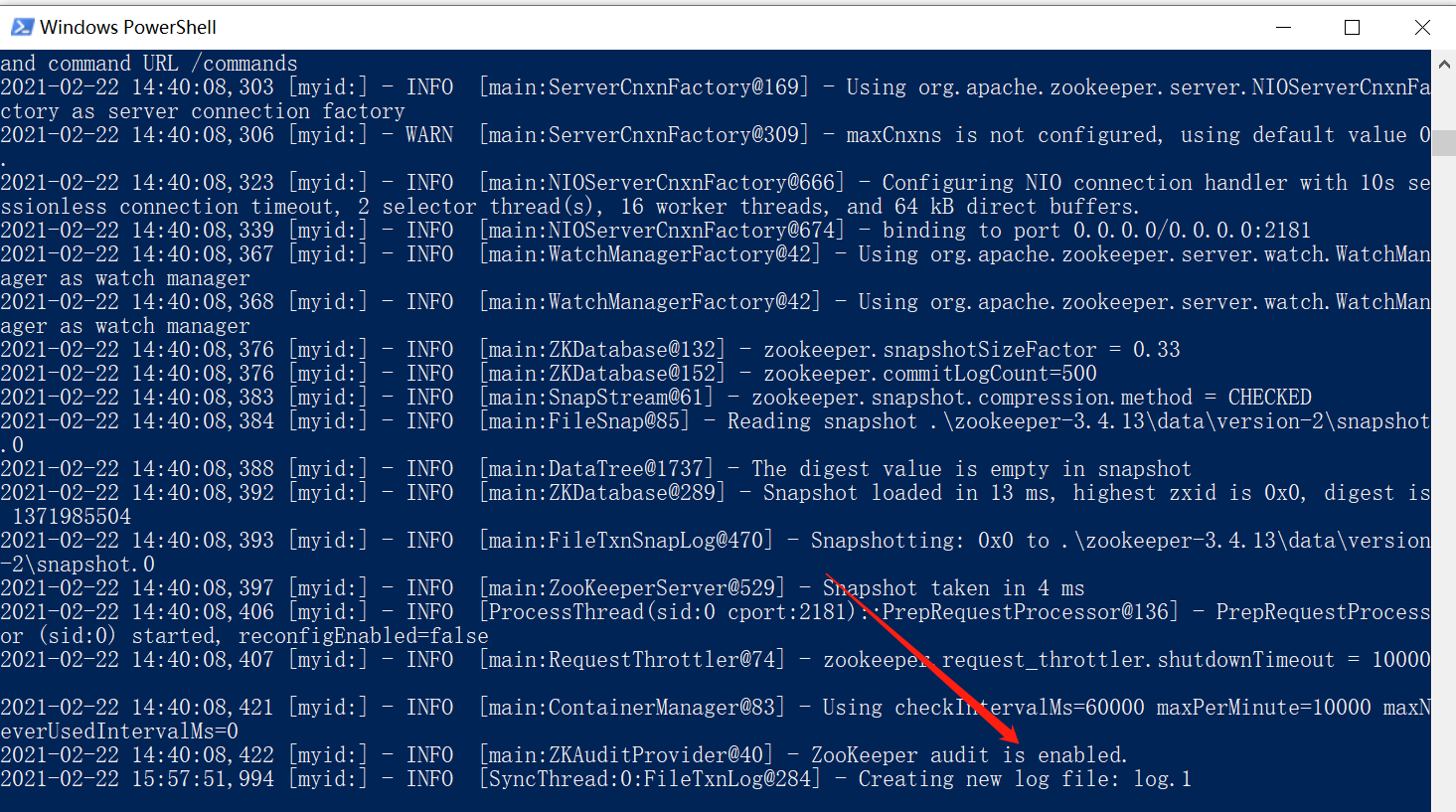
注意:不要关了这个窗口,启动kafka时会用到。
上述11个步骤中,我所遇到的坑如下:
坑1:
下载安装包时,应下载命名中带有bin的文件,不要去下载source文件,无论安装ZooKeeper 还是 kafka 安装路径中都不要有空格。切记。要考。
通过HTTP下载即可:

坑2:
我的服务器中,admin.serverPort 的默认端口8080被占用了,导致启动时报错,因此,我显式指定了端口为:8001
坑3:
建议增加这个配置:audit.enable=true,关于这个配置,我并不知道干啥用的
三、安装Kafka1、 下载安装包 :http://kafka.apache.org/downloads 【注意要下载二进制版本】
2、 解压并进入Kafka目录,我的路径:D: oolkafkakafka_2.12-2.7.0
3、 进入config目录找到文件server.properties并打开
4、 找到并编辑:log.dirs=./logs
5、 找到并编辑zookeeper.connect=localhost:2181 【非集群部署的情况下,无需修改】
6、 Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2181 【注意9092端口不应该被其他程序占用】
7、 进入Kafka安装目录D: oolkafkakafka_2.12-2.7.0inwindows,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
kafka-server-start.bat ....configserver.properties
如果不行

请使用:
.kafka-server-start.bat ....configserver.properties
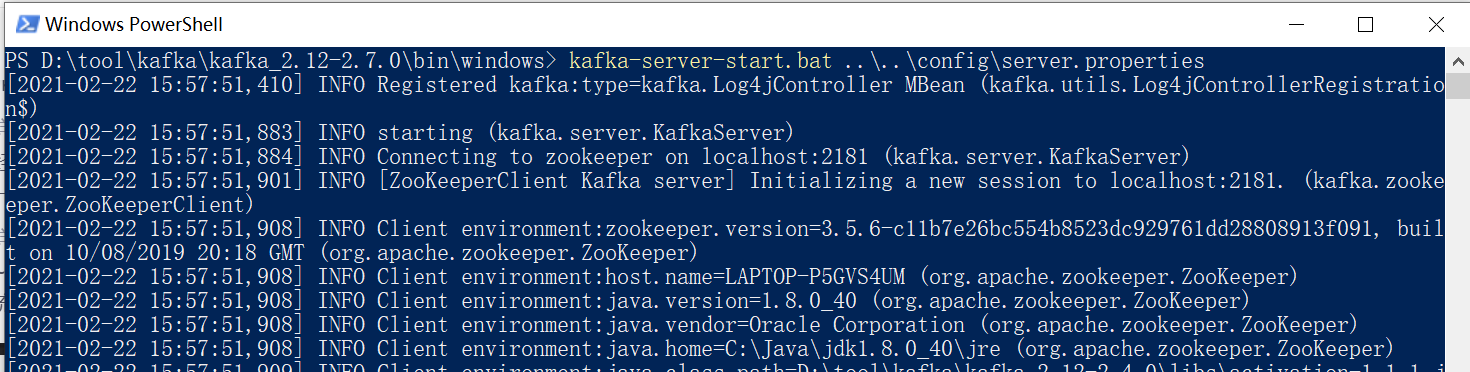
注意:不要关了这个窗口,启用Kafka前请确保ZooKeeper实例已经准备好并开始运行
上述7个步骤中,我遇到的坑如下:
坑1、
环境变量Path要增加,如下截图:
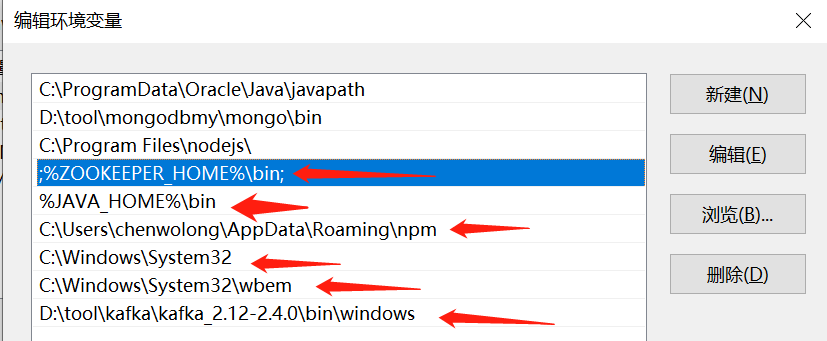
分别如下:
1、ZOOKEEPER_HOME ,kafka依赖,安装ZooKeeper 时,就需要配置
%ZOOKEEPER_HOME%in
2、系统路径,这个据说和 wbem 文件夹下的exe有关,没有的话,加上这两个系统路径变量
C:WindowsSystem32
C:WindowsSystem32wbem3、据说和启动kafka有关,经过我的测试,应该没关系,不管有没有关系,加上保险一点。
D: oolkafkakafka_2.12-2.4.0inwindows
坑2
进入Kafka安装目录D: oolkafkakafka_2.12-2.7.0inwindows,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:kafka-server-start.bat ....configserver.properties
但:
