Where to Focus: Query Adaptive Matching for Instance Retrieval Using Convolutional Feature Maps
Abstract
实例检索要求在大型语料库中搜索包含特定对象的图像。最近的研究表明,使用预训练的卷积神经网络(CNN)的池化卷积层特征图(CFMs)生成的图像特征,可以获得很好的性能。但是,由于采用了全局池化策略,生成的图像特征对图像杂波的鲁棒性较差,容易受到不相关的图像模式的污染。在本文中,我们提出了一种新的基于CFMs的重新排序算法来改进现有方法得到的检索结果,从而缓解了这一缺点。我们的关键思想称为查询自适应匹配(query adaptive matching,QAM),它首先用一组可自由组合成更大的感兴趣区域的基区域来表示每张图像的CFMs。然后,通过比较查询特征和从合并区域汇集的特征所获得的最佳相似度分数来衡量查询特征与候选图像之间的相似度。我们证明,上述过程可以转换为一个优化问题,并可以有效地使用一个现成的求解器来解决它。除了这个基本框架外,我们还提出了创建基础区域的两种实用方法。一种是基于CFM的性质,另一种是基于多尺度的空间金字塔结构。通过大量的实验,我们证明了我们的重新排序方法带来了显著的性能改进,并且通过应用它们,我们可以在一些实例检索基准测试中超过当前的最佳水平。
I. INTRODUCTION
实例检索是从一个大型图像语料库中找到一个特定实例的任务。在实际应用中,实例检索面临两大挑战:1)被捕获对象的位置、姿态和光照不同,会导致视觉外观大变形;和2)各种来自自然和杂乱背景的干扰。在过去的十年中,有很多工作使用局部不变描述符[19]来处理实例检索,包括使用大型可视化码本[10]、[20]、[22]、[28]、[30]的方法,以及使用紧凑表征[3]、[11]、[12]、[21]的方法。对于这些方法,虽然已经报告了它们在一些受限数据集[1]、[9]、[22]、[23]中的良好性能,但在目标对象背景杂乱的更现实和更具挑战性的场景中,实例级检索仍然是一个具有挑战性的问题。
最近的研究表明,卷积神经网络(CNNs)聚合卷积特征图(CFMs)生成的视觉描述符在图像检索[4]、[14]、[25]、[31]方面取得了最先进的性能。与传统的局部描述符相比,这些深度学习的特征捕获了更多的语义信息,因为CNN通常是在大的标记图像数据集[26]上训练的。大多数现有的方法将CFMs聚合成一个图像的紧凑全局表征,其中查询到图像的相似性是在图像级别上评估的。如何利用这些深度卷积特征在杂乱的背景中区分目标物体和干扰物仍然是一个挑战。
在本文中,我们遵循基于CNN方法的方向,提出了一种新的重新排序算法,即查询自适应匹配(QAM),利用CFMs来解决实例检索过程中的图像杂波问题。我们的方法的关键思想是,我们用一组基本区域来表示每个数据集的图像,而不是依赖全局图像表示。更进一步,我们允许这些基本区域自由地合并成更大的区域。然后从合并后的区域提取图像特征,而不是从整个图像中提取。此外,我们参数化了可以通过组合基区域创建的区域,并将组合的特征表示为一组参数的函数。因此,调整这些参数将相当于为候选图像选择感兴趣的区域进行聚焦。该方法将参数选择问题转化为一个优化问题,以最大限度地提高查询结果与组合区域特征之间的相似性为目标。最优参数的期望是产生一个焦点区域,涵盖大部分感兴趣的对象。
为了实现这一想法,我们还提出了两种生成基区域的方法。一种是基于CFM特性的方法,另一种是基于多尺度空间金字塔模型的方法。通过在各种实例检索基准上的实验,我们证明了所提出的QAM重新排序和两种基区域生成方法能够取得良好的结果,并且优于当前的研究水平。除此之外,我们还讨论了使用CFMs进行实例检索的几个实际问题,包括深度CNN模型的选择和卷积层的选择。
II. RELATED WORK
A. Non-CNN Based Retrieval
