摘要:
Kettle是一个开园ETL工具,做数据仓库用Spoon。并把这两个统计数字放在数据库表的一行的两列中,即输出的结果有一行,一行包括两列,每列是一个统计值。后续再开发接口给别的组调用。现在用kettle去做貌似就简单多了,现在感受到的是开发起来方便,干净利落。
Kettle是一个开园ETL工具,做数据仓库用Spoon。
工具:下载Spoon,解压即可用
1、认识常用组件:
表输入
插入\更新
数据同步
文本文件输出
更新
自动文档输出
表输出
列转行
增加常量
增加序列
排序记录
行转列
过滤记录
数据库连接
合并记录
排序合并
记录关联(笛卡尔输出)
记录集连接
分组
在内存中分组
2、第一个例子
生成 100 个随机数,随机数取值于[0,100)之间, 计算小于等于 50 的随机数个数和 大于50 的随机数个 数。 并把这两个统计数字放在数据库表的一行的两列中, 即输出的结果有一行,一行包括两列,每列是一个统 计值。
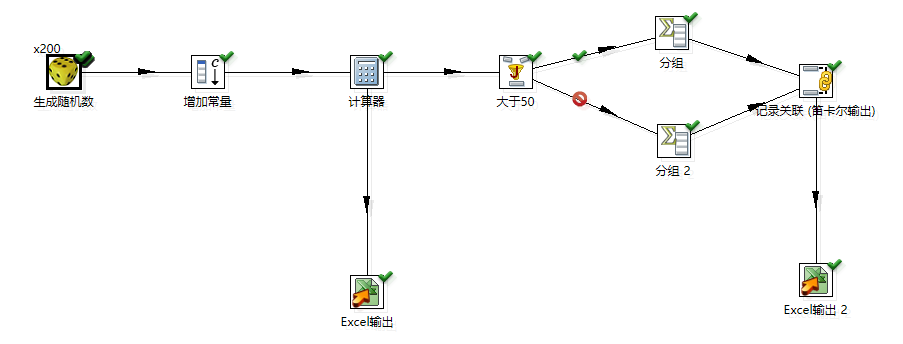
1.生成随机数,0-1区间内
2.定义常量,100
3.计算,随机数乘以100,使得生成的数据在0~100区间内
这里后面有分支,默认是数据分发,这里要保证数据全部都流到两条支路去要选择复制分发模式,在计算器这个步骤上面右键,选择数据发送,复制发送模式
4.条件判断有几种方法,这里用的是根据java代码过滤记录
5.分组计算总条数,4步中结果为真进分组1,否则分组2,分组里面计算总条数
6.关联记录
7.输出
3、数据仓库
目标:数据仓库就是把别的业务组的表查出来, 再转换, 保存到我们这边创建的新的业务表中。后续再开发接口(http、webservice、dubbo等)给别的组调用。
3.1用户评价表中有各种评价得分,这里对经纪人的各种得分求平均分保存到bidb_brance中
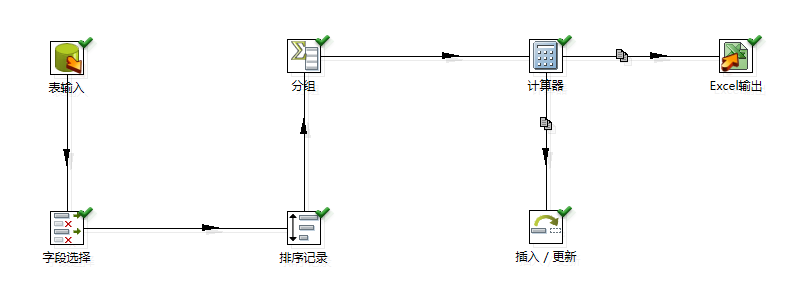
0.建立数据库连接
数据源1:mysql://172.16.2.187:33096/jjskfang
数据源2:mysql://172.16.2.245:33096/bidb_branch
1.表输入:
使用数据源1,
初始数据为:
SELECT ID, WORKER_ID, WORKER_NAME, USER_ID, USER_NAME, GRADE, SCORE, PROFESS_SCORE,
KNOW_SCORE, SERVICE_SCORE, TAGS, CONTENT, ORDER_ID, ORDER_TYPE, `STATUS`, MODIFY_TIME,
CREATE_TIME FROM jjskfang.CUSTOMER_COMMENT
WHERE `STATUS` = 1
2.字段选择:
选择必要的字段,这里也可以省略这一步
选择:WORKER_ID, WORKER_NAME,SCORE, PROFESS_SCORE, KNOW_SCORE,SERVICE_SCORE
3.排序:选择排序字段为WORKER_ID,分组前必须对分组字段进行排序,类似禹sql里面的group by
