继续上一篇 SQL Server ->> AlwaysOn高可用副本同步失败 讲到说现在公司的Azure云生产环境的一台alwayson的高可用副本同步中断,中断后自然就是恢复,恢复肯定从中断的日志链条恢复。
首先两台机器都是Azure云,IP网段是一个网段,连通性是没有问题。要恢复同步上篇随笔也讲了,就是重启SQL Server服务,让SQL Server自己自然redo日志就行了。
负责服务器运维的SA同事是10月26号晚上10点左右重启了SQL Server服务的,上篇博文也说了,高可用副本中断同步其实是10月23号凌晨2点15分的时候中断,也就是起码堆积了3天多快4天的日志等待redo。所以整个恢复过程会非常慢。
接下来就是问题了,由于日志非常多,对整台副本服务器的性能影响非常大,影响最大的我认为当然是磁盘IO。
这里开始有争议点,SA同事微信群里发出下面两张截图说是日志接近760G,恢复进程比较慢。我觉得这点也不太准确,首先我知道中断几天导致日志堆积等待redo没错,但是不能以日志文件大小来判断。日志文件大小是占用磁盘空间的表现,不代表等待恢复的队列有760G大小。要判断有多少日志待恢复,还是要通过 SQL Server ->> AlwaysOn 监控脚本 这篇里面的第二条监控脚本比较准确说明问题。这是争议点之一。

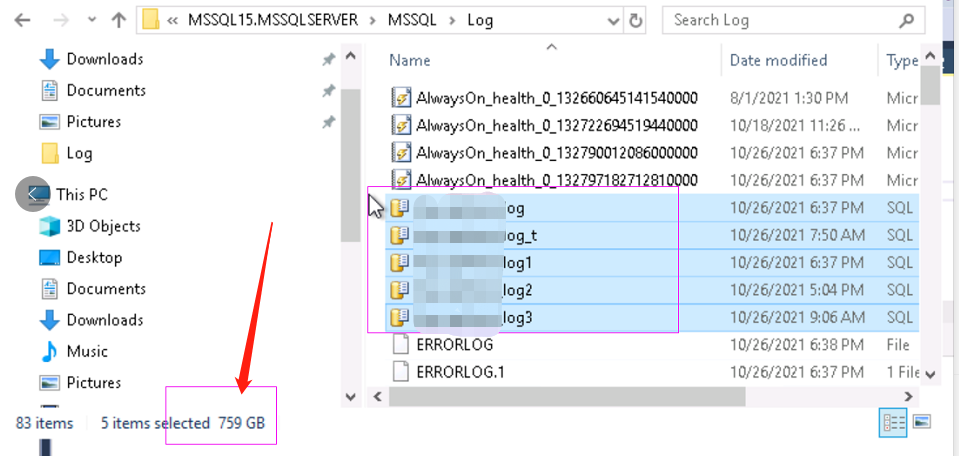
下面这张图是26号晚上11点的时候看到,日志文件的读操作非常恐怖,几乎慢符合的读日志记录去redo
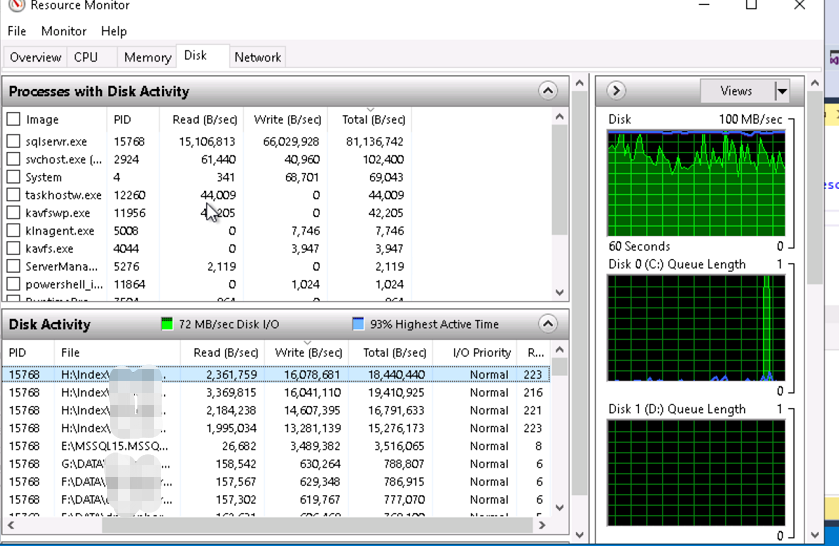
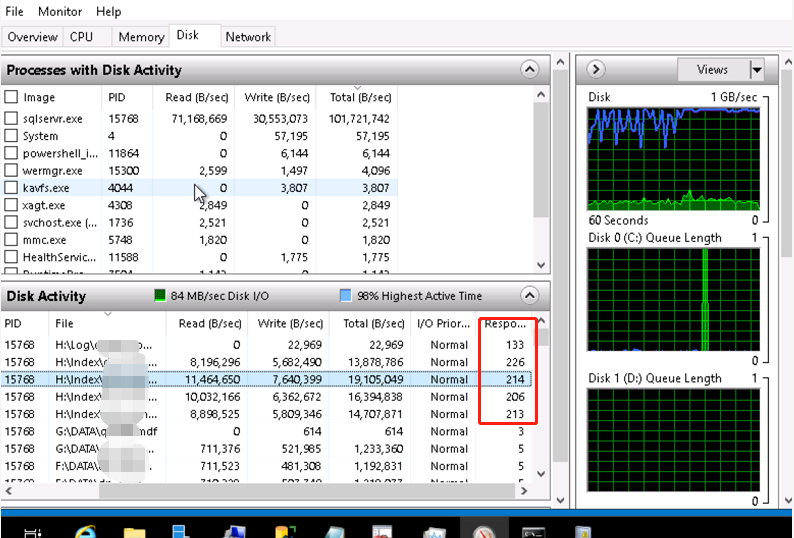
这个时候要注意观察SQL Server日志,有没有报错信息,提示还剩多长时间。