在过去的十年中,实例检索主要是通过使用局部不变描述符的方法来处理的,例如SIFT[19]。以往的工作大致可以分为两类:1)将局部描述符编码为大型可视码本和稀疏表征的方法,即Bag-of-Words(BoW)[10]、[20]、[22]、[28]、[30];2)将局部描述符聚合成密集紧凑的[3]、[11]、[12]、[21]特征的方法。由于可视词量化后空间信息的丢失和描述符辨别能力的下降,BoW模型通常会进行一些后处理步骤,如空间验证[22]或查询扩展[6],以消除false positive结果。在实际中,BoW模型采用inverted索引进行高效搜索,但可索引的图像数量受到搜索时间和索引大小[11]的限制。另一种策略是将局部描述符聚合成紧凑的表征,例如,压缩Fisher Vector[21]、VLAD[3]、[11]和使用democratic aggregation[12]的T-embedding。然而,最近[4]、[5]、[14]、[24]、[25]、[31]、[33]的研究表明,从CNN提取的神经元激活可以作为较好的图像表征,在低维数设置中优于传统的特征。
B. CNN Based Retrieval
自“AlexNet”[15]在大尺度图像分类[26]中取得成功后,CNN在计算机视觉中得到了广泛的应用。最近的研究[5],[24],[33]表明神经网络神经元的激活可以作为图像检索的通用特征,这些特征来自于全连接层。但是,这些层是在标记好的对象上训练的,以方便图像分类,因此可能不能泛化到某些实例类型。这些方法通常需要在目标(或视觉上相似的)数据集[5]、[33]上对CNN进行微调,才能获得满意的检索性能。
除了全连接层外,[4]、[14]、[25]、[31]等也出现了一种新的趋势,即利用卷积层的激活作为图像特征,称为卷积特征映射(convolutional feature maps, CFMs),表现出更优的性能。其中,Razavian等[25]提出利用CNN将图像分割成多个方形patches,提取patches描述符。在搜索过程中,对所有patches进行交叉匹配,得到最优的匹配结果。显然,由于计算量大,该方法不能处理大规模数据集。Babenko等人[4]提出了一种简单而有效的基于sum-pooling的CFMs聚合方法,可以生成用于检索的紧凑全局表征(256维)。但其性能仍落后于传统方法。Tolias等人[31]提出了一种聚合方法,该方法首先将CFMs分解为不同尺度的多个区域,然后通过sum-pooling对它们进行聚合。该方法还生成了紧凑的表征,并且在大多数情况下优于[4]。此外,本文还提出了一种基于sum-pooling的CFMs重新排序方法,可以对目标对象进行粗略定位。与传统方法相比,它们的检索框架达到了可比甚至更好的性能。我们使用了与[31]相似的检索管道,但是我们提出了不同的重新排序算法,可以更灵活、准确地检测目标对象的识别区域,从而获得更好的检索性能。
III. INSTANCE RETRIEVAL USING CFMS
正如前面提到的,最近的研究[4]、[14]、[25]、[31]已经表明,使用CFMs作为图像特征在实例检索中获得了很好的性能,我们的工作将沿着这个方向进行。在详细介绍我们的方法之前,本节将简要讨论CFMs,它们的属性以及它们在实例检索中的使用。这些讨论为我们的方法提供了动力和启示。
A. Preliminary
卷积层生成的CFMs可以排列成一个大小为H×W×D的张量(见图1),其中H和W表示各特征图的高度和宽度,D表示该层中各特征图(或通道)的数量。由于每个滤波器的局部连通性,可以将所有特征图中同一空间位置的激活组成一个针对某一图像区域的D维局部描述符(因为D个channels的特征图中D个同一位置的结果其实就是D个过滤器对输入的同一位置的计算得到的值,其大小为1*1*D),该区域的大小等于滤波器接受域的大小。本文将该局部特征形式化表示为xi∈RD,下标i表示CFMs中的第i个位置。在CFMs中总共有H×W个这样的位置。上述布置如图1所示。与全连接层激活相比,CFMs的主要优势在于它保留了局部图像模式[17]、[18]的空间信息,本质上更类似于传统手工设计的局部特征。实际上,来自一个卷积层的CFMs可以看作是从密集采样网格中采样的一组局部特征。
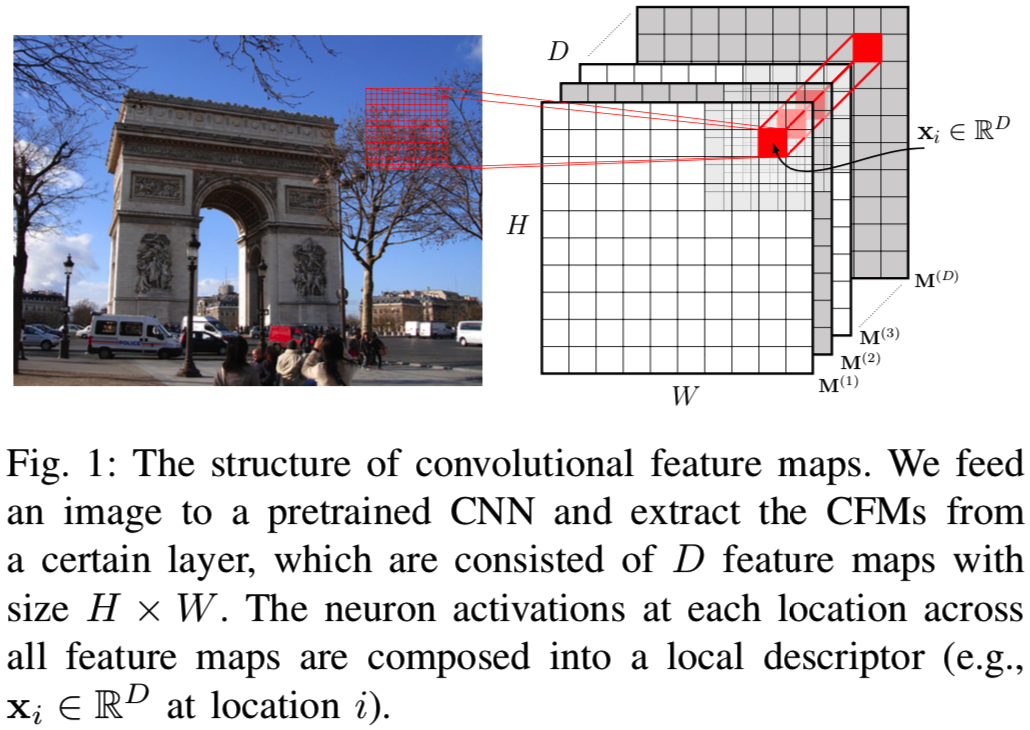
在整个论文中,我们使用如下的标注。让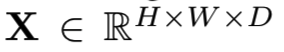 表示从第l层(ReLU之后)抽取的CFMs。它可以等价地表示为局部描述子集合
