使用Flask-SQLAlchemy管理数据库
扩展Flask-SQLAlchemy集成了SQLAlchemy,它简化了连接数据库服务器、管理数据库操作会话等各种工作,让Flask中的数据处理体验变得更轻松。首先使用pipenv安装Flask-SQLAlchemy以及其依赖(主要是SQLAlchemy):
pipenv install flask-sqlalchemy
下面在示例程序中实例化Flask-SQL-Alchemy提供的SQLAlchemy类,传入程序实例app,以完成扩展的初始化:
from flask importFlask from flask_sqlalchemy importSQLAlchemy app = Flask(__name__) db = SQLAlchemy(app)
为了便于使用,我们把实例化的扩展类对象命名为db。这个db对象代表我们的数据库,它可以使用Flask-SQLAlchemy提供的所有功能。
虽然我们要使用的大部分类和函数都有SQLAlchemy提供,但在Flask-SQLAlchemy中,大多数情况下,我们不需要手动从SQLAlchemy导入类或函数。在sqlalchemy和sqlalchemy.orm模块中实现的类和函数,以及其他几个常用的模块和对象都可以作为db对象的属性调用。当我们创建这样的调用时,Flask-SQLAlchemy会自动把这些调用转发到对应的类、函数或模块。
sqlite3数据库安装及客户端软件
sqlite下载地址:https://www.sqlite.org/download.html
下载sqlite-tools-win32-*.zip 和 sqlite-dll-win64-*.zip 压缩文件
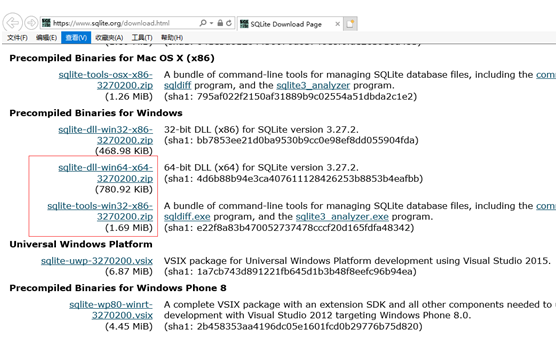
解压后,创建文件夹 C:sqlite3,在此文件夹下解压上面两个压缩文件,将得到 sqlite3.def、sqlite3.dll 和 sqlite3.exe 文件。
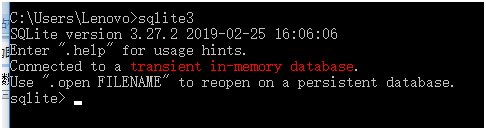
添加 C:sqlite3到PATH环境变量,在命令提示符下,使用sqlite3命令,将显示如下
客户端软件官网:
https://www.softpedia.com/get/Internet/Servers/Database-Utils/SQLiteSpy.shtml
下载SQLiteSpy:
下载后:

打开sqlite的db文件:
连接数据库服务器
DBMS通常会提供数据库服务器运行在操作系统中。要连接数据库服务器,首先要为我们的程序指定数据库URL(Uniform Resource Identifier,统一资源标识符)。数据库URI是一串包含各种属性的字符串,其中包含了各种用于连接数据库的信息。
URI代表统一资源标识符,是用来标识资源的一组字符串。URL是它的子集。
下面是一些常用的DBMS以及其数据库URI格式实例。

在Flask-SQLAlchemy中,数据库的URI通过配置变量SQLALCHEMY_DATABASE_URI设置,默认为SQLite内存型数据库(sqlite: ///: memory: )。SQLite是基于文件的DBMS,不需要设置数据库服务器,只需要指定数据库文件的绝对路径。我们使用app.root_path来定位数据库文件的路径,并将数据库文件命名为data.db,如下所示
app.py:配置数据库URI
importos app.config['SQLALCHEMY_DATABASE_URI'] = os.getenv('DATABASE_URL', 'sqlite:///' + os.path.join(app.root_path, 'data.db'))
在生产环境下更换到其他类型的DBMS时,数据库URL会包含敏感信息,所以这里优先从环境变量DATABASE_URL获取(注意这里为了便于理解使用的是URL,不是URI)
SQLite数据库文件名不限定后缀,常用的命名方式有foo.sqlite, foo.db,或是注明SQLite版本的foo.sqlite3。
设置好数据库URI后,在python shell中导入并查看db对象会获得下面的输出:
>>> from app importdb C:UsersLenovo.virtualenvsLenovo-ezd1lI9Ylibsite-packagesflask_sqlalchemy__init__.py:774: UserWarning: Neither SQLALCHEMY_DATABASE_URI nor SQLALCHEMY_BINDS is set. Defaulting SQLALCHEMY_DATABASE_URI to "sqlite:///:memory:". 'Neither SQLALCHEMY_DATABASE_URI nor SQLALCHEMY_BINDS is set. ' C:UsersLenovo.virtualenvsLenovo-ezd1lI9Ylibsite-packagesflask_sqlalchemy__init__.py:794: FSADeprecationWarning: SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and will be disabled by default in the future. Set it to True orFalse to suppress this warning. 'SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and ' >>>db <SQLAlchemy engine=sqlite:///D:flaskFLASK_PRACTICEDataBasedata.db>