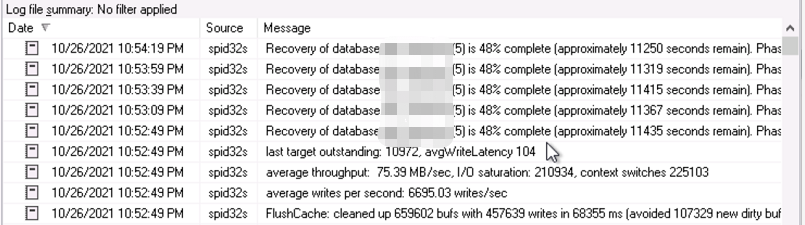
由于中断了得有三天多,加上周末的时候我们数据库一张表对一些过期的数据进行更新(上亿行数据),日志体积相当恐怖。一直到第二天早上10点还没有追上日志同步。
第二天早上10点多的时候我用监控脚本查看了一下alwayson副本的redo queue还堆积了几十个G的日志队列,通过 SQL Server ->> AlwaysOn 监控脚本 里面的监控脚本可以看到有50G的日志队列堆积。
虽然说通过redo rate预估只是需要30分钟就可以完成,但是这点是建立在没有新的日志增加的情况下,我们重启服务的时间点是早上10点,这个时间点我们的应用程序在不断往数据库写入更新数据,不可能说停止应用程序让副本去慢慢恢复。
这个时候出现第二个争议点:
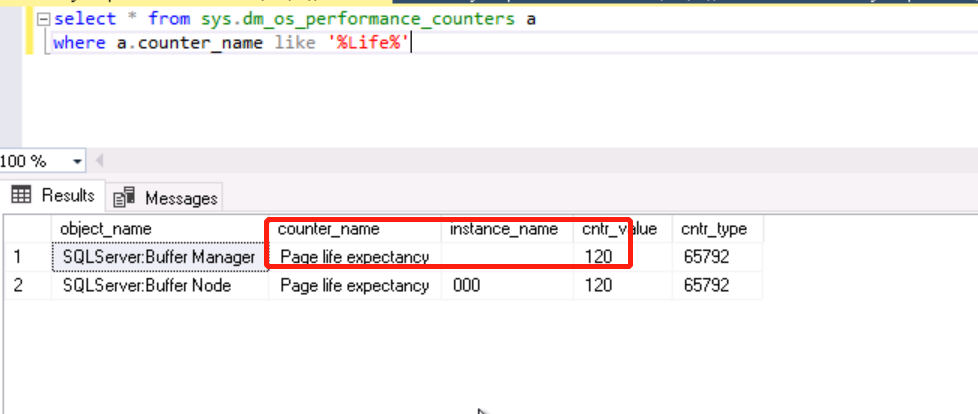
SA同事看到redo的速度跟不上日志增加的数据,一直追不上去,认为说这台机器的内存只有60G(主节点是120G),他通过OS_Performance_counter这个DMV看到PLE只有120秒(主节点是1000吧)。同时又通过Windows的performance monitor看到F盘的磁盘响应时间是200ms以上(正常情况下应该是个位数才是健康值)。认为说是内存压力传导到IO,导致IO响应速度慢。争议点就在这:内存压力导致IO慢。
我是对这点持不一样的意见的。首先PLE这个counter的确是衡量内存压力的一个重要指标值(我做DBA的时候也是经常会查看这个统计值),它说明数据页存留在缓冲区多久时间后就会被刷出缓冲区。但是它是没有基准线的,微软的MSDN Online document也没有说什么样的数值才是健康的,因为每台SQL Server服务器的作用特点都不一样,先不说是作为OLAP还是OLTP,就说OLTP,每个数据库的并发连接和数据读写更的频率都不一样,我们当然知道内存的配置是越大越好,我记得当初学习书籍的时候是等于经常查询更新数据的大小1-2倍。但是我相信没有哪台服务器的内存可以随着系统数据的增加而无限增加。