表示从第l层(ReLU之后)抽取的CFMs。它可以等价地表示为局部描述子集合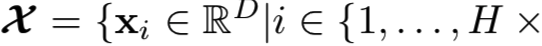
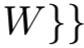 。在下面的章节中,我们使用从INSTRE数据集[34]的不同目标类别中选择的三个样本图像来进行阐述(可见图2)
。在下面的章节中,我们使用从INSTRE数据集[34]的不同目标类别中选择的三个样本图像来进行阐述(可见图2)

B. Understanding CFMs
由于卷积层[16]的参数共享设计(即卷积层的过滤器),卷积的特征映射层可以看作是在H×W大小的空间位置应用一个检测器得到的检测分数, CFM的第i个位置的激活值特征化了同一位置的检测器响应结果。通过这个类比,我们可以通过可视化对CFM有一个直观的理解,即高度激活的位置表明其周围包含了卷积层过滤器所描述的视觉模式。图3给出了这样的说明。在图3中,选择平均激活分数前5位的特征图(即D个channels中的每个channels的特征值求和平均得到D个channels的特征图的平均激活分数)进行可视化。另外,不同卷积层的激活模式比较如图3所示。
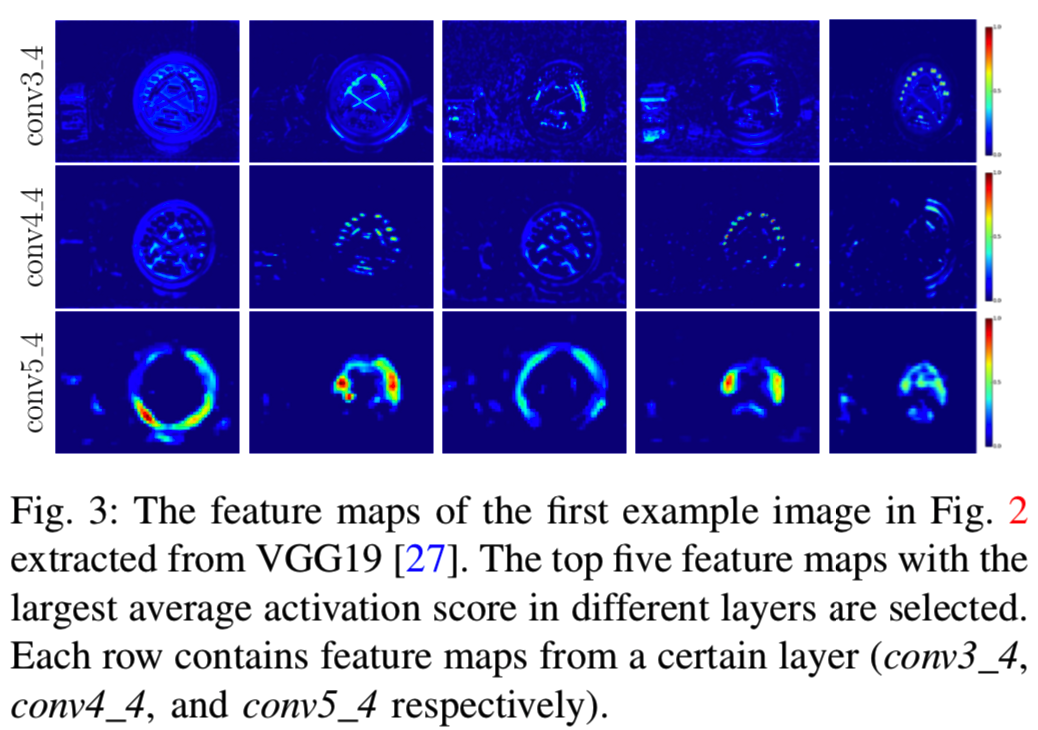
从中我们可以看出以下两点:
- CFM只有在某些特定视觉模式存在的少数位置有高激活值。这表明卷积滤波器可以高度选择特定的视觉模式,因此CFM可以是稀疏的。
- CNN的早期卷积层倾向于捕捉一些主要的视觉模式,如沿一定方向的边缘或点,而后面的卷积层通常会选择对应一个形状或物体部分的视觉模式,如圆形或轮区域。
C. CFMs Aggregation for Instance Retrieval
要执行实例检索,图像需要用一个特征向量或一组特征向量表示。为此,CFMs可以通过一些pooling策略进行聚合,这些pooling策略在最近的一些研究[4]、[14]、[25]、[31]中得到了探索。这些作品中的大多数采用了全局pooling策略,也就是说,CFMs中所有位置的局部特征将被聚集在一起。在最简单的情况下,我们可以采用以下pooling操作:
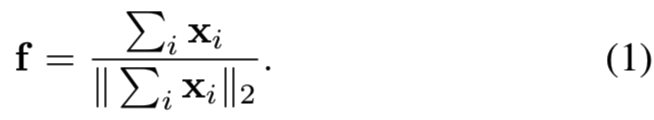
也就是说,首先对所有局部特征进行sum-pooling,然后进行l2-归一化,得到聚合的图像表征f。在实际应用中,l2归一化非常重要,如果不进行归一化,检索性能会显著下降。
尽管全局pooling策略简单有效,但它的缺点是对杂乱图像背景的鲁棒性较差。这是因为对于实例检索,查询可能只是一个被裁剪的对象。因此,在候选图像中,感兴趣的对象可能只占图像的一部分,而全局池化从整个图像区域聚合视觉模式。为了缓解这种情况,一种解决方案是对图像的多个区域(或者对应的CFMs)执行池化,并创建多个池化特征来表示图像。然后,查询将与所有汇集的特征进行匹配,最佳匹配分数将被用作查询与图像之间的相似性。然而,这一解决方案提出了如何选择这些区域的问题。一方面,由于检索系统的存储瓶颈,区域的数量不能太大。另一方面,所有可能的子区域的空间可以是非常大的,特别是考虑到对象可以采取任何形状,因此对象的形状可以比一个边界框复杂得多。因此,针对多区域池化思想设计区域生成策略具有很大的挑战性。
IV. QUERY ADAPTIVE CFMS MATCHING RERANKING
本文采用了第III-C节讨论的多区域池化策略,提出了一种优雅的解决方案,既能挖掘大量可能的区域,又能保持池化区域的低存储量。我们的方法首先生成少量的基区域,这些基区域可以(柔和地)合并成更大的区域。因此,基区组合所能代表的区域总数非常大。对于查询图像,我们将其与所有可能的区域组合进行比较,并选择最佳匹配分数作为查询到图像的相似性。乍一看,上述过程的费用可能高得令人望而却步。然而,如果我们使用一组参数来控制合并操作,合并区域的池化特征可以表示为这些参数的函数。上述匹配过程可以看作是一个优化问题,即寻找最优参数,以最大限度地提高池化特征与查询图像特征之间的相似度。最优目标值表示组合区域与查询图像之间可能的最佳匹配分数。当然,这种方法比直接比较图像特征的速度要慢,因此在本文中,我们使用它作为一种重新排序的方法,并仅应用于现有方法检索到的候选图像short-list中。在下面的小节中,我们将详细阐述这一思想的形成和实现细节。
