需求背景
在接收到 protobuf 数据之后,如何自动创建具体的 Protobuf Message 对象,再做反序列化。“自动”的意思主要有两个方面:(1)当程序中新增一个 protobuf Message 类型时,这部分代码不需要修改,不需要自己去注册消息类型,不需要重启进程,只需要提供protobuf文件;(2)当protobuf Message修改后,这部分代码不需要修改,不需要自己去注册消息类型,不需要重启进程只需要提供修改后protobuf文件。
技术介绍
Protobuf的入门可以参考Google Protocol Buffer 的在线帮助 网页 或者IBM developerwor上的文章《Google Protocol Buffer 的使用和原理》。
protobuf的动态解析在google protobuf buffer官网并没有什么介绍。通过google出的一些参考文档可以知道,其实,Google Protobuf 本身具有很强的反射(reflection)功能,可以根据 type name 创建具体类型的 Message 对象,我们直接利用即可,应该就可以满足上面的需求。
实现可以参考淘宝的文章《玩转Protocol Buffers 》,里面对protobuf的动态解析的原理做了详细的介绍,在此我介绍一下Protobuf class diagram。
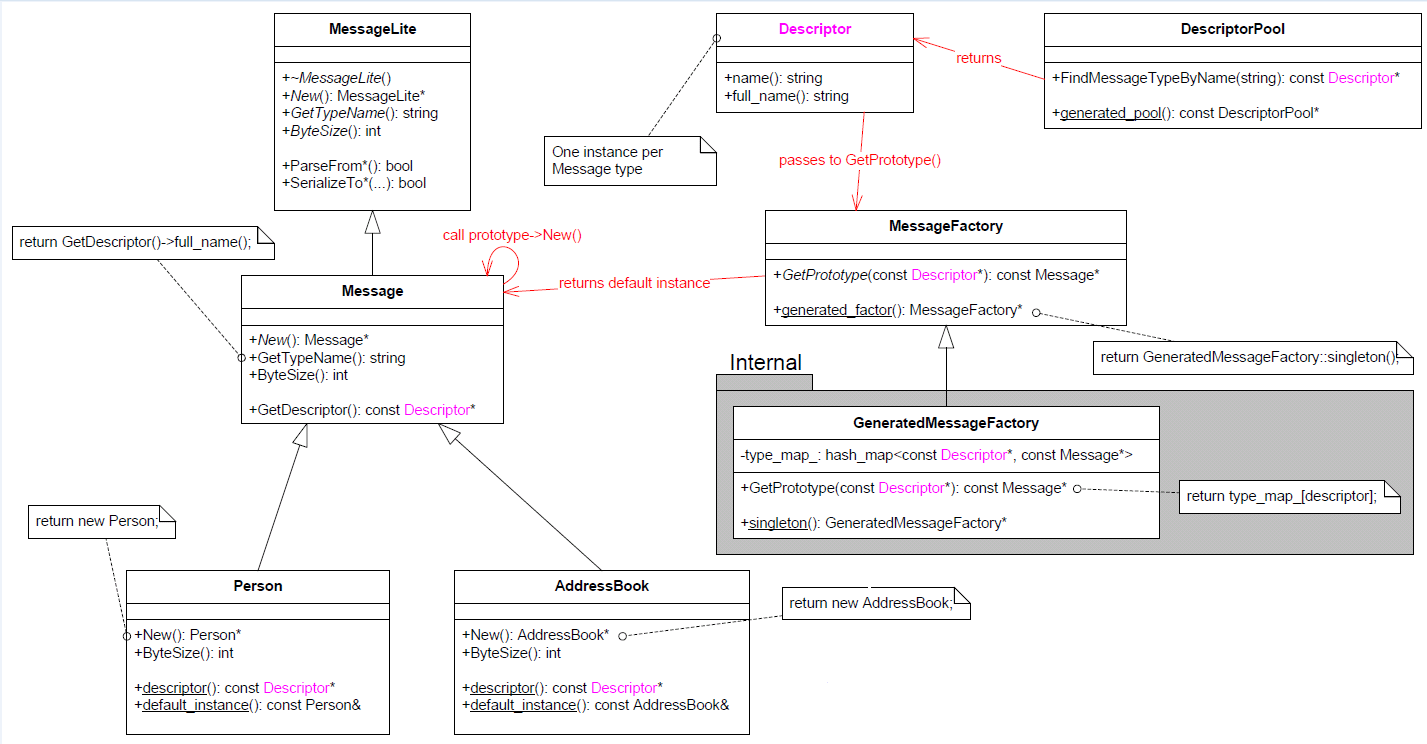
大家通常关心和使用的是图的左半部分:MessageLite、Message、Generated Message Types (Person, AddressBook) 等,而较少注意到图的右半部分:Descriptor, DescriptorPool, MessageFactory。
上图中,其关键作用的是 Descriptor class,每个具体 Message Type 对应一个 Descriptor 对象。尽管我们没有直接调用它的函数,但是Descriptor在“根据 type name 创建具体类型的 Message 对象”中扮演了重要的角色,起了桥梁作用。上图的红色箭头描述了根据 type name 创建具体 Message 对象的过程。
实现
先直接上代码,这个代码来自于《玩转Protocol Buffers 》:
#include <iostream> #include <google/protobuf/descriptor.h> #include <google/protobuf/descriptor.pb.h> #include <google/protobuf/dynamic_message.h> #include <google/protobuf/compiler/importer.h>
using namespace std; using namespace google::protobuf; using namespace google::protobuf::compiler;
int main(int argc,const char *argv[]) { DiskSourceTree sourceTree; //look up .proto file in current directory sourceTree.MapPath("","./"); Importer importer(&sourceTree, NULL); //runtime compile foo.proto importer.Import("foo.proto");
const Descriptor *descriptor = importer.pool()-> FindMessageTypeByName("Pair"); cout << descriptor->DebugString();
// build a dynamic message by "Pair" proto DynamicMessageFactory factory; const Message *message = factory.GetPrototype(descriptor); // create a real instance of "Pair" Message *pair = message->New();
// write the "Pair" instance by reflection const Reflection *reflection = pair->GetReflection();
