摘要:
从图中可以看出,Yarn的客户端需要获取hadoop配置信息并连接到Yarn的ResourceManager。如果资源足够,包含HDFS配置信息和Flink的jar包将上载到HDFS。将生成新的Flink配置信息,以便TaskManager可以连接到JobManager。同时,AM还提供Flink的WEB接口。用户可以并行执行多个Flink会话。
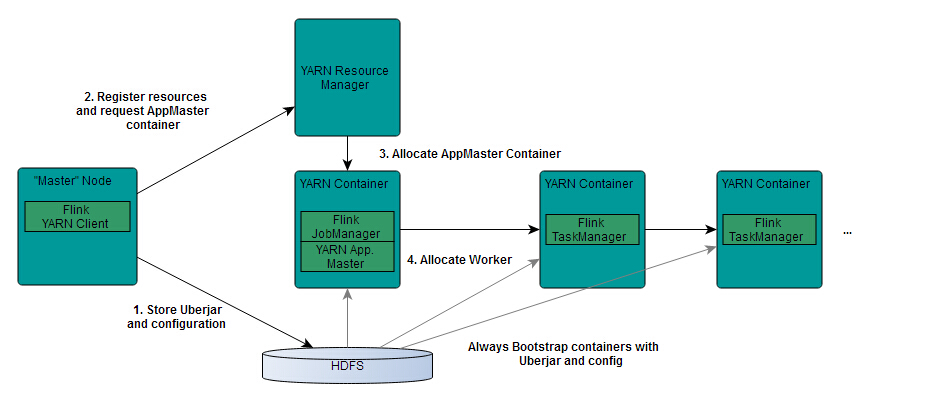
从图中可以看出,Yarn的客户端需要获取hadoop的配置信息,连接Yarn的ResourceManager。所以要有设置有 YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOOP_CONF_PATH,只要设置了其中一个环境变量,就会被读取。如果读取上述的变量失败了,那么将会选择hadoop_home的环境变量,都区成功将会尝试加载$HADOOP_HOME/etc/hadoop的配置文件。
1、当启动一个Flink Yarn会话时,客户端首先会检查本次请求的资源是否足够。资源足够将会上传包含HDFS配置信息和Flink的jar包到HDFS。
2、随后客户端会向Yarn发起请求,启动applicationMaster,随后NodeManager将会加载有配置信息和jar包,一旦完成,ApplicationMaster(AM)便启动。
3、当JobManager and AM 成功启动时,他们都属于同一个container,从而AM就能检索到JobManager的地址。此时会生成新的Flink配置信息以便TaskManagers能够连接到JobManager。同时,AM也提供Flink的WEB接口。用户可并行执行多个Flink会话。
4、随后,AM将会开始为分发从HDFS中下载的jar以及配置文件的container给TaskMangers.完成后Fink就完全启动并等待接收提交的job.
启动Flink cluster on YARN
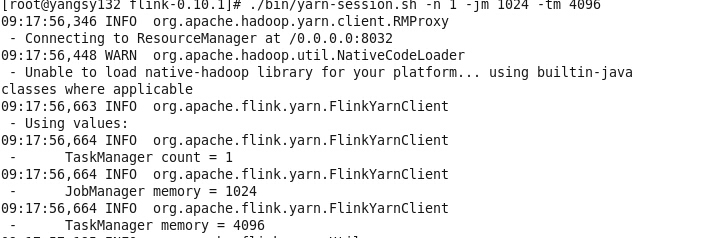
./bin/yarn-session.sh -n 1 -jm 1024 -tm 4096
可以看到启动了1个TaskManager 给jm与tm分配的资源数
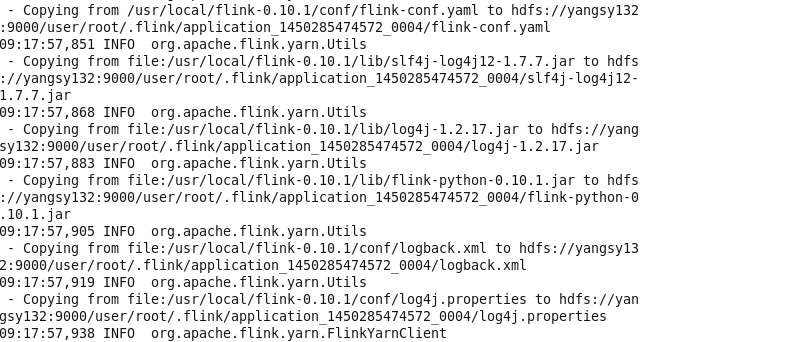
将Flink的配置与jar包上传至HDFS
提交于Application Master
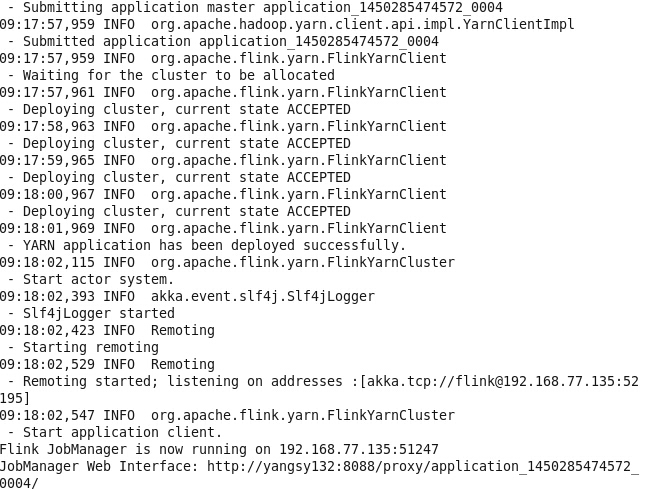
启动完毕后,就可提交任务。