A. Query Adaptive Matching
在形式上,我们的方法假设每幅图像已经通过基区域生成方法提取了一组基区域,详细内容我们将在第IV-B1和第IV-B2节中介绍。将每个基区域内CFMs的sum-pooling特征表示为fk,合并一组基区域得到的归一化sum-pooling特征表示如下(在实践中,fk可以通过其他的pooling方法生成,例如max-pooling,我们仍然使用等式2来合并多个待合并区域的特征。这种处理方法使我们的方法更普遍适用):
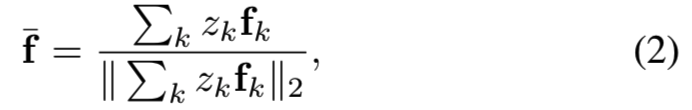
其中zk是一个二进制指示符(即值为0或1),当其值为1时,将其对应区域添加到合并区域中。在实践中,我们也可以放宽其值为正实值,这意味着一个soft归并操作。因此查询图像q和合并特征之间的相似性可以由他们的内积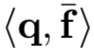 得出。可以看出,这个相似度是{zk}的函数,我们的目标是找到通过soft合并基区域可以获得的最佳相似度分数。然后这个最佳匹配分数将被用来重新排序shortlist。寻找最优{zk}可以写成如下优化问题:
得出。可以看出,这个相似度是{zk}的函数,我们的目标是找到通过soft合并基区域可以获得的最佳相似度分数。然后这个最佳匹配分数将被用来重新排序shortlist。寻找最优{zk}可以写成如下优化问题:
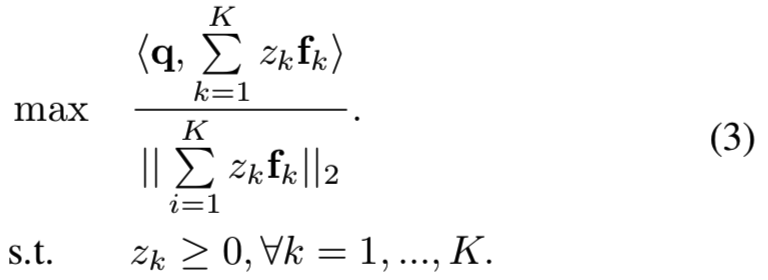
为了简化,等式3可以紧凑表示为:
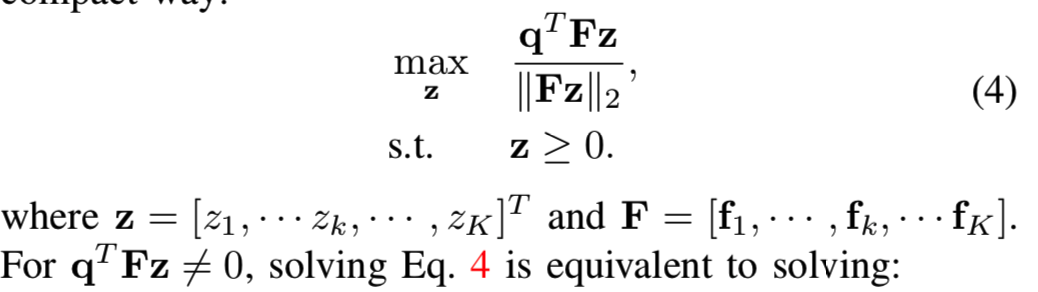
求解等式4相当于求解下面的式子:
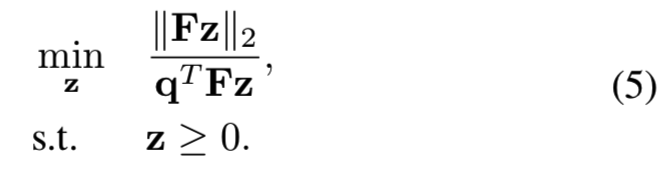
进一步限制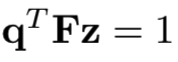 来避免z的任意缩放,因此能够保证优化问题有唯一解。最后的优化问题如下所示:
来避免z的任意缩放,因此能够保证优化问题有唯一解。最后的优化问题如下所示:
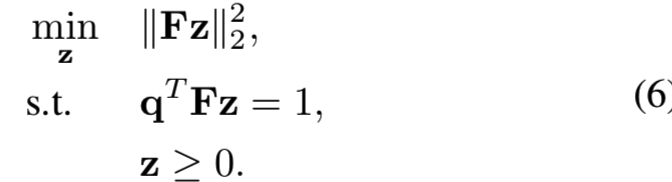
等式6是一个二次规划(QP)问题,可以通过现有的优化包有效地解决。我们用这个最优值的倒数,即等于等式3中的目标值,作为图像相似度分数。
B. Base Region Generation
上述方法适用于以任何可能的方式生成的基区域。在这项工作中,我们特别关注创建这样的基区域的两种方法。
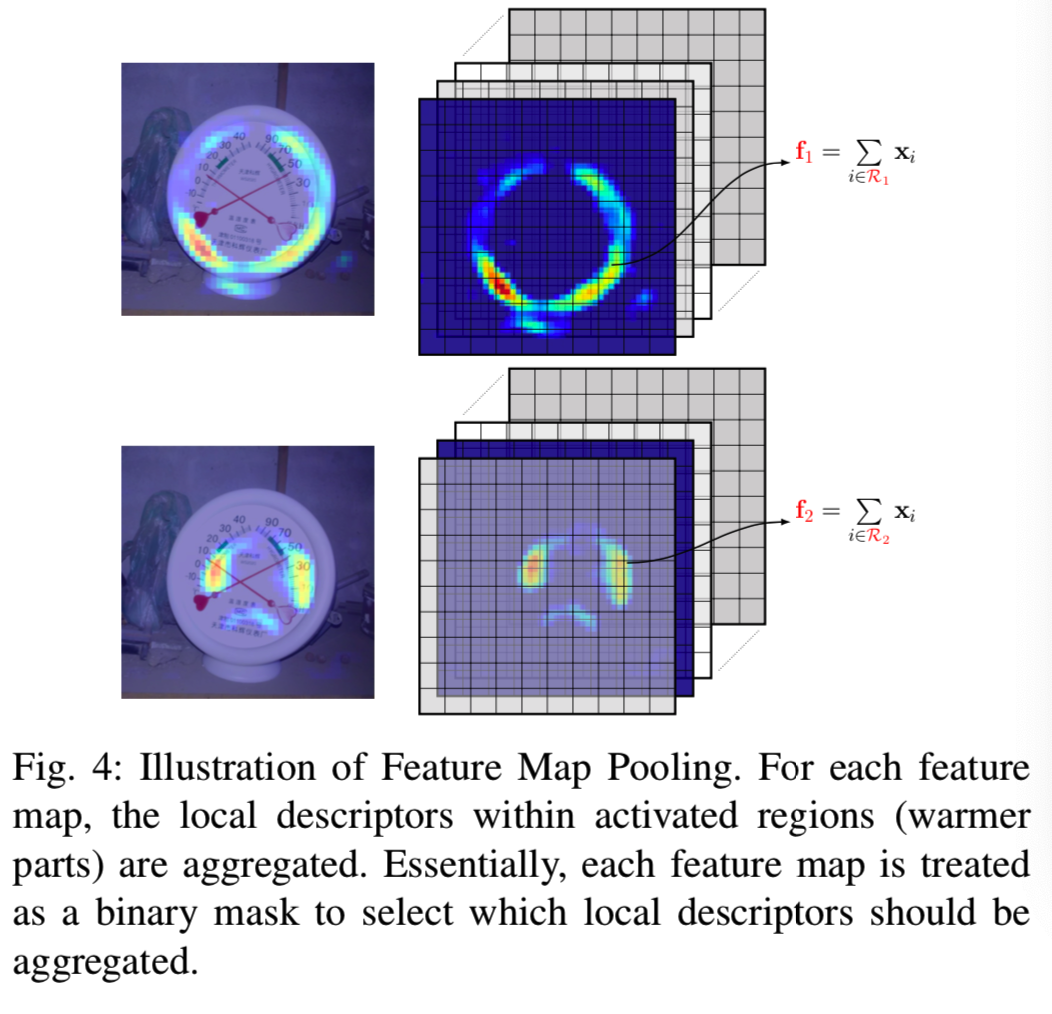
1) Feature Map Pooling (FMP):我们的第一种生成基区域的方法是受到了第III-B节观察的启发。如第III-B节所述,在后期卷积层中,CFM的激活区域通常表示一个对象部分。它们的结合可以覆盖整个图像,或者至少覆盖那些具有有意义的视觉模式的区域。因此,卷积层中每个CFM的激活区域可以直接用作基区域。具体说来,给定一个CFMs集,定义在第d个特征映射(即D维通道上的一个通道)上的非零元素的集合为一个基区域,即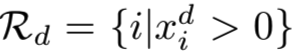 。该基区域的池化特征计算如下:
。该基区域的池化特征计算如下:

在我们的实现中,我们也用l2归一化后的fd来补偿区域大小差异。我们将这种基区域生成方法称为Feature Map Pooling,简称FMP。使用FMP,将X(即CFMs)转换为D区域描述符(即D维的每个通道的非零元素都能组成一个基区域,所以基区域有D个),可以对应不同的目标部分,如图4所示。
一旦选择了一个预先训练好的CNN的卷积层,其基区域的数量就等于该卷积层的特征映射或channel的数量。但是,对于给定的图像,许多CFMs的激活区域可能高度重叠。因此,如果使用CFMs生成的所有基区域,将是一种计算浪费。为了减少计算量,本文对基区域进行了合并。我们首先用对应的池化特征fd表示每个基区域。如果两个CFMs具有相似的激活区域,则它们对应的池化特征将是相似的。因此我们运行一种聚类方法,K均值聚类或光谱聚类[32],将D个池化特征聚类为K个聚类。将池化特征集合在一起的基区域合并为一个基区域。在我们的实验中,这一合并操作将基区域数量从512个减少到30个左右,大大降低了计算量。