讲一个题外的故事:我们有个项目今年从本地一台虚拟机环境迁移一个SSAS服务器到Azure云环境,旧的虚拟机环境是一台8核+16G内存的机器,而新的Azure云环境是24核+64G内存的环境,结果迁移完后发现,同样跑一个5 6百G大小的数据库数据到CUBE,老机器正常6-8个小时刷完CUBE,而新的机器既然要12-16个小时。我老大跟我一开始都很诧异。但是仔细回头想想,对于数据库来说,真正的挑战根本就不是CPU和内存。CPU除非你是高并发高数量群的用户,或者本身是OLAP系统。内存除非HotArea数据的大小超出内存大小的几倍甚至十几倍那种,又是高并发。数据库最大的挑战永远都是磁盘IO。因为老机器的磁盘是高性能SSD磁盘(两块,一块放数据库,一块放cube),而新的Azure机器不过是普通E50磁盘(还是单块4T,数据库和cube文件都在一块磁盘上面)。这样一对比,能快就怪了。
当然最重要的是,为什么我这么笃定不一定就是内存原因:
1、内存的作用是数据交换和缓存,数据页会被冲刷出去无法长时间停留在缓冲区很正常,120秒我认为已经算不错了。而且我通过另外一个指标:Buffer Cache Hit Ratio 缓存命中率可以看到是99%。之前学习SQL SERVER管理的时候我记得有一段话讲的特别好:单个系统资源性能指标不能直接说明就是这个系统资源项有问题,CPU、内存和磁盘都是相互作用,要结合起来看。
2、第二点就是这台机器它的作用只是镜像库,不会承担大量的数据查询,它的大部分工作只是redo日志,以及少量的间歇性数据查询。既然不会大量查询数据,内存不应该是瓶颈,好歹有60G,缓冲区冲刷很正常。
