前言:此篇博客在参考Regan_White的文章下完成:https://www.cnblogs.com/ReganWhite/p/10944525.html
一、操作数据库(以SQLite3为例)
SQLite3 可使用 sqlite3 模块与 Python 进行集成。它提供了一个与 PEP 249 描述的 DB-API 2.0 规范兼容的 SQL 接口。我们不需要单独安装该模块,因为 Python 2.5.x 以上版本默认自带了该模块。
为了使用 sqlite3 模块,首先必须创建一个表示数据库的连接对象,然后可以有选择地创建光标对象,这将帮助执行所有的 SQL 语句。
API | 描述 |
sqlite3.connect(database [,timeout ,other optional arguments]) | 该 API 打开一个到 SQLite 数据库文件 database 的链接。您可以使用 ":memory:" 来在 RAM 中打开一个到 database 的数据库连接,而不是在磁盘上打开。如果数据库成功打开,则返回一个连接对象。 当一个数据库被多个连接访问,且其中一个修改了数据库,此时 SQLite 数据库被锁定,直到事务提交。timeout 参数表示连接等待锁定的持续时间,直到发生异常断开连接。timeout 参数默认是 5.0(5 秒)。 如果给定的数据库名称 filename 不存在,则该调用将创建一个数据库。如果您不想在当前目录中创建数据库,那么您可以指定带有路径的文件名,这样您就能在任意地方创建数据库。 |
connection.cursor([cursorClass]) | 该例程创建一个 cursor,将在 Python 数据库编程中用到。该方法接受一个单一的可选的参数 cursorClass。如果提供了该参数,则它必须是一个扩展自 sqlite3.Cursor 的自定义的 cursor 类。 |
cursor.execute(sql [, optional parameters]) | 该例程执行一个 SQL 语句。该 SQL 语句可以被参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。 例如:cursor.execute("insert into people values (?, ?)", (who, age)) |
connection.execute(sql [, optional parameters]) | 该例程是上面执行的由光标(cursor)对象提供的方法的快捷方式,它通过调用光标(cursor)方法创建了一个中间的光标对象,然后通过给定的参数调用光标的 execute 方法。 |
cursor.executemany(sql, seq_of_parameters) | 该例程对 seq_of_parameters 中的所有参数或映射执行一个 SQL 命令。 |
connection.executemany(sql[, parameters]) | 该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executemany 方法。 |
cursor.executescript(sql_script) | 该例程一旦接收到脚本,会执行多个 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句应该用分号(;)分隔。 |
connection.executescript(sql_script) | 该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executescript 方法。 |
connection.total_changes() | 该例程返回自数据库连接打开以来被修改、插入或删除的数据库总行数。 |
connection.commit() | 该方法提交当前的事务。如果您未调用该方法,那么自您上一次调用 commit() 以来所做的任何动作对其他数据库连接来说是不可见的。 |