2)Overlapped Spatial Pyramid Pooling (OSPP)(Overlapped Spatial Pyramid Pooling, OSPP):另一种生成基区域的方法是直接从图像中抽取一些矩形区域。Tolias等人[31]提出了一种区域采样方法,用于在不同尺度、不同位置采样区域。在我们的工作中,我们采用类似的策略来生成基区域。更具体地说,如图5所示,我们在L个不同尺度上采样正方形区域。
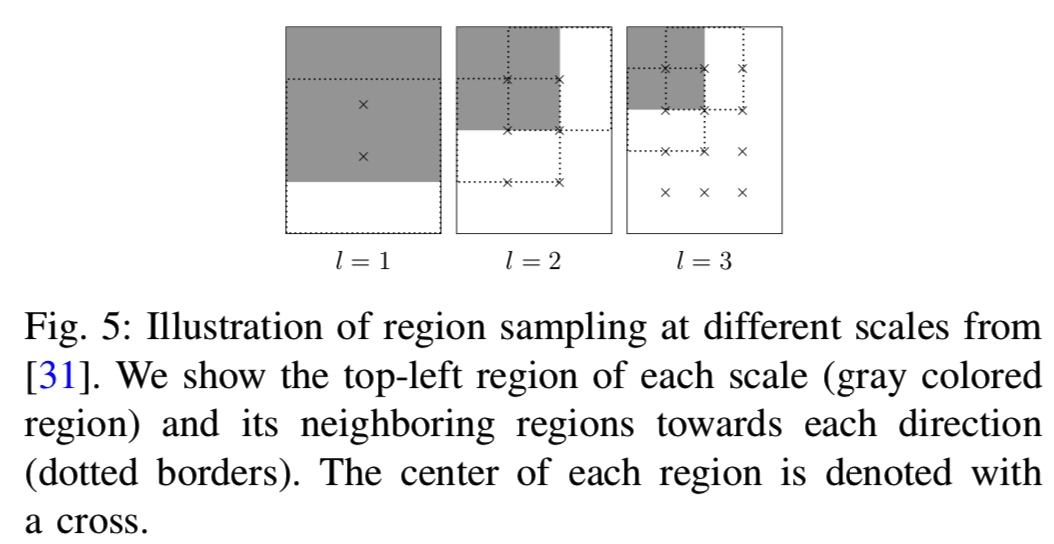
给定一个图像的CFMs ,我们在第l层均匀采样宽度为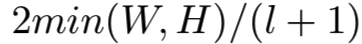 的区域。而且,在连续区域中哦,采样的区域允许大约40%的重叠。
的区域。而且,在连续区域中哦,采样的区域允许大约40%的重叠。
注意,即使使用类似的采样策略,我们的方法也不同于[31]中的工作。后一种方法是将每个采样区域生成的特征集合在一起,得到一个全局的图像表征,而我们的方法是将采样区域作为基区域,并将基区域输入到我们提出的查询自适应匹配算法中。
C. Retrieval Pipeline
最后,为了获得最佳的检索性能,我们采用以下管道进行检索。
- Initial Retrieval. 在离线预处理中,所有数据库图像的CFMs都是通过预先训练好的CNN来提取的。全局图像表征由现有的聚合方法(如SPoC[4]、R-MAC[31]或CroW[14])计算。在线上搜索过程中,我们对查询图像提取相同的特征,通过计算特征相似度(例如内积)来评估查询图像与所有数据库图像的相似度,从而得到一个初始排序列表。
- Reranking. 将从初始排序列表中选择一个包含前N个候选项的shortlist进行重新排序。基区域描述符被离线提取,现在它们被用来代表每个候选图像。我们求解等式6,得到查询与候选图像之间的相似度得分,以便重新排序。
- Query Expansion (QE). 最后,我们选择[31]中重新排序后的前5幅图像,并通过平均池化将它们的全局表征与查询图像的特征进行聚合。我们使用聚合的特征作为一个新的查询,并再次执行检索以获得最终的排序列表。
V. EXPERIMENTS
A. Experiment Settings
1)数据集:我们在以下方面评估我们的方法
数据集:
- Oxford5k[22]包含5062张图片,对应11个Oxford地标。每个地标有5个可能的查询图像,总共55个查询。该数据集可以与Flickr100k[22]中的100,071个干扰物相结合进行大规模检索评估。我们将组合数据集表示为Oxford105k。
- Paris6k[23]与Oxford5k类似,但由6412张对应12个Paris地标的图片组成。它还可以与Flickr100k混合,即得到Paris106k,用于大规模检索评估。
- Sculptures6k[1]有6340个平滑的雕塑图像,这与之前的两个地标性数据集不同。整个语料库平均分为训练数据集和测试数据集。因为我们的重点是通用实例检索,所以我们评估方法时不使用任何训练图像来进行CNN学习或微调。总共有70个查询。
- INSTRE[34]包括来自200个物体的23,070幅图像和100万幅干扰物图像。这些对象可以分为三类:建筑(建筑和雕塑)、平面对象(设计、绘画和平面)和日常的立体对象(玩具和不规则形状的产品)。这个数据集是具有挑战性的,因为每个对象都有不同的变化,而且大多数对象都有杂乱的背景和较少的上下文背景。来自200个对象的所有带注释的图像(总共23,070个)都用作性能评估目的的查询。
所有数据集上都提供了查询边框,用于在检索期间裁剪出目标对象。评价指标为所有数据集的mean average precision(mAP)。