4.分组:根据WORKER_ID分组,同时使用聚合函数(这里就完全类似sql里面的分组和聚合函数了),如下图:
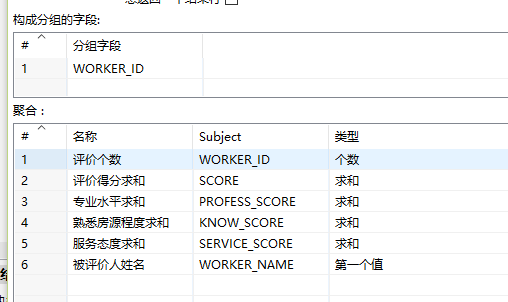
5.计算器:用计算器计算出各个指标的平均数,如图:

6.插入|更新:这一步将数据保存到目标数据库中,准备工作为先在数据源2中创建需要的表:
建表如图:

插入|更新如图:选择数据源2,表为刚刚创建的表
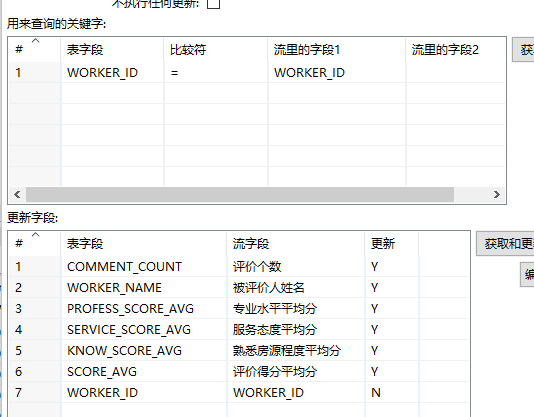
这一步根据workerId查询判断执行更新或者插入操作,到这里这个简单的转换工作就完成了,可以去数据库里面查询一下,看到数据都出来了是不是满满的成就感呢
感悟:做到这里让我想到一个问题,以前做车辆管理系统高危用户五级风险预警,当时是用java算出来的,真是让人头大。先去查询用户驾驶行为,再查询用户行为报警等各种数据,然后拼命的循坏各种判断,得到分析后的数据再保存到另外一个表中,来来回回写了一堆代码,最后发现执行的时候,定时器一启动服务启内存就完全不够用了,因为我开始是一次性把所有数据查出来再分析的。然后又去想怎么改程序,最终终于拼凑出来了。
现在用kettle去做貌似就简单多了,现在感受到的是开发起来方便,干净利落。不知道放到定时器运行的时候性能效率怎么样?后续持续研究。
4、java调用Kettle示例
从网上复制的代码, 后续自己写示例验证
public class KettleTest {
public static void main(String[] args) {
String filename = "/wang/work/study/Kettle/sample/excel_trans.ktr";
try {
KettleEnvironment.init();
EnvUtil.environmentInit();
TransMeta transMeta = new TransMeta(filename);
Trans trans = new Trans(transMeta);
trans.execute(null); // You can pass arguments instead of null.
trans.waitUntilFinished();
if ( trans.getErrors() > 0 ){
throw new RuntimeException( "There were errors during transformation execution." );
}
}
catch (KettleException e ) {
// TODO Put your exception-handling code here.
System.out.println(filename);
System.out.println(e);
}
}
}
5、java开发定时器执行ktr脚本
这个步骤省略。
总结:工具的使用并不难,关键在于理解业务,还有写sql的能力!
仅供参考,不足之处还请见谅,欢迎指正!转载请标明出处。如有疑问,欢迎评论或者联系我邮箱1034570286@qq.com