connection.rollback() | 该方法回滚自上一次调用 commit() 以来对数据库所做的更改。 |
connection.close() | 该方法关闭数据库连接。请注意,这不会自动调用 commit()。如果您之前未调用 commit() 方法,就直接关闭数据库连接,您所做的所有更改将全部丢失! |
cursor.fetchone() | 该方法获取查询结果集中的下一行,返回一个单一的序列,当没有更多可用的数据时,则返回 None。 |
cursor.fetchmany([size=cursor.arraysize]) | 该方法获取查询结果集中的下一行组,返回一个列表。当没有更多的可用的行时,则返回一个空的列表。该方法尝试获取由 size 参数指定的尽可能多的行。 |
cursor.fetchall() | 该例程获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。 |
接下来演示一些关于数据库的基础操作
1.连接数据库
下面操作是连接到一个现有的数据库,如果数据库不存在,则它会被创建,最后将返回一个数据库对象。
import sqlite3
conn=sqlite3.connect('test.db')
print('Opened database successfully ')
如果数据库成功创建,那么会显示此语句:

2.创建表
下面操作是在先前创建的数据库中创建一个表。
import sqlite3
conn = sqlite3.connect('test.db')
print("Opened database successfully")
c = conn.cursor()
c.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
print("Table created successfully")
conn.commit()
conn.close()
3.INSERT操作
下面操作是在先前创建的表中创建记录。
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print("Opened database successfully")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 )");
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )");
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )");
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )");
conn.commit()
print("Records created successfully")
conn.close()
4.SELECT操作
下面操作是获取先前创建表的数据并显示。
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print("Opened database successfully")
cursor = c.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print("ID = ", row[0])
print("NAME = ", row[1])
print("ADDRESS = ", row[2])
print("SALARY = ", row[3], "
")
print("Operation done successfully")
conn.close()
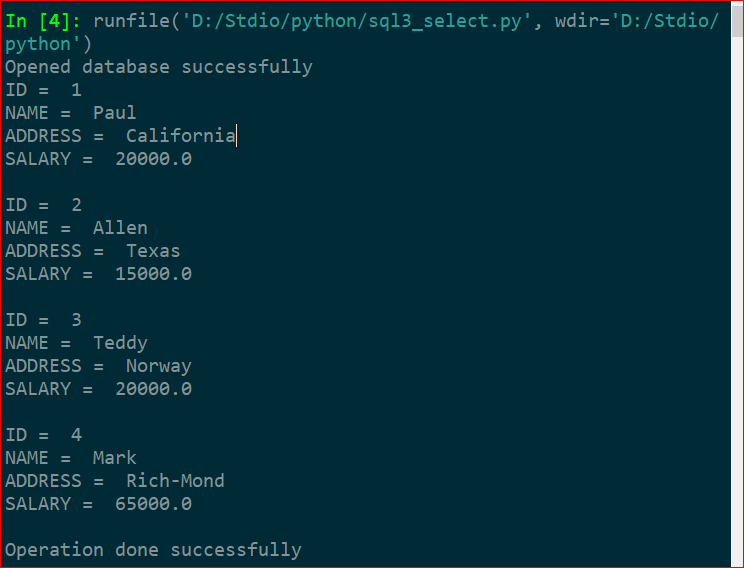
5.UPDATE操作
下面操作是使用UPDATE语句更新任何记录,然后从表中获取并显示更新的记录。