好多博客上都是进入D: oolkafkakafka_2.12-2.7.0 安装路径 ,然后执行:
.inwindowskafka-server-start.bat .configserver.properties
但,在我测试的过程中,执行 .inwindowskafka-server-start.bat .configserver.properties 无任何响应。
通用启动方式:
通用启动方式【统一在kafka文件夹中启动,利用自带的bat文件】
最后按照知乎作者的方案,通过kafka自带的bat文件启动相关服务:
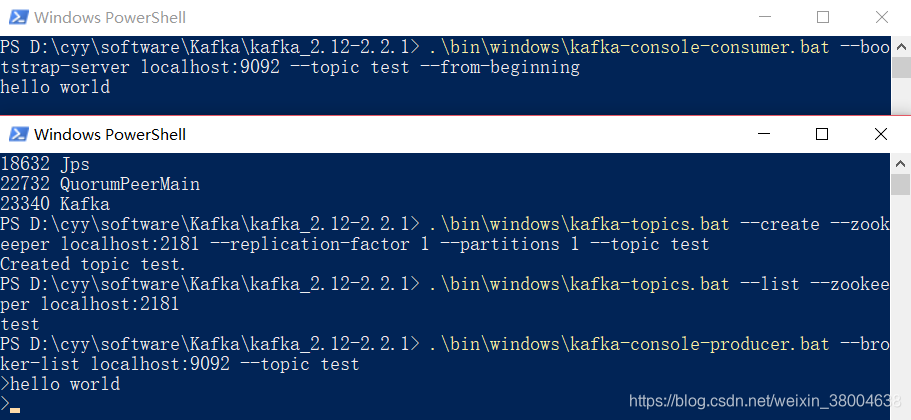
它们都需要进入 D: oolkafkakafka_2.12-2.7.0 目录,然后再启动相应的命令。 cd D:kafka_2.11-2.4.0 启动zookeeper服务,运行命令: binwindowszookeeper-server-start.bat configzookeeper.properties 启动kafka服务,运行命令: binwindowskafka-server-start.bat configserver.properties
(linux直接在bin目录下.sh,windows需要进入binwinndows下的.bat)
1、 创建主题,进入Kafka安装目录D:Kafkakafka_2.12-0.11.0.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.inwindowskafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
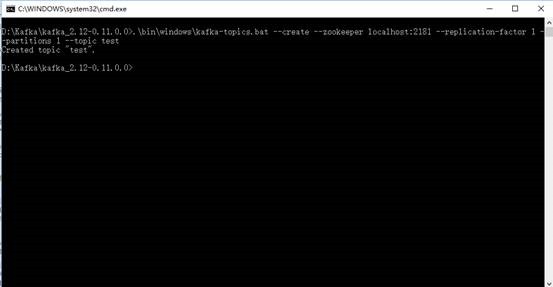
注意:不要关了这个窗口
2、查看主题输入:
.inwindowskafka-topics.bat --list --zookeeper localhost:2181
3、 创建生产者,进入Kafka安装目录D:Kafkakafka_2.12-0.11.0.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.inwindowskafka-console-producer.bat --broker-list localhost:9092 --topic test
注意:不要关了这个窗口
4、 创建消费者,进入Kafka安装目录D:Kafkakafka_2.12-0.11.0.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.inwindowskafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning此时,往生产者窗口写入消息,消费者窗口也能同步的接收到消息

5、查看topic,进入Kafka安装目录D:Kafkakafka_2.12-0.11.0.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
- .binwindowskafka-topics.bat --describe --zookeeper localhost:2181 --topic
