首先Hierarchical Softmax是word2vec的一种改进方式,因为传统的word2vec需要巨大的计算量,所以该方法主要有两个改进点:
1. 对于从输入层到隐藏层的映射,没有采取神经网络的线性变换加激活函数的方法,而是采用简单的对所有输入词向量求和并取平均的方法。
比如输入的是三个4维词向量:(1,2,3,4),(9,6,11,8),(5,10,7,12)(1,2,3,4),(9,6,11,8),(5,10,7,12),那么我们word2vec映射后的词向量就是(5,6,7,8)。这里是从多个词向量变成了一个词向量。
2.第二个改进就是从隐藏层到输出的softmax层这里的计算量个改进。为了避免要计算所有词的softmax概率,word2vec采样了霍夫曼树来代替从隐藏层到输出softmax层的映射
所以这里主要分为三个部分,霍夫曼树的介绍,基于Hierarchical Softmax的CBOW模型和基于Hierarchical Softmax的Skip-Gram模型。
一. 霍夫曼树
构造霍夫曼树步骤:
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
举例:假设有a,b,c,d,e,f六个数,并且值分别为9,12,6,3,5,15
构造的哈夫曼树如下图所示:

这里约定编码方式左子树的编码为1,右子树的编码为0,同时约定左子树的权重不小于右子树的权重。
二. 基于Hierarchical Softmax的CBOW模型
同时CBOW采用了Hierarchical Softmax,该算法结合了Huffman编码,每个词 w 都可以从树的根结点root沿着唯一一条路径被访问到,其路径也就形成了其编码code。假设 n(w, j)为这条路径上的第 j 个结点,且 L(w)为这条路径的长度, j 从 1 开始编码,即 n(w, 1)=root,n(w, L(w)) = w。对于第 j 个结点,层次 Softmax 定义的Label 为 1 - code[j]。
取一个适当大小的窗口当做语境,输入层读入窗口内的词,将它们的向量(K维,初始随机)加和在一起,形成隐藏层K个节点。输出层是一个巨大的二叉树,叶节点代表语料里所有的词(语料含有V个独立的词,则二叉树有|V|个叶节点)。而这整颗二叉树构建的算法就是Huffman树。这样,对于叶节点的每一个词,就会有一个全局唯一的编码,形如"010011",不妨记左子树为1,右子树为0。接下来,隐层的每一个节点都会跟二叉树的内节点有连边,于是对于二叉树的每一个内节点都会有K条连边,每条边上也会有权值。
比如在给定上下文时,对于一个要预测的词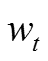
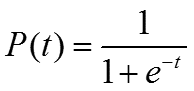
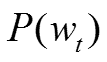
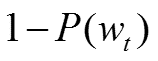
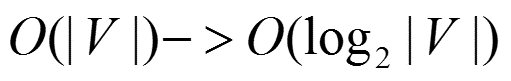
这里总结下基于Hierarchical Softmax的CBOW模型算法流程,梯度迭代使用了随机梯度上升法
步骤:
输入:基于CBOW的语料训练样本,词向量的维度大小M,CBOW的上下文大小2c,步长η
输出:霍夫曼树的内部节点模型参数θ,所有的词向量w
1. 基于语料训练样本建立霍夫曼树。
2. 随机初始化所有的模型参数θ,所有的词向量w
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w),w)做如下处理:

三. 基于Hierarchical Softmax的Skip-Gram模型
Skip-Gram模型和CBOW模型其实是反过来的
对于从输入层到隐藏层(投影层),这一步比CBOW简单,由于只有一个词,所以,即xwxw就是词ww对应的词向量。
第二步,通过梯度上升法来更新我们的θwj−1和xw,注意这里的xw周围有2c个词向量,此时如果我们期望P(xi|xw),i=1,2...2c最大。此时我们注意到由于上下文是相互的,在期望P(xi|xw),i=1,2...2c最大化的同时,反过来我们也期望P(xw|xi),i=1,2...2c最大。那么是使用P(xi|xw)好还是P(xw|xi)好呢,word2vec使用了后者,这样做的好处就是在一个迭代窗口内,我们不是只更新xwxw一个词,而是xi,i=1,2...2c共2c个词。这样整体的迭代会更加的均衡。因为这个原因,Skip-Gram模型并没有和CBOW模型一样对输入进行迭代更新,而是对2c个输出进行迭代更新。
这里总结下基于Hierarchical Softmax的Skip-Gram模型算法流程,梯度迭代使用了随机梯度上升法:
输入:基于Skip-Gram的语料训练样本,词向量的维度大小M,Skip-Gram的上下文大小2c,步长η
输出:霍夫曼树的内部节点模型参数θ,所有的词向量w
1. 基于语料训练样本建立霍夫曼树。
2. 随机初始化所有的模型参数θ,所有的词向量w,
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(w,context(w))做如下处理:

总结:以上是基于Hierarchical Softmax的word2vec模型。
主要参考内容链接如下:
https://www.cnblogs.com/pinard/p/7243513.html
https://blog.csdn.net/weixin_33842328/article/details/86246017