2) CFMs Extraction: 我们使用Caffe[13]提供的VGG19[27]模型,从最后一个卷积层(conv5_4)提取CFMs,因为之前的研究[4]、[14]、[31]显示该层的性能最好。在特征提取过程中,数据库图像和查询都保留了原始图像的大小。但对于面积大于1000×1000的大图像和小于256的小图像,我们在保持原宽高比的前提下对其进行相应的调整。所有的输入图像都以RGB平均像素差[8](RGB mean pixel subtraction)为零中心。
3)Global Feature Generation: 我们评估了两种最先进的CFMs聚合方法:没有中心先验( center prior)[4]的sum-pooled卷积特征(SPoC)和卷积的区域最大激活(R-MAC)[31]。我们使用[4]和[31]中报告的最佳设置。对于所有[4]数据集,SPoC和R-MAC都需要PCA-白化,并在保留图像(即没有用来训练的图像)上学习PCA参数。具体来说,在Oxford5k上执行检索时,我们从Paris6图像学习参数(即Paris6为训练图像,Oxford5k为测试图像),反之亦然。对于Sculptures6k和INSTRE(检索图像),我们在Flickr100k数据集(训练图像)上学习参数。在接下来的实验中,我们使用内积作为检索SPoC和R-MAC的相似性度量。所有实验都是在一个拥有40个3.0GHz CPU内核和256GB内存的Linux服务器上进行的
。
B. Performance of QAM Reranking
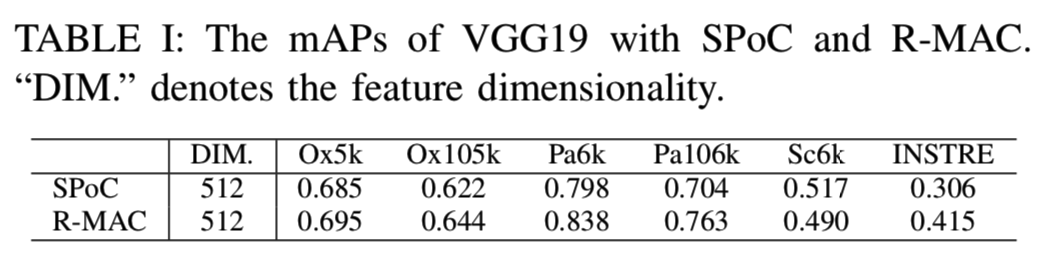
我们首先在Tab I中报告上述全局表征的初始检索结果,作为所提方法的基线。值得注意的是,这里报告的SPoC的mAP要高于[4]报告的结果(如Oxford5k的mAP从0.531增加到0.666,Oxford105k的mAP从0.501增加到0.606)。这是由于实现上的不同:1)在我们的实现中,将图像送入CNN进行特征提取时,没有像[4]那样将图像大小调整为正方形;2)在PCA-白化过程中保持原表征维数。从表中我们可以看到R-MAC在所有数据集(除了Sculptures6k)效果都优于SPoC。因此,在评估我们提出的QAM重新排序的性能时,我们使用R-MAC进行初始检索。
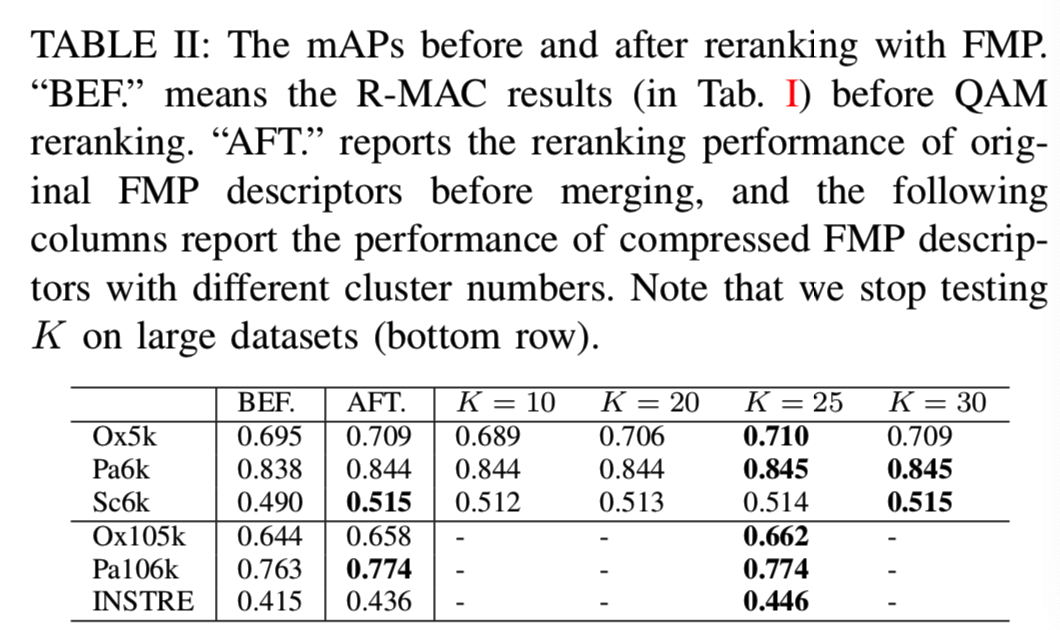
1) QAM with FMP: QAM是基于查询特征q和候选图像的区域描述符F的。为了获得q,查询图像的CFMs是经过sum-pooling和L2归一化的。对于数据库图像,我们按照第IV-B1节中描述的步骤获取其区域描述符。结果显示在表II中。这里我们选择R-MAC进行初始检索,其结果作为我们重新排序方法的基线。从结果中,我们可以看到对所有数据集进行初始检索时重新排序的改进。
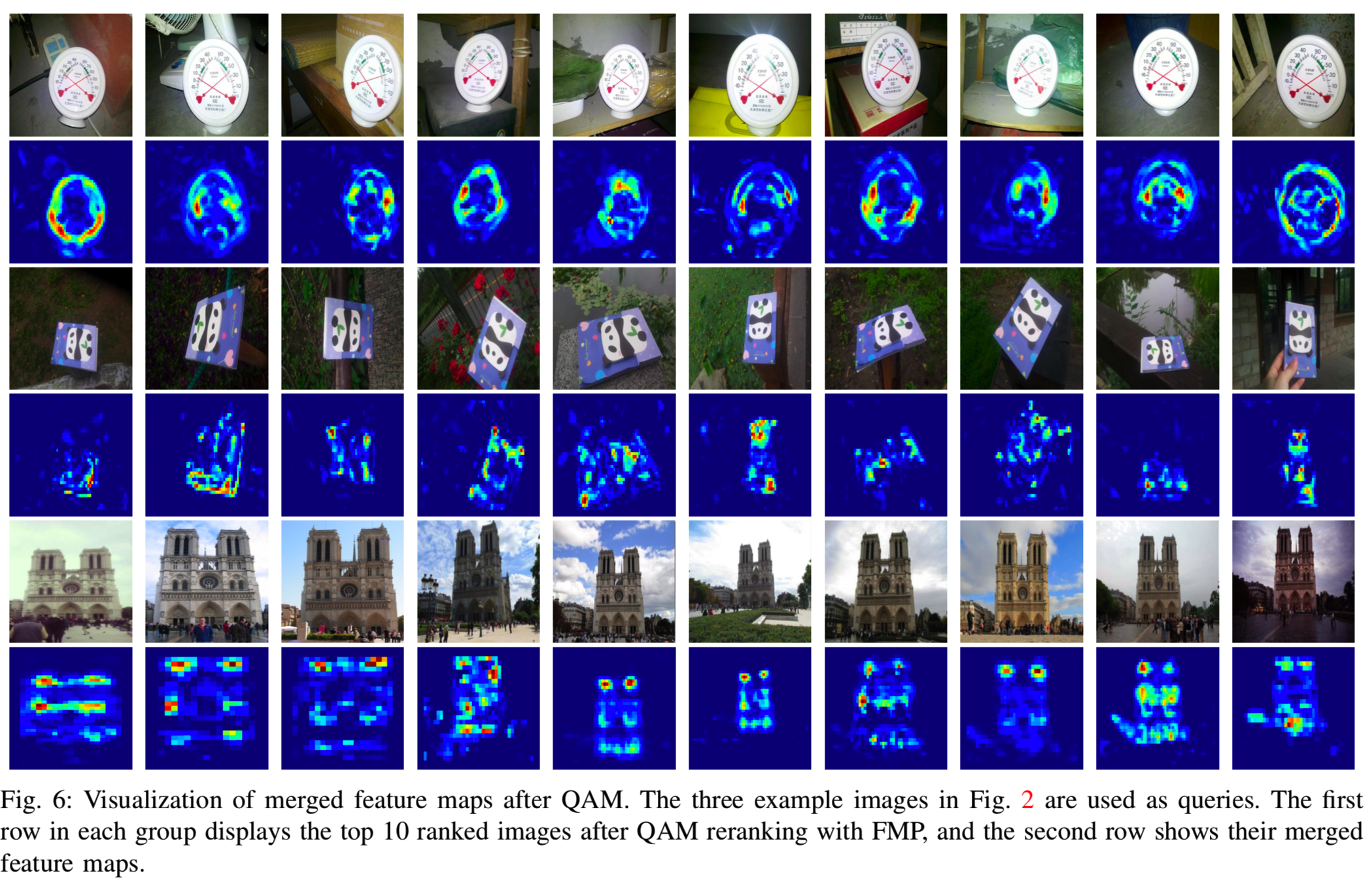
为了更直观地展示使用FMP进行QAM的有效性,我们将QAM后的一些合并特征图可视化,如图6所示。我们使用图2中的三个示例实例作为查询,并在重新排序后可视化排名前10的候选结果。QAM的目标是找到候选图像的基区域的最优合并,使其与查询特征的相似性最大化。在解决了式6中的匹配问题后,我们得到了最优的集合权值z,我们将第i个特征映射与其对应的加权值zi相乘,然后将所有的特征映射相加,形成一个合并的映射。QAM选取数值较大的区域(暖区)作为查询的判别部分,而数值为零的区域(蓝色区域)往往与QAM忽略的无关背景相对应。正如所见,QAM能检测目标物体的鉴别成分,同时抑制干扰。结合FMP的QAM的另一个优点是它可以选择形状不规则的目标部件,这在很大程度上有利于特征聚合。
如第IV-B1节所述,FMP为每个数据库图像生成512个基区域,其中一些基区域是重叠的。为了减少计算量,我们的处理方法是在离线的情况下对区域进行光谱聚类来预合并,聚类数量与合并后的区域数量相对应。为了在重新排序性能和检索效率之间取得平衡,我们在Tab II中测试了不同簇数K下FMP的性能。可以看到,最初增加集群数量会带来更好的性能。一个有趣的发现是,当K = 25时,性能与不聚类时相当,甚至更好。在K = 25之后,继续增加K,结果保持稳定。基于这个观察,我们在接下来的实验中固定K = 25。经过该预合并步骤,将FMP特征从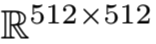 下降到