- test

6、 重要(操作日志的处理):
kafka启动后,如果你去查看kafka所在的根目录,或者是kafka本身的目录,会发现已经默认生成一堆操作日志(这样看起来真心很乱):
而且会不断生成不同时间戳的操作日志。刚开始不知所措,一番研究后,看了启动的脚本内容,发现启动的时候是会默认使用到这个log4j.properties文件中的配置,而在zoo.cfg是不会看到本身的启动会调用到这个,还以为只有那一个日志路径:
在这里配置一下就可以了,找到config下的log4j.properties:
zookeeper.log.dir=D: oolkafkaLogs
将路径更改下即可,这样就可以归档在一个文件夹下边了,路径根据自己喜好定义:
另外如何消除不断生成日志的问题,就是同一天的不同时间会不停生成。
修改这里,还是在log4j.properties中:
本身都为trace,字面理解为会生成一堆跟踪日志,将其改为INFO即可。
kafka server.properties 配置文件详解(二)虽然在前面一部分我们启动了kafka集群,并通过控制台的方式实现了producer和consumer,但是我们还是了解一下kafka单个节点是的配置参数属性,
也只有了解了这些参数的配置,才能将kafka的性能发挥到最好。
标红部分为集群必配属性,致于其它的参数配置等学完后再回过头来看这些参数,你就知道是什么意思了
1.broker.id
broker.id=2 一般采用ip的后三位来用来标识是哪台kafka的broker,利于定位和排错
2.Prot
tcp用来监控的kafka端口
listeners=PLAINTEXT://192.168.43.17:9092
3.Zookeeper.connect
#kafka连接zk的集群,多个用”,”号隔开
#zookeeper.connect=192.168.43.15:2181,192.168.43.16:2181,192.168.43.17:2181
#但是这样写不是很友好,kafka在连上zk后,直接在zk的根目录创建自己需要的文件夹,这样会导致zk的根目录也非常乱
#同时如果有别的项目也在用zk创建1个controller目录,kafka会产生一个controller的文件夹,这样会导致混淆
#如果需要部署2个独立的kafka storm环境时,只有一个zk集群时
#综上所述,可以采用命名空间的方式解决以上问题:
zookeeper.connect=192.168.43.15:2181,192.168.43.16:2181,192.168.43.17:2181/kafka_1(推荐使用这2种方式)
zookeeper.connect=192.168.43.15:2181,192.168.43.16:2181,192.168.43.17:2181/kafka_2
4.Log.dirs(commit log)
#用来存储日志的路径,它上面存放了多个log segment,如果采用了磁盘阵列,路径可以是多个
#如果采用了多个存储路径,1个partition只能存放在1个路径下,因为顺序的磁盘读写操作速度
#可以接近随机的内存读写速度
log.dirs=/var/lib/kafka
