摘要:
之前的任务之一是在服务器上复制文本字符串。这是一个简单的操作,但需要重复大约50次。每次大约花了三分钟。之后,花了两个多小时才进入。登录部分是因为服务器使用Windows安全验证,如图所示:它需要模拟登录以获取网页数据。登陆后,可以直接获取网页内容,然后截取数据。最后,在最外层添加一个循环,并执行一次要获取的服务器地址,以便可以一次检索所有服务器上的数据。
之前有一个工作是到服务器上去复制一串文字下来,很简单的操作,但是需要重复50次左右,每次花费大概三分钟,一遍下来两个多小时就进去了。因此就做了这个工具自动抓取数据。
工具主要做三件事情:登陆,下载,截取。
登陆部分由于服务器使用的是windows安全校验,如图:
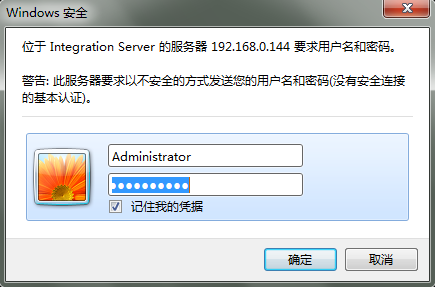
需要模拟登陆才能获取到网页数据。
首先用fiddler抓取http传输的数据包,在报头部分发现一串字符串:
经过base64解密之后得到:Administrator:manage。
这个便是用户名:密码经过加密之后的字符串。而Authorization:Basic则是一种验证方式,一般通过setRequestProperty来设置。
搞定登陆之后就可以直接获取到网页内容再进行数据截取了。最后再在最外层加一个循环,将需要抓取的服务器地址一次执行一次,就能一次获取所有服务器上的数据了。
最后贴代码:
import java.io.*; import java.net.*; public class getPackageFromWeb { public static void main(String args[]) throws Exception { String[] servers ={"192.168.0.144:23342","192.168.0.144:23343"}; StringBuilder result=new StringBuilder(); for(int i=0;i<servers.length;i++){ String packagelist = getWebPage("http://"+servers[i]+"/WmRoot/package-list.dsp"); while(packagelist.indexOf("package-info.dsp?package=")!=-1){ packagelist=packagelist.substring(packagelist.indexOf("package-info.dsp?package=")+25,packagelist.length()); String tempPackage=packagelist.substring(0, packagelist.indexOf(""")); result.append(tempPackage+","); } result.append(" "); } BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("c:\result.csv")); bufferedWriter.write(result.toString()); bufferedWriter.close(); } public static String getWebPage(String Addr) throws Exception { String data = ""; URL url = new URL(Addr); HttpURLConnection httpUrlCon = (HttpURLConnection) url.openConnection(); String author = "Basic QWRtaW5pc3RyYXRvcjptYW5hZ2U="; httpUrlCon.setRequestProperty("Authorization", author); httpUrlCon.connect(); InputStreamReader inRead = new InputStreamReader( httpUrlCon.getInputStream(),"UTF-8"); BufferedReader bufRead = new BufferedReader(inRead); StringBuffer strBuf = new StringBuffer(); String line = ""; while ((line = bufRead.readLine()) != null) { strBuf.append(line); } data=strBuf.toString(); return data; }
}