摘要:Elasticsearch笔记七之setting,mapping,分片查询方式setting通过setting可以更改es配置可以用来修改副本数和分片数。prett2:修改不存在索引shb03时可以指定副本和分片,如果shb03已经存在则只能修改副本curl-XPUThttp://192.168.79.131:9200/shb03-d'{"settings":{"number_of_shards":4,"number_of_replicas":2}}'shb03已经存在不能修改分片curl-XPUThttp://192.168.79.131:9200/shb03/_settings-d'{"index":{"number_of_replicas":2}}'mapping我们在es中添加索引数据时不需要指定数据类型,es中有自动影射机制,字符串映射为string,数字映射为long。
setting
通过setting可以更改es配置可以用来修改副本数和分片数。
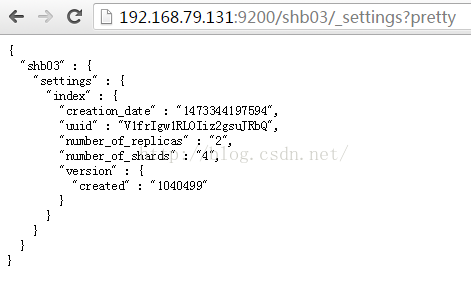
1:查看,通过curl或浏览器可以看到副本分片信息
curl -XGEThttp://192.168.79.131:9200/shb01/_settings?pretty
http://192.168.79.131:9200/shb01/_settings?prett

2:修改
不存在索引shb03时可以指定副本和分片,如果shb03已经存在则只能修改副本
curl -XPUT http://192.168.79.131:9200/shb03-d'{"settings":{"number_of_shards":4,"number_of_replicas":2}}'
shb03已经存在不能修改分片
curl -XPUThttp://192.168.79.131:9200/shb03/_settings -d '{"index":{"number_of_replicas":2}}'
mapping
我们在es中添加索引数据时不需要指定数据类型,es中有自动影射机制,字符串映射为string,数字映射为long。通过mappings可以指定数据类型是否存储等属性。
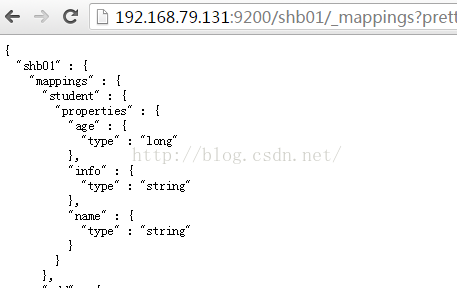
1:查看mapping信息
curl -XGEThttp://192.168.79.131:9200/shb01/_mappings?pretty
http://192.168.79.131:9200/shb01/_mappings?pretty
2:修改,通过mappings还可以指定分词器
操作不存在的索引
curl -XPUT http://192.168.79.131:9200/shb02-d'{"mappings":{"emp":{"properties":{"name":{"type":"string","indexAnalyzer":"ik","searchAnalyzer": "ik"}}}}}'
操作已存在的索引
curl -XPOSThttp://192.168.79.131:9200/crxy/shb02/_mapping-d'{"properties":{"name":{"type":"string","indexAnalyzer":"ik","searchAnalyzer": "ik"}}}'
java操作settings和mappings
- /**
- *settings,mappings
- *@throwsIOException
- *
- *org.elasticsearch.action.admin.indices.create.CreateIndexRequestBuilder;
- *org.elasticsearch.common.xcontent.XContentBuilder;
- *org.elasticsearch.common.xcontent.XContentFactory;
- */
- @Test
- publicvoidtestSettingsMappings()throwsIOException
- {
- //1:settings
- HashMap<String,Object>settings_map=newHashMap<String,Object>(2);
- settings_map.put("number_of_shards",3);
- settings_map.put("number_of_replicas",1);
- //2:mappings
- XContentBuilderbuilder=XContentFactory.jsonBuilder()
- .startObject()
- .field("dynamic","stu")
- .startObject("properties")
- .startObject("id")
- .field("type","integer")
- .field("store","yes")
- .endObject()
- .startObject("name")
- .field("type","string")
- .field("store","yes")
- .field("index","analyzed")
- .field("analyzer","id")
- .endObject()
- .endObject()
- .endObject();
- CreateIndexRequestBuilderprepareCreate=transportClient.admin().indices().prepareCreate("shb01");
- prepareCreate.setSettings(settings_map).addMapping("stu",builder).execute().actionGet();
- }
一般在工作中关闭自动映射防止垃圾数据进入索引库,提前定义好索引库的字段信息当有非法的数据进来时会报错。如果不知道字段信息则开启。
分片查询
Es会将数据均衡的存储在分片中,我们可以指定es去具体的分片或节点钟查询从而进一步的实现es极速查询。
1:randomizeacross shards
随机选择分片查询数据,es的默认方式
2:_local
优先在本地节点上的分片查询数据然后再去其他节点上的分片查询,本地节点没有IO问题但有可能造成负载不均问题。数据量是完整的。
3:_primary
只在主分片中查询不去副本查,一般数据完整。
4:_primary_first
优先在主分片中查,如果主分片挂了则去副本查,一般数据完整。
5:_only_node
只在指定id的节点中的分片中查询,数据可能不完整。
6:_prefer_node
优先在指定你给节点中查询,一般数据完整。
7:_shards
在指定分片中查询,数据可能不完整。
8:_only_nodes
可以自定义去指定的多个节点查询,es不提供此方式需要改源码。
注:es的数据存放在/usr/local/elasticsearch-1.4.4/data,如果要升级es可先备份此目录
- /**
- *指定分片查询
- */
- @Test
- publicvoidtestPreference()
- {
- SearchResponsesearchResponse=transportClient.prepareSearch(index)
- .setTypes("add")
- //.setPreference("_local")
- //.setPreference("_primary")
- //.setPreference("_primary_first")
- //.setPreference("_only_node:ZYYWXGZCSkSL7QD0bDVxYA")
- //.setPreference("_prefer_node:ZYYWXGZCSkSL7QD0bDVxYA")
- .setPreference("_shards:0,1,2")
- .setQuery(QueryBuilders.matchAllQuery()).setExplain(true).get();
- SearchHitshits=searchResponse.getHits();
- System.out.println(hits.getTotalHits());
- SearchHit[]hits2=hits.getHits();
- for(SearchHith:hits2)
- {
- System.out.println(h.getSourceAsString());
- }
- }