下降到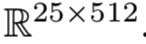
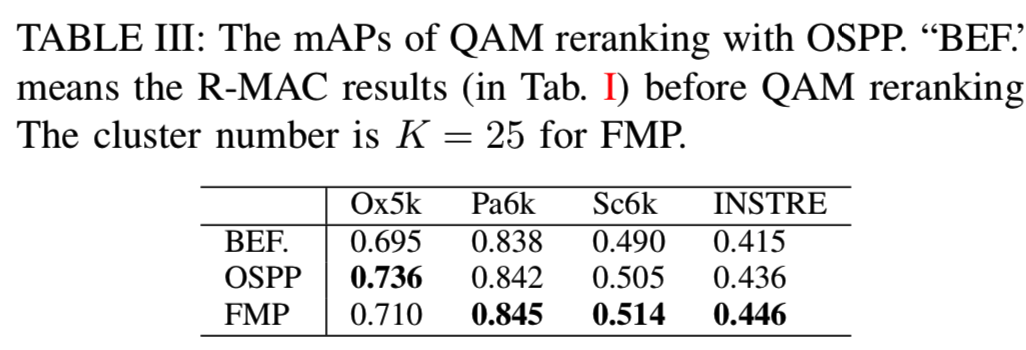
2)QAM with OSPP: 在本节中,我们评估使用另一种基区域生成策略——重叠空间金字塔池化(OSPP)方法的QAM重新排序。当使用OSPP重新排序时,查询图像的CFMs通过R-MAC聚合,对于候选数据库图像,我们遵循第IV-B2节中描述的过程来生成它们的区域描述符。对于查询和候选对象,尺度数设置为3 (L = 3),与[31]中相同。重新排序的结果显示在表III中。可以看出,使用OSPP重新排序在所有数据集上的性能都优于初始检索,证明了所提出的重新排序方法的有效性。
并对表III中提出的两种重新排序方法进行了比较。基于不同的区域生成机制,这两种重新排序方法具有不同的优势。对于FMP,它可以生成与不规则形状的对象部分相对应的基区域,这些不规则形状比矩形等规则形状更加灵活。对于OSPP,该算法考虑了多尺度信息,使得匹配更加鲁棒。因此,我们看到这两种重新排序策略在数据集上具有不同的性能。但总的来说,它们的性能是相当的,都优于基于R-MAC的初始检索。
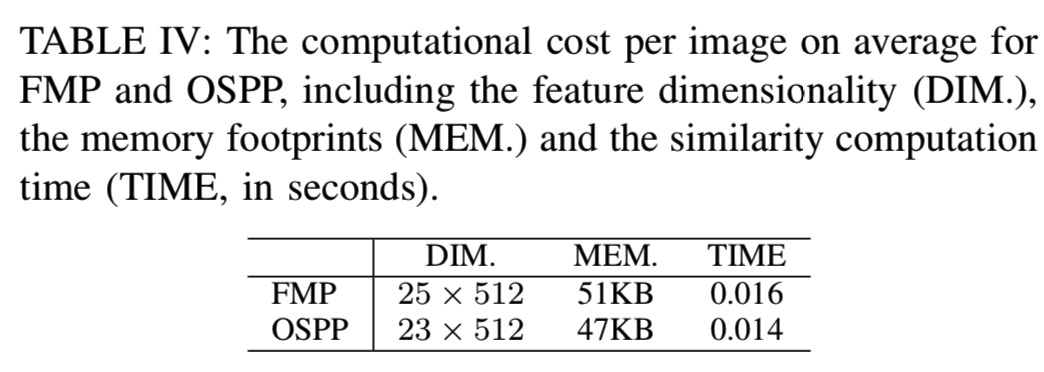
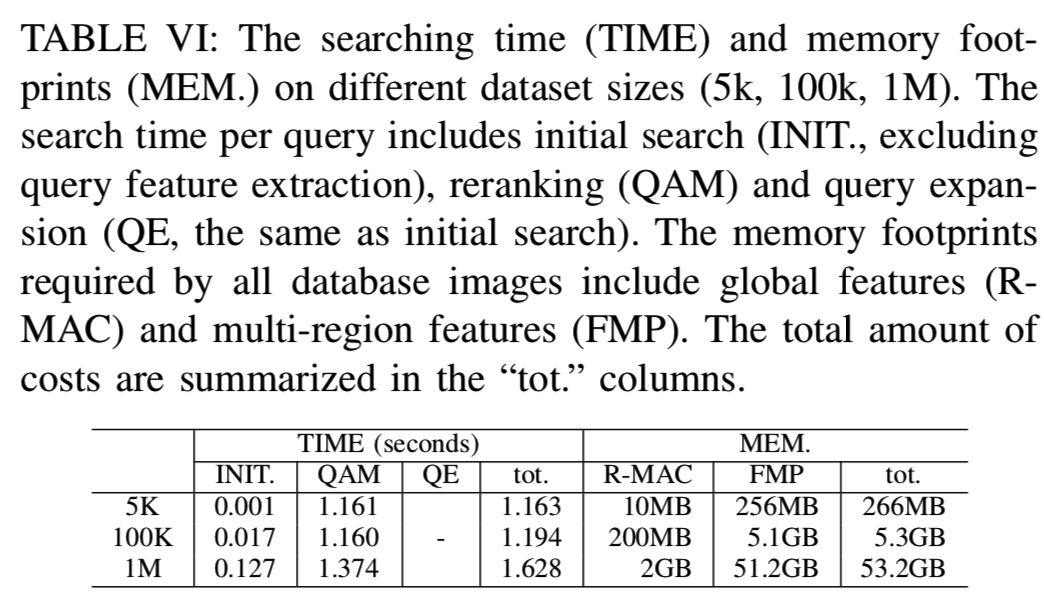
3) Computational Cost of QAM Reranking: 由于效率是实例检索的一个重要方面,在本节中,我们将评估所提议的重新排序策略的存储代价和计算代价。具体来说,我们报告了执行一次相似度匹配的平均成本。结果显示在表IV中。对于基于FMP的重新排序,我们使用聚类方法将数据库图像的离线基区域数从512合并到25,显著减少了QAM的内存占用和计算量。对于OSPP,数据库图像的区域数平均为23个。结果表明,两种QAM策略都可以在可控制的内存占用下高效地执行,大约15毫秒。因为重新排序是在初始检索的前100个候选列表上进行的,所以每次查询的开销约为1.6s。
C. Comparison With Existing Work
我们完整的检索管道由三个步骤组成:使用R-MAC进行初始检索,使用FMP进行QAM重新排序,以及最后的QE(参见第IV-C节)。这里,我们将我们的完整检索方法与表V中的最新技术进行比较。
结果被分为两个部分,上面的部分是使用不同紧凑表征但不涉及后处理的检索方法,例如重新排序、空间验证或QE,另一部分对应于使用后处理策略的方法。
从第一部分我们观察,当聚合可比较的维度时(即维度数相同时),基于CNN的表征比基于SIFT的紧凑表征可以有更好的检索性能,在CNN表征中,R-MAC得到了自从即考虑多尺度信息又考虑弱的空间信息以来的最好效果。

表V的第二部分报告了使用后处理的方法与。Je ́gouetal.[10]对传统的BoW模型进行了改进,采用了hamming embedding和弱几何一致性约束,但在[34]报道的INSTRE上,该方法的结果并不令人满意。我们的方法在除Oxford5k和Oxford105k之外的所有数据集上都取得了最好的性能,在Oxford5k和Oxford105k中开发良好的BoW模型[6]、[20]效果更好。[2]和[35]报告了在Oxford5k和Paris6k中更高的mAP(超过0.9)。但是由于他们的方法学习了原始数据集上的可视码本,因此是高度定制的,结果不能直接比较。与[1]中针对平滑对象提出的特殊表征-Bag-of-Boundaries(BoB)相比,我们的方法性能增强10%,具有更好的泛化能力。我们主要关注与[31]中最新的工作进行比较,因为它们的表征是基于CFMs的,而且与我们有类似的检索管道。他们的方法和我们的方法最显著的区别在于重新排序策略。为了公平比较,我们使用类似于[31]的初始检索。从结果可以看出,我们的方法始终具有优越的性能。另一点值得一提的是,据我们所知,我们的方法在INSTRE数据集中取得了最好的性能,这表明我们的重新排序方法对背景杂乱的数据集的鲁棒性。
最后在表VI中给出了每个查询的检索管道中不同组件的搜索时间以及整个检索框架在不同数据集大小上的内存消耗情况。