const FieldDescriptor *field = NULL; field = descriptor->FindFieldByName("key"); reflection->SetString(pair, field,"my key"); field = descriptor->FindFieldByName("value"); reflection->SetUInt32(pair, field, 1111);
cout << pair->DebugString(); delete pair; return0; } |
那我们就来看看上面的代码
1)把本地地址映射为虚拟地址
DiskSourceTree sourceTree;
//look up .proto file in current directory
sourceTree.MapPath("","./");
2)构造DescriptorPool
Importer importer(&sourceTree, NULL);
//runtime compile foo.proto
importer.Import("foo.proto");
3)获取Descriptor
const Descriptor *descriptor = importer.pool()->FindMessageTypeByName("Pair");
4)通过Descriptor获取Message
const Message *message = factory.GetPrototype(descriptor);
5)根据类型信息使用DynamicMessage new出这个类型的一个空对象
Message *pair = message->New();
6)通过Message的reflection操作message的各个字段
const Reflection *reflection = pair->GetReflection();
const FieldDescriptor *field = NULL;
field = descriptor->FindFieldByName("key");
reflection->SetString(pair, field,"my key");
field = descriptor->FindFieldByName("value");
reflection->SetUInt32(pair, field, 1111);
直接copy上面代码看起来我们上面的需求就满足了,只是唯一的缺点就是每次来个包加载一次配置文件,当时觉得性能应该和读取磁盘的性能差不多,但是经过测试性能极差,一个进程每秒尽可以处理1000多个包,经过分析性能瓶颈不在磁盘,而在频繁调用malloc和free上。
看来我们得重新考虑实现,初步的实现想法:只有protobuf描述文件更新时再重新加载,没有更新来包只需要使用加载好的解析就可以。这个方案看起来挺好的,性能应该不错,经过测试,性能确实可以,每秒可以处理3万左右的包,但是实现中遇到了困难。要更新原来的Message,必须更新Importer和Factory,那么要更新这些东西,就涉及到了资源的释放。经过研究这些资源的释放顺序特别重要,下面就介绍一下protobuf相关资源释放策略。
动态的Message是我们用DynamicMessageFactory构造出来的,因此销毁Message必须用同一个DynamicMessageFactory。 动态更新.proto文件时,我们销毁老的并使用新的DynamicMessageFactory,在销毁DynamicMessageFactory之前,必须先删除所有经过它构造的Message。
原理:DynamicMessageFactory里面包含DynamicMessage的共享信息,析构DynamicMessage时需要用到。生存期必须保持Descriptor>DynamicMessageFactory>DynamicMessage。
释放顺序必须是:释放所有DynamicMessage,释放DynamicMessageFactory,释放Importer。
总结
资源释放前,必须要了解资源的构造原理,通过构造原理反推释放顺序,这样就少走弯路、甚至不走。
参考文献
Google Protocol Buffer 的在线帮助 网页
一种自动反射消息类型的 Google Protobuf 网络传输方案
《Google Protocol Buffer 的使用和原理》