一、pytest-html生成报告
pytest-html的github源码地址:https://github.com/pytest-dev/pytest-html
安装:pip install pytest-html
1、在cmd中执行命令生成测试报告:
# 使用pytest-xdist多进程运行生成html测试报告,并指定报告生成位置 pytest -s -n=3 get_multithread.py --html=./report/xdist3.html
2、在PyCharm中执行命令生成测试报告:
# 使用pytest-parallel多线程运行生成测试报告,且将css样式合并到html中 if __name__ == "__main__": pytest.main(['-s', '--tests-per-worker=3', '--html=xdist2.html', '--self-contained-html', __file__])
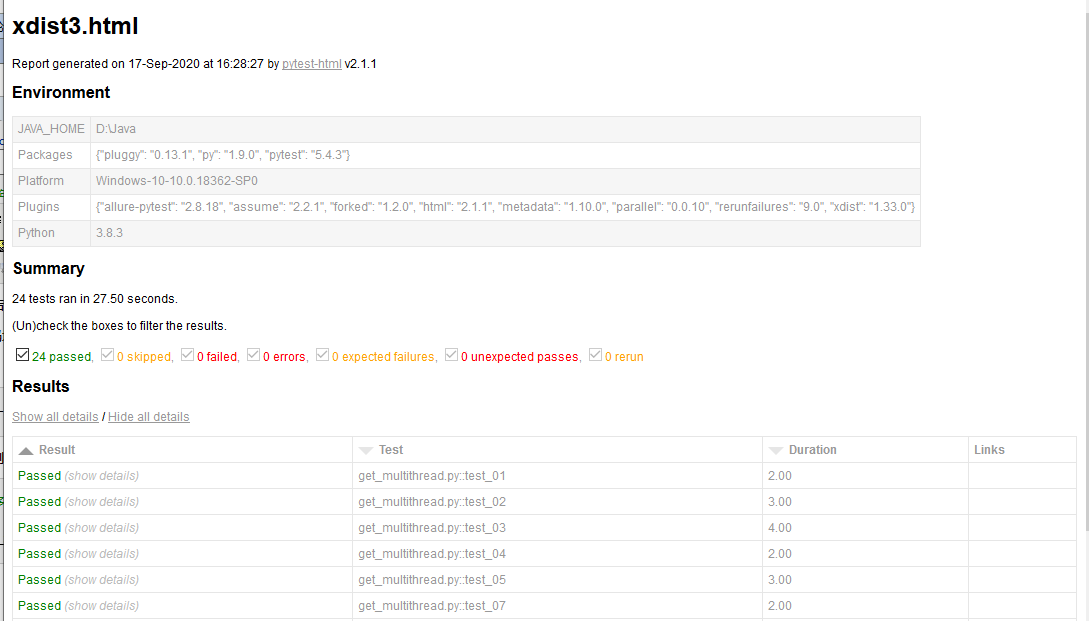
3、效果预览
二、allure-pytest生成报告
# 安装 pip install allure-pytest # 安装allure-command工具: 参考:https://www.cnblogs.com/yoyoketang/p/12004145.html
cmd命令行运行: (1)E:Temp>pytest -s -q test_register.py --alluredir report(即path_to_report_dir) (2)E:Temp>allure generate --clean report 或 E:Tempallure generate report/ -o report/html --clean 再通过PyCharm打开生成的html文件
(打开html报告后,可点击"EN"切换报告语言)
allure的常用功能特性:
1、@allure.feature():可以用来定制测试类标题,如:xxx模块
2、@allure.story():可以用来定制函数方法标题,如:注册成功,注册失败
3、@allure.step():用来描述测试步骤,如实例化对象
4、@allure.description():提供字符串内容描述,如用例描述...
5、@allure.title():用于描述用例的标题
6、@allure.link()、@allure.issure()、@allure.testcase():提供特定的链接url
7、allure.attach((body, name, attachment_type, extension):用于向报告中新增附加的信息
body- 要写入文件的原始内容。name- 包含文件名的字符串attachment_type- 其中一个allure.attachment_type值extension- 提供的将用作创建文件的扩展名
8、@allure.severity('critical'):用于描述用例的级别
blocker级别:中断缺陷(客户端程序无响应,无法执行下一步操作)
critical级别:临界缺陷( 功能点缺失)
normal级别:普通缺陷(数值计算错误)
minor级别:次要缺陷(界面错误与UI需求不符)
trivial级别:轻微缺陷(必输项无提示,或者提示不规范)
三、关于allure-pytest生成的报告直接用浏览器打开时一直显示loading...
原因:存在跨域的问题
解决办法:下载node,搭建anywhere静态服务器
(AnyWhere是一款随启随用的静态文件服务器,可以随时随地将你的当前目录变成一个静态文件服务器的根目录。)
参考:https://www.jianshu.com/p/3f0b7ea9df53
参考:http://www.manongjc.com/detail/12-bxyybsulsoplcyg.html
参考:https://blog.csdn.net/liuchunming033/article/details/79624474