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print("Opened database successfully")
c.execute("UPDATE COMPANY set SALARY = 25000.00 where ID=1")
conn.commit()
print("Total number of rows updated :", conn.total_changes)
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print("ID = ", row[0])
print("NAME = ", row[1])
print("ADDRESS = ", row[2])
print("SALARY = ", row[3], "
")
print("Operation done successfully")
conn.close()
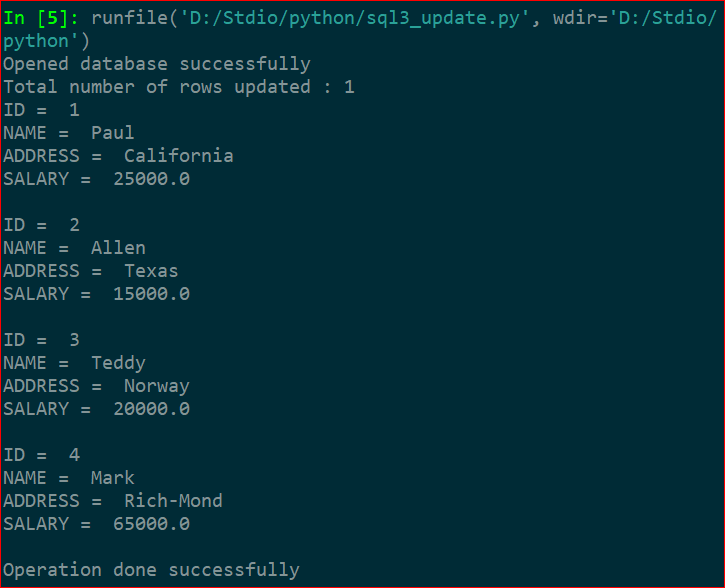
6. DELETE操作
下面操作是使用DELETE语句删除任何记录,然后从表中获取并显示剩余的记录。
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print("Opened database successfully")
c.execute("DELETE from COMPANY where ID=2;")
conn.commit()
print("Total number of rows deleted :", conn.total_changes)
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print("ID = ", row[0])
print("NAME = ", row[1])
print("ADDRESS = ", row[2])
print("SALARY = ", row[3], "
")
print("Operation done successfully")
conn.close()
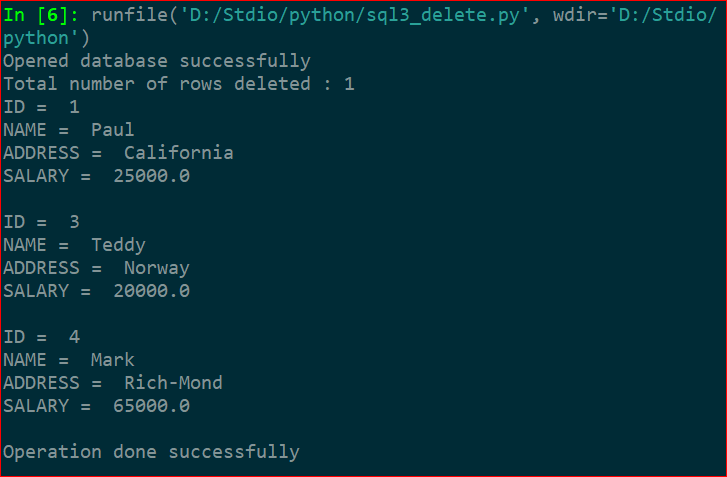
二、实例操作(2015大学排名)
根据上周作业,制作了2015年大学排名的csv文件,下面的操作都将基于该csv文件进行。
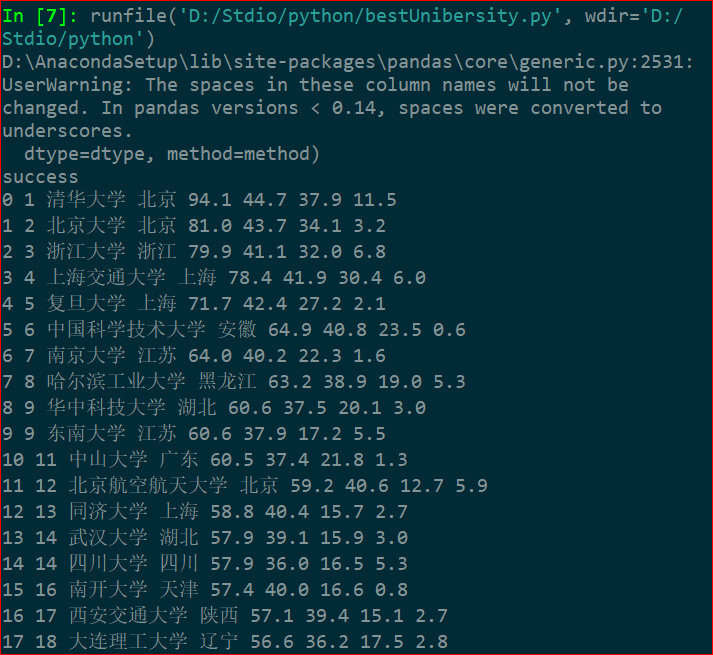
• 将csv文件写入数据库
import pandas
import sqlite3
conn= sqlite3.connect("2015大学排名(12).db")
k = pandas.read_csv('2015广东大学排名爬虫.csv',encoding='gbk')
k.to_sql('Guangdong', conn, if_exists='append', index=False)
print('success')
conn = sqlite3.connect('2015大学排名(12).db')
cur = conn.cursor()
cur.execute('SELECT * FROM Guangdong')
li = cur.fetchall()
i=0
for line in li:
i+=1
for item in line:
print(item, end=' ')
print()
if i==10:
break
conn.close()
查询本校排名及得分
代码如下:
import sqlite3
conn= sqlite3.connect("2015大学排名(07).db")
cur = conn.cursor()
cur.execute('SELECT * FROM University')
li = cur.fetchall() #返回所有查询结果
for line in li:
if "广东技术师范大学" in line:
print(line)
break
else:
print("查无该校数据")
conn.close()
结果如下:
