什么是评估机器学习模型
机器学习的目的是得到可以泛化(generalize)的模型,即在前所未见的数据上表现很好的模型,而过拟合则是核心难点。你只能控制可以观察的事情,所以能够可靠地衡量模型的泛化能力非常重要。
如何衡量泛化能力,即如何评估机器学习模型。
评估模型的重点是将数据划分为三个集合:训练集、验证集和测试集。在训练数据上训练模型,在验证数据上评估模型。一旦找到了最佳参数,就在测试数据上最后测试一次。
为什么需要验证集
原因在于开发模型时总是需要调节模型配置,比如选择层数或每层大小[这叫作模型的超参数(hyperparameter),以便与模型参数(即权重)区分开]。这个调节过程需要使用模型在验证数据上的性能作为反馈信号。这个调节过程本质上就是一种学习:在某个参数空间中寻找良好的模型配置。因此,如果基于模型在验证集上的性能来调节模型配置,会很快导致模型在验证集上过拟合,即使你并没有在验证集上直接训练模型也会如此。
造成这一现象的关键在于信息泄露(information leak)。每次基于模型在验证集上的性能来调节模型超参数,都会有一些关于验证数据的信息泄露到模型中。如果对每个参数只调节一次,那么泄露的信息很少,验证集仍然可以可靠地评估模型。但如果你多次重复这一过程(运行一次实验,在验证集上评估,然后据此修改模型),那么将会有越来越多的关于验证集的信息泄露到模型中。
最后,你得到的模型在验证集上的性能非常好(人为造成的),因为这正是你优化的目的。你关心的是模型在全新数据上的性能,而不是在验证数据上的性能,因此你需要使用一个完全不同的、前所未见的数据集来评估模型,它就是测试集。你的模型一定不能读取与测试集有关的任何信息,既使间接读取也不行。如果基于测试集性能来调节模型,那么对泛化能力的衡量是不准确的。
将数据划分为训练集、验证集和测试集可能看起来很简单,但如果可用数据很少,还有几种高级方法可以派上用场。
我们先来介绍三种经典的评估方法:简单的留出验证、K 折验证,以及带有打乱数据的重复 K 折验证。
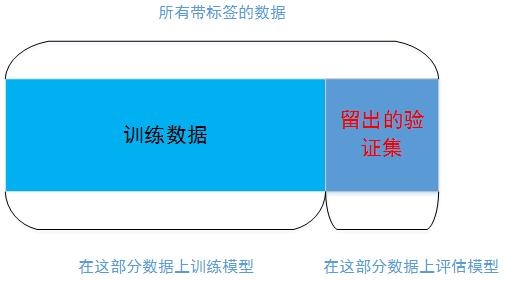
1. 简单的留出验证
留出一定比例的数据作为测试集。在剩余的数据上训练模型,然后在测试集上评估模型。
如前所述,为了防止信息泄露,你不能基于测试集来调节模型,所以还应该保留一个验证集。
留出验证的伪代码:
1、将原有数据集打乱顺序shuffle_data 2、将打乱的数据集的一部分(一般为10%-20%)定义为验证集valify_data 3、剩余的数据定义为训练数据train_data 4、根据需求建模 model 5、训练模型model.train(train_data) 6、在验证集上评估模型model.evaluate(valify_data) 7、调节模型 8、重复5、6、7直到模型在验证集上表现良好 9、在测试集上测试模型
这是最简单的评估方法,但有一个缺点:如果可用的数据很少,那么可能验证集和测试集包含的样本就太少,从而无法在统计学上代表数据。这个问题很容易发现:如果在划分数据前进行不同的随机打乱,最终得到的模型性能差别很大,那么就存在这个问题。
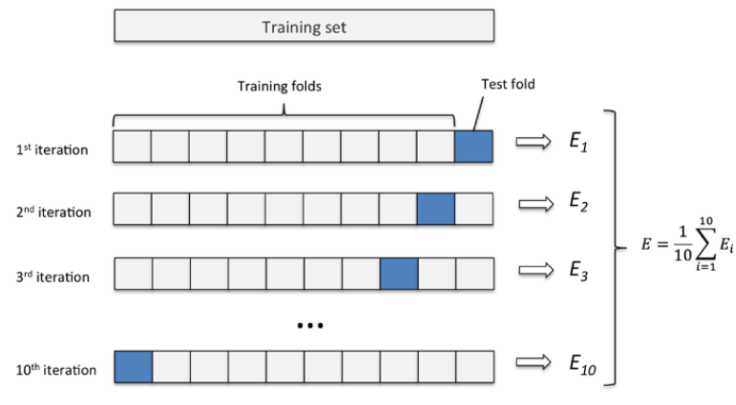
2. K 折验证
K 折验证(K-fold validation)将数据划分为大小相同的 K 个分区。对于每个分区 i ,在剩余的 K-1 个分区上训练模型,然后在分区 i 上评估模型。最终分数等于 K 个分数的平均值。对于不同的训练集 - 测试集划分,如果模型性能的变化很大,那么这种方法很有用。与留出验证一样,这种方法也需要独立的验证集进行模型校正。
伪代码
将原来的数据平均k份 根据需求建模 model for i in range(k) 将第 i 份数据作为验证集,其他k-1份数据作为训练集 在训练集上训练模型 在验证集上【】评估模型 在测试集上测试模型
数据量小的时候,k 可以设大一点,这样训练集占整体比例就比较大,不过同时训练的模型个数也增多。
数据量大的时候,k 可以设小一点。
3、带有打乱数据的重复 K 折验证
如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择带有打乱数据的重复 K 折验证(iterated K-fold validation with shuffling)。具体做法是多次使用 K 折验证,在每次将数据划分为 K 个分区之前都先将数据打乱。最终分数是多次 k 折交叉验证再求均值,例如:10 次 10 折交叉验证,以求更精确一点。注意,这种方法一共要训练和评估 P×K 个模型(P是重复次数),计算代价很大。
除此之外还有一种比较特殊的交叉验证方法,有人将其叫做Bootstrapping。通过又放回的抽样,抽取与train_data相同数量的数据作为新的训练集。即在含有 m 个样本的数据集中,每次随机挑选一个样本,再放回到数据集中,再随机挑选一个样本,这样有放回地进行抽样 m 次,组成了新的数据集作为训练集。
优点是训练集的样本总数和原数据集一样都是 m,并且仍有约 1/3 的数据不被训练而可以作为测试集。
缺点是这样产生的训练集的数据分布和原数据集的不一样了,会引入估计偏差。