安装并初始化Flask-SQLAlchemy后,启动程序时会看到命令行下有警告,这是因为Flask-SQLAchemy建议你设置SQLALCHEMY_TRACK_MODIFICATIONS配置变量,这个配置变量决定是否追踪对象的修改,这用于Flask-SQLALchemy的事件通知系统。这个配置的默认值为None,如果没有特殊需要,可以设为False来关闭警告:
app.config['SQLALCHEMY_TRACE_MODIFICATIONS'] = False
再次导入db:
>>> from app importdb >>>db <SQLAlchemy engine=sqlite:///D:flaskFLASK_PRACTICEDataBasedata.db> >>>
定义数据库模型
用来映射到数据库表的python类通常被称为数据库模型(model),一个数据库模型类对应数据库中的一个表。定义模型即使用python类定义表模式,并声明映射关系。所有的模型都需要继承Flask-SQLAlchemy提供的db.Model基类。后续的例子是一个笔记程序,笔记保存到数据库中,你可以通过程序查询、添加、更新和删除笔记。
定义一个Note模型类,用来存储笔记。
app.py: 定义Note模型
classNote(db.Model): id = db.Column(db.Integer, primary_key=True) body = db.Column(db.Text)
在这个模型类中,表的字段(列)由db.Column类的实例表示,字段的类型通过Column类构造方法的第一个参数传入。在这个模型中,我们创建了一个类型为db.Integer的id字段和类型为db.Text的body列,分别存储整型和文本。常用的SQLAlchemy字段类型如下表:
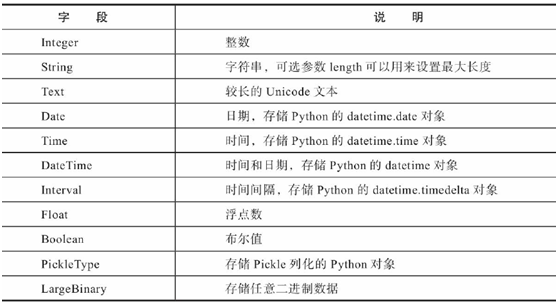
字段类型一般直接声明即可,如果需要传入参数,也可以添加括号。对于类似String的字符串列,有些使句酷会要求限定长度,因此最好为其制定长度。虽然使用Text类型可以存储相对灵活的变长文本,但从性能上考虑,我们仅在必须的情况下使用Text类型,比如用户发表的文章和评论等不限长度的内容。
一般情况下,字段的长度是由程序设计者自定的。尽管如此,也有一些既定的约束标准,比如姓名(英文)的长度一般不超过70个字符,中文名一般不超过20个字符,电子邮件地址的长度不超过254个字符,虽然个主流浏览器支持长达2048个字符的URL,但在网站中用户资料设置的限度一般为255。对于超过一定长度的Email和URL,比如20个字符,会在显示时添加省略号的形式。显示的用户名(username)允许重复,通常要短一些,以不超过36个字符为佳。在程序中可以根据需要来设定。
当在数据库模型类中限制了字段的长度后,在接收对应数据的表单类字段里,也需要使用Length验证器来验证用户的输入数据。
默认情况下,Flask-SQLAlchemy会根据模型类的名称生成一个表名称,生成规则如下:
Message -> message # 单个单词转换为小写
FooBar -> foo_bar # 多个单词转换为小写并使用下划线分隔
Note类对应的表名即为note。如果想自己指定表名称,可以通过定义__tablename__属性来实现。字段名默认为类属性名,也可以通过字段类构造方法的第一个参数指定(如Column('data', String(50))),或使用关键字name。根据我们定义的Note模型类,最终将生成一个Note表,表中包含id和body字段。
除了name参数,实例化字段类时常用的字段参数如下表:

不需要在所有列都建立索引。一般来说,取值可能性多(比如姓名)的列,以及经常被用来作为排序的参数(如时间戳)更适合建立索引。
在实例化字段类时,通过把参数primary_key设为True可以将其定义为主键。在我们定义的Nore类中,id字段即表的主键(primary key)。主键是每一条记录(行)独一无二的标识,也是模型类中必须定义的字段,一般命名为id或pk。
创建数据库和表
如果把数据库(文件)看作一个仓库,为了方便取用,我们需要把货物按照类型分别放置在不同的货架上,这些货架就是数据库中的表。创建模型类后,我们需要手动创建数据库和对应的表,就是建库和建表。这通过对我们的db对象调用create_all()方法实现:
(Lenovo-ezd1lI9Y) D:flaskFLASK_PRACTICEDataBase>flask shell App: app [production] Instance: D:flaskFLASK_PRACTICEDataBaseinstance >>> from app importdb >>> from app importNote >>> db.create_all()
如果将模型类定义在单独的模块中,那么必须再调用db.create_all()方法前导入相应模块,以便让SQLAlchemy获取模型类总定义的表信息,进而正确生成数据表。
通过下面的方式可以查看模型对应的SQL模式(建表语句):
>>> from app importdb >>> from app importNote >>>db.create_all() >>> print CreateTable(Note.__table__) CREATE TABLE note ( id INTEGER NOT NULL, body TEXT, PRIMARY KEY (id) )
数据库和表一旦创建后,之后对模型的改动不会自动作用的实际的表中。比如在模型类中添加或删除字段,修改字段的名称和类型,这时再次调用create_all()也不会更新表结构。如果要使改动生效,最简单的方式是调用db.drop_all()方法删除数据库和表,然后再调用db.create_all()方法创建。
我们也可以自己实现一个自顶一个flask命令完成这个工作,例如:
app.py:用于创建数据库和表的flask命令
importclick @app.cli.command() definitdb(): db.create_all() click.echo('Initialized database.')
在命令行输入flask initdb即可创建数据库和表:
(Lenovo-ezd1lI9Y) D:flaskFLASK_PRACTICEDataBase>flask initdb
Initialized database.
在开发程序或是部署后,我们经常需要在python shell中手动操作数据库(生产环境需注意备份),对于一次性操作,直接处理即可。对于需要重用的操作,我们可以编成flask命令、函数或是模型类的类方法。