5.num.recovery.threads.per.data.dir=1
#kafka配置了1个线程池,当kafka启动时打开每个segment,启动失败时检查并截取每个segment
#服务关闭时,关闭segments的句柄、管道的flush操作,
num.recovery.threads.per.data.dir=1
#注意是1个路径默认是1个线程,如果log.dirs配置了3个路径,那么将会有24个线程
6.auto crteat.topics.enable(配置文件中没有)
#自动创建1个topic
#当不存在1个topic时会创建,读的时候会创建1个topic,通过api访问元数据时,如果不存在会创建1个topic
#但是这个创建的tpoic都是采用默认的配置,因此不建议使用
# 一般情况下我们设置成false
7.num.partitions
#设置partitions 的个数
num.partitions=1
8.log.retention.ms
#日志存放时间,依据是文件最后1次更新文件的时间,这个参数是针对broker的,按小时来算的
log.retention.hours=168
#存放1个星期
9.log.retention.bytes
#partition保留数据的大小,这个参数是针对1个partitions 的
#如果有8个partition,每个partition设置的是1GB,那最多存8GB的东西,超过了就会将老的数据删除
log.retention.bytes=1073741824
10.log.segment.bytes
#设置segment 片断的大小,如果存放的达到了设置的大小,这个segment 将会关闭,并且将会
#创建1个新的打开的segment,如果1个segment达到了设置的大小并且已关闭,那么这个segment是可
#以被删除的,如果这个segment设置的小,则会频繁的创建segment,会影响kafka的性能,如果设置的较大
#超过了log.retention.ms的保存时间,这样会造成数据不一致或丢失的情况,因此,设置每个segment的
#大小还是要根据业务量来判断
log.segment.bytes=1073741824
11.log.segment.ms
#另一种控制segments关闭的参数设置
log.segment.ms
12.message.max.bytes
#发送信息的最大单位值,如果超过了,会造成数据丢失
#如果要发送的数据量较大,可以调整这个参数和检查发送数据量的
message.max.bytes=1024最后,提供下kafka可视化工具下载地址:https://download.csdn.net/download/wolongbb/15433836
参考文献:
https://www.cnblogs.com/xuzimian/p/10138442.html 【我的成功所在】
https://blog.csdn.net/weixin_38004638/article/details/91893910 【CSDN】
https://stackoverflow.com/questions/58754086/answer/submit 【英文站点BBS】