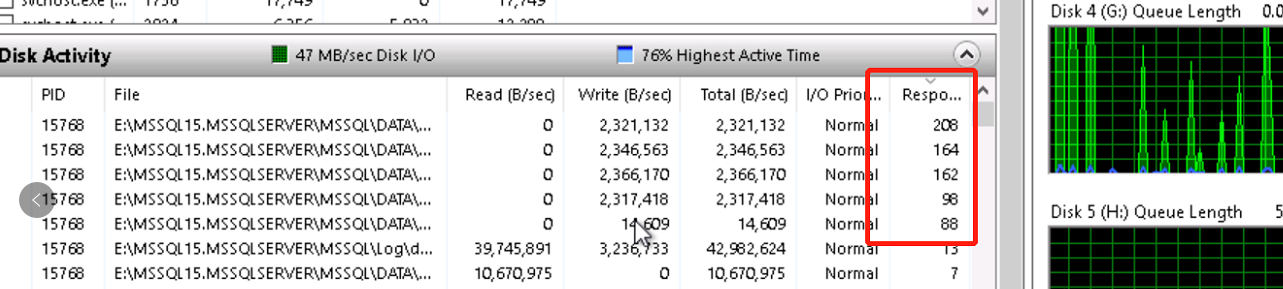
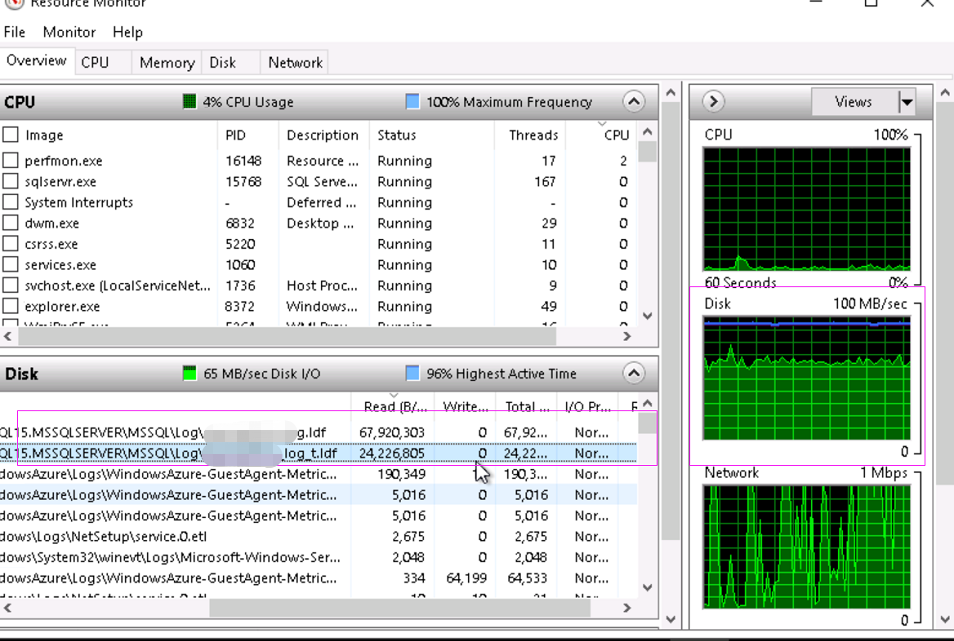
3、第三点是我觉得最重要的一点,我会去想redo的原理,应该是LSN日志链条顺序读取日志,然后读取数据文件页面到内存页,这两步都会占用内存确实,然后再写入到磁盘。这个时候会有三步IO操作,读日志,读数据文件页面和写入到磁盘。日志文件在E盘(独立磁盘),数据文件存放在其他几个盘(F、G和H)。但是我们是建了多个文件组,最重要的是日志指向的数据在哪个文件组下的哪个文件。我打开performance monitor我首先看到F盘的磁盘时间是长时间100%(至少超过10分钟以上),然后我找到F盘下的3个数据库文件的读是150mb/s,但是写只有15mb/s。然后我观察到这三个文件都是属于DATA这个文件组,而DATA这个数据库文件组又恰恰是主要存放数据的文件组。随后我打开数据库文件查看器看到,DATA文件组只有5个文件,一个是限制了大小(而且已经满了),3个存放在F盘(就是前面看到的3个),还有一个在G盘下。这里我再结合业务判断,上周六日中断那段时间,数据库有张表有1亿的数据被更新了状态字段,而这张表的数据基本就是存放在这3个文件中。redo日志必然是要读取文件数据到内存修改,再固化写入到磁盘。所以这个F盘是完全满负荷。磁盘的写入性能我看到只有15-20mb/s,这样的写入性能对比150mb/s的读性能肯定是慢的。所以我推断是F盘的性能瓶颈导致的redo速度没办法加快的原因。
再者说:磁盘响应时间也不能作为推断内存压力的参考,这个值是说明CPU指令向磁盘读写请求的响应时间,我看到在磁盘非常繁忙的情况下这个时间一般在100ms以上。这个值只能说明磁盘非常忙,或者磁盘老化性能下降。