D. Performance with Deeper Networks
最近的研究发现,更深层次的神经网络可以显著改善图像分类和目标检测等任务。在这里,我们将在实例检索方面探索其中两个更深层次的网络。一个是GoogLeNet[29],它是一个包含了“Inception”模块的22层网络;另一个是最近提出的152层卷积神经网络[7],名为深度残差网络(ResNet152)。
1)Feature Patterns:为了直观地理解这两个网络的CFMs,我们首先对这两个网络的CFMs特征模式进行可视化。具体来说,对于每一层的CFMs,我们计算所有局部描述符(||xi||1)的L1-范数,并根据这一层的最大范数对它们进行归一化。这些范数值的heat maps反映了不同图像部分的激活程度。从更好地探索过的AlexNet或VGG网络中,我们知道,通常较低层的CFMs对应一些主要模式,如边,而较高层的CFMs捕获一些与对象相关的语义。heat maps在空间上趋于稀疏。在这里,我们观察到GoogLeNet和ResNet152的CFMs的一些差异,图2中第一个示例图像的可视化显示如图7所示。

对于GoogLeNet来说,对象的结构从初始4a到4e层一直存在于CFMs中,其中激活的模式是稀疏的,并且对应于一些有意义的对象部分,但是结构信息在更高的层(5a和5b)中往往丢失。对于ResNet152,稀疏属性并不在较低的层中保持(从conv1到res4),而是在较高的层中保持(res5a-res5c)。由于激活模式在CFMs聚合中起着重要的作用,我们试图揭示CFMs的检索性能与其对应的特征模式之间的一些关系。
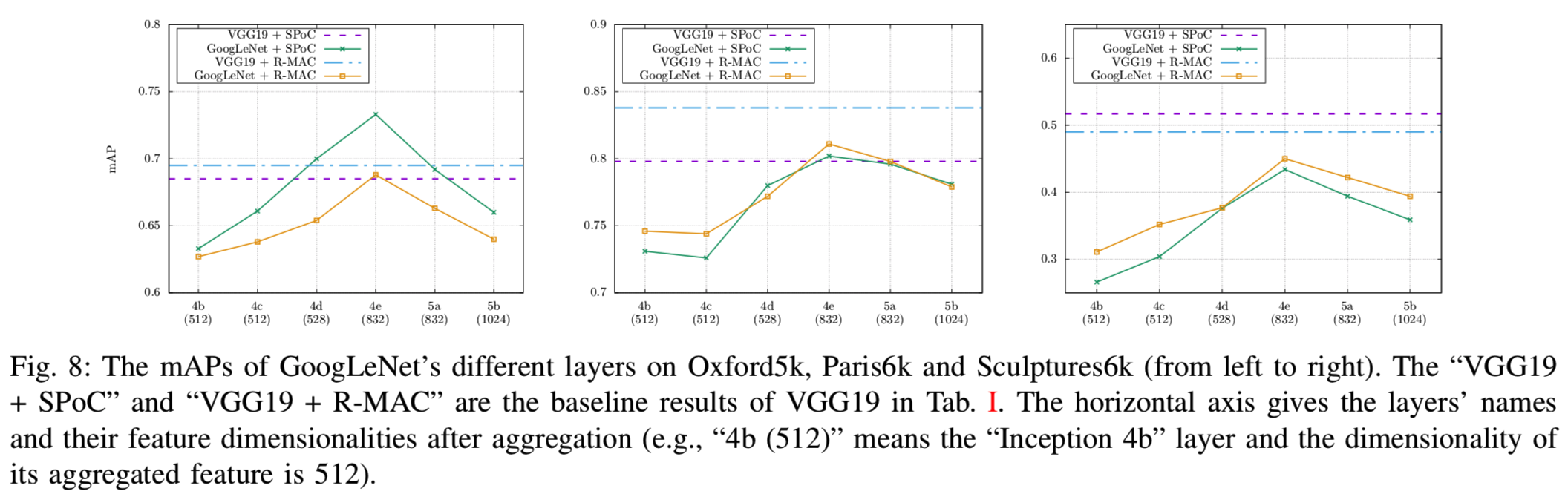
2)Choosing the Right Layer: 这里我们使用不同的全局聚合方法评估不同层的CFMs检索性能(第V-A3节)。对于GoogLeNet,我们选择最后六个Inception模块(Inception 4b到Inception 5b)进行测试。图8为不同层的检索性能。正如我们所看到的,最初所有数据集上的mAPs都从较低的层提升到较高的层(从4b到4e),但是最后两个Inception层(5a和5b)的性能较差。分析结果表明,两层结构的空间结构和稀疏性较弱,可能是导致系统性能下降的原因。在Paris6k和Sculptures6k上,GoogLeNet比VGG19表现更好,在Oxford5k上GoogLeNet表现更好。
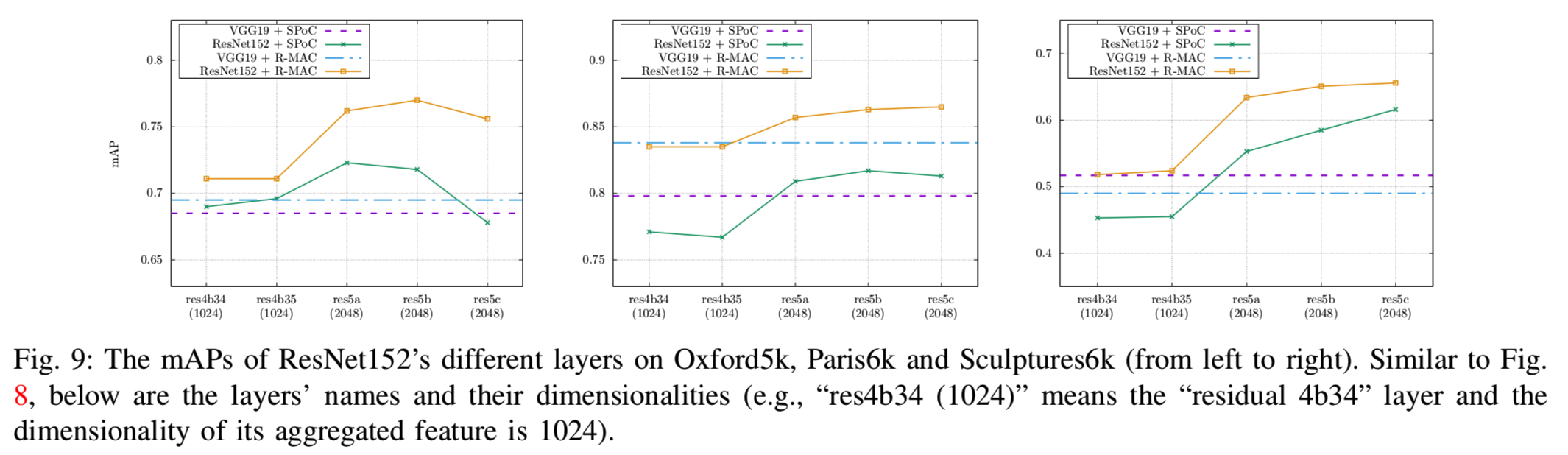
对于ResNet152,我们选择最后五个残差模块(res4b34到res5c)进行测试,如图9所示。从这个图中我们观察到,通常较高的层性能更好,ResNet152的最佳性能设置,即R-MAC的res5b,可以明显优于VGG19。然而,这些改进是以增加内存和计算成本为代价的:ResNet152的最佳实现层res5b的维数为2048,是VGG19的四倍。
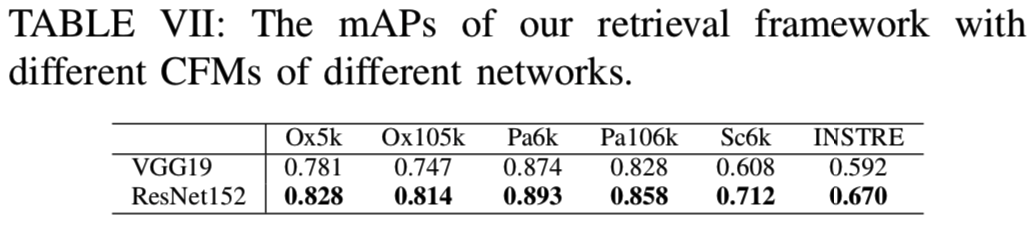
3)Final Integration: 最后,我们使用ResNet152的res5b层的CFMs来测试我们的方法。整个检索流程仍然是相同的:使用R-MAC进行初始检索,然后使用OSPP进行QAM重新排序,最后使用QE。注意,这里使用OSPP而不是FMP,因为通过对每个图像进行聚类,将FMP特征从R2048×2048缩小到R25×2048需要花费太多时间。结果显示在表VII中。我们可以看到ResNet152在所有数据集明显优于VGG19。实验结果表明了深度网络在实例检索中的有效性。然而,这些改进是以增加内存和计算成本为代价的。
VI. CONCLUSION
在这项工作中,我们提出了一个重新排序算法,即查询自适应匹配,例如使用卷积特征映射来检索。其核心思想是用一组基区域表示候选数据库图像,并利用与查询图像的相似性生成目标对象集中的focused表征。我们将相似度匹配和区域合并过程作为一个优化问题来阐述,可以有效地解决该问题。除了这个通用的框架,我们还提出了两种实际的方法来产生基区域。在多个实例检索数据集上的实验证明了该方法的有效性。