大纲:
- hadoop2 介绍
- HDFS概述
- HDFS读写流程
hadoop2介绍
框架的核心设计是HDFS(存储),mapReduce(分布式计算),YARN(资源管理),为海量的数据提供了存储和计算。
Hadoop 1.0(MapReduce,HDFS)
Hadoop2 主要改进
- YARN
- NameNode HA
- HDFS federation
- Hadoop RPC 序列化扩展性
HDFS概述
定义
- HDFS是一个分布式文件系统,具有高容错的特点。它可以部署在廉价的通用硬件上,提高高吞吐率的数据访问,适合那些需要处理海量数据集的应用程序。
主要特性
- 支持超大文件
- 检测和快速应对硬件故障
- 流式数据访问
- 简化一致性模型
不适合的场景
- 低延迟数据访问
- 大量的小文件
- 多用户写入文件,修改文件
HDFS 构成
- NameNode上保存着HDFS的名字空间。对于任何文件系统元数据产生修改的操作。
- DataNode将HDFS数据以文件的形式存储在本地的文件系统中,它并不知道有关HDFS文件的信息,它把每个HDFS数据块存储在本地文件系统的一个单独的文件中。
数据块
- HDFS也有块的概念,hadoop2中的HDFS块默认大小为128MB,以linux上普通文件安的形式保存在数据节点的文件系统中。数据块是HDFS的文件存储单元。
- 优点:
- HDFS可以保存比存储节点单一磁盘大的文件
- 简化了存储子系统,简化了存储管理,也消除了分布式管理文件元数据的复杂性
- 方便容错,有利于数据复制
HDFS读写流程
读过程
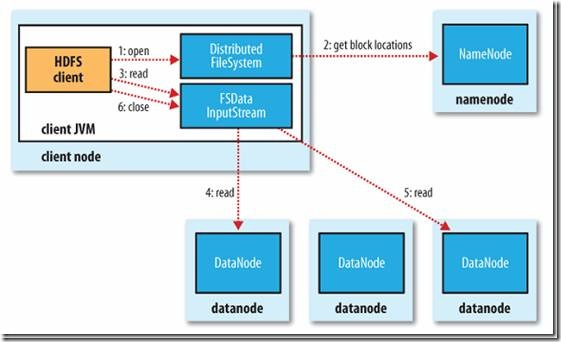
客户端(client)用FileSystem的open()函数打开文件
DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。
对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。
客户端调用stream的read()函数开始读取数据。
DFSInputStream连接保存此文件第一个数据块的最近的数据节点。
Data从数据节点读到客户端(client)
当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
失败的数据节点将被记录,以后不再连接。
写文件流程
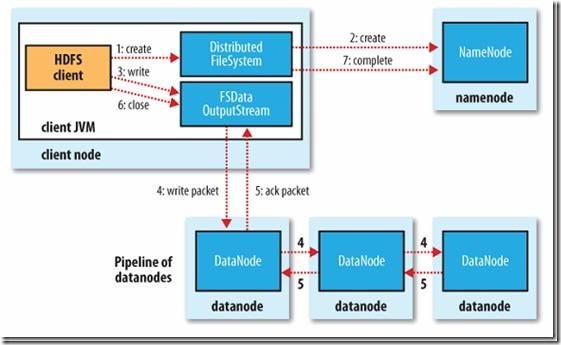
客户端调用create()来创建文件
DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
如果数据节点在写入的过程中失败:
关闭pipeline,将ack queue中的数据块放入data queue的开始。
当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
创建子路径流程
客户端 ——> NameNode -> datanode
删除文件
客户端 -> namenode -> datanode