推荐系统和搜索引擎一直是比较火热的技术,因为离商业化比较近。她们是互联网领域两个衣着光鲜的美人,小腰一扭就是钱的味道。这几年凭借着两个红利:1. 互联网行业的经济红利、2. 硬件技术突破触发的炒热了深度学习冷饭带来的技术红利,推荐系统的效果有了比较明显的提升。
工业界的技术,从传统的人工先验特征设计组合+线性模型(如logistics regression),逐步过渡到了wide&deep、deepFM、DIN、GRU4REC、DIEN等等深度学习模型。这些深度学习模型普遍采用embedding的技术先将原始输入的离散高维信号投影到一个低秩的embedding空间,然后用不同结构的神经网络去拟合输入信号和输出的关系。神经网络的非线性能力可以部分学习不同输入信号之间的非线性关系,把人力从特征设计解放出来,研发一些新的技术。硬件的发展让我们拥有更多的计算资源,可以收集和利用更多的样本。这些条件让高自由度的深度学习模型普遍能取得更好的效果。
为什么之前不说推荐系统有了比较明显进展,而仅仅说效果上有提升呢?因为从技术层面来说,进入深度学习时代后,推荐系统像是各个应用技术领域中比较玩赖的一个。在深度学习时代,我们大部分情况下只是在利用别的领域诞生出的技术,却没有真正从自有领域出发找出特色的问题并在尝试解决的过程中提出新的技术,也没有从这个商业价值转化这么直接的场景研发出可以推广到其他领域的技术。从社会服务模式来说,推荐系统并没有形成新的服务形态,推荐系统还仅仅是掌握在平台手中,使用推荐系统的用户和推荐内容提供方都没能很好的参与到推荐系统的建设当中。推荐系统真的懂用户要什么吗?有想过能为推荐系统的内容提供者做点什么吗?
简单的说就是这个领域拿了很多钱,却没办太多事。
虽然我对自己从事这个领域的评价,嘴比较臭,但是我想的还是美的。我觉得推荐系统会走入下一阶段,成为一个能为社会提供更好的服务,同时还能源源不断的孕育新技术的好孩子。个人愚见,要步入下一阶段,我们需要研究三个重要问题:
1. 和真实应用场景贴近的统一benchmark。我们需要一个工业级、可以迭代真实应用场景技术的数据集。
2. 推荐系统的可解释性。在我看来可解释性重要的不是指导研究人员之后怎么迭代方法,而是增加透明性,让使用推荐系统的用户和为推荐系统提供内容的生产者能看得懂推荐系统,能参与进来。
3. 算法对系统数据的Confounding问题。可以简单理解为反馈循环(Feedback Loop)问题,简单来说就是算法会决定推荐系统展示给用户内容,从而间接的影响了用户的行为。而用户的行为反馈数据又会决定算法的学习。形成一个循环。
数据集
统一可迭代的数据集对一个领域技术发展的推动作用不言而喻。图像领域从mnist、cifar到ImageNet等等,这些开放的数据集为从业者提供了公平迭代的土壤。每个人有自己的想法都可以去尽力尝试,同时自己的想法有统一的标准可以验证,技术自然百花齐放。
反观推荐系统,大家迭代的数据集都不一样,数据集一样处理方式不一样,很难保证我们report出来的是一个可行的方法,而不是让这个方法可行的实验setting。还有一个比较大的问题是现在开放的数据集规模都和真实工业场景使用的规模相去甚远。推荐系统的真实场景很多问题本就是在真实规模的数据上才特有存在的。学术界和工业界在不同的数据上迭代,这就让产出的方法到真实应用间还存在着巨大的天然鸿沟。我还记得我在找实习的时候和面试官讨论问题,他们经常都会说出一句“工业界不是这样的,你的这个想法太天真”。现在我自己在工业界,我能认识到学界和工业界的区别,但是我想我们能尽量部分缩小这个鸿沟。至少让更多的人有机会参与到贴近实际应用场景的迭代中来。提供一个工业级的开放数据集,让更多的力量参与进来,总会碰撞出一些新的想法。同时大家提出的方法可对比,也就能一步一步的把技术推向更高。工业界把自己特有的问题通释化,让外界的人参与进来分担压力,自己也就能投入更多精力去攻克那些暂时还不可通释化的问题。可能会比说一句“工业界不是这样的”好。
当然要开源这样的一个数据集也面临特别的挑战,如何保护用户的隐私?大规模的数据集如何维护?如何让大家有能力使用这样的数据集等等... 虽然困难,但是我最近和一些同事已经在计划推进尝试开放这样的一个数据集。我相信也有很多同行也在规划类似的工作,最后我们总会有一个可以让大家公平有效迭代的土壤。
可解释性
推荐系统目前做的事情是把内容(如商品、新闻、音乐等)和用户联系起来,让用户更高效的接触对自己有意义的内容。我们用 来表示某个商品,其中
一共有
个商品,
来表示某个用户,其中
一共有
个用户。同时用
表达将
推荐给
产生的价值(可以是点击成交等可直接量化的指标,或者是用户的满意度等)。现在推荐系统做的事情是通过预估
来决定如何在有限的推荐机会中最大化总体的推荐价值
, 其中
代表推荐系统给用户
选取的推荐内容集合。我们的目标其实是让推荐产生的价值更大,但是目前我们的推荐系统局限于通过预估
来决定推荐给用户的
,仅仅从分配推荐机会的角度来优化推荐价值。
可是这个游戏的参与方不仅仅是推荐系统,还有为系统提供内容的内容生产者,以及用户。如果推荐系统仅仅是分配流量,那么它本身能创造的价值有限,为什么不能让内容生产者和用户参与一起创造新的价值,做大这个蛋糕呢。如果内容生产者能提供更优质的内容,是不是总体的推荐价值会变大。推荐系统目前预估推荐价值 很大程度上依赖用户的反馈,如果用户能提供更真实,更准确的反馈是不是能更准确的预估推荐价值
从而提升总体的推荐价值。如果我们在建设推荐系统的技术时仅仅局限于平台自己如何精准的预估
,那么总体的推荐价值是有上限的。我们需要的是寻找如何让内容生产者和用户参与到优化推荐系统的桥梁。
最近几年,在如何更精准的预估推荐价值 上,有不少有效的模型被提出(大部分是深度学习的方法),但是这些模型也越来越黑盒化了。不仅仅是用户和内容提供者不明白推荐系统推荐的逻辑,就连做这些模型的工程师、把控推荐系统平台的人也不了解每一次推荐的逻辑。面对这样一个黑盒的系统,内容提供方和用户不能理解,如何能很好的参与进来呢。
有意思的是即使在这样一个黑盒的推荐系统下,内容提供方和用户其实是有意识或者有欲望想参与建设更好的推荐系统的。不过由于目前系统的黑盒特性,导致大家不知从何入手。举几个例子。从内容生产者来说,我们以电商为例,大家可以看一下淘宝上那些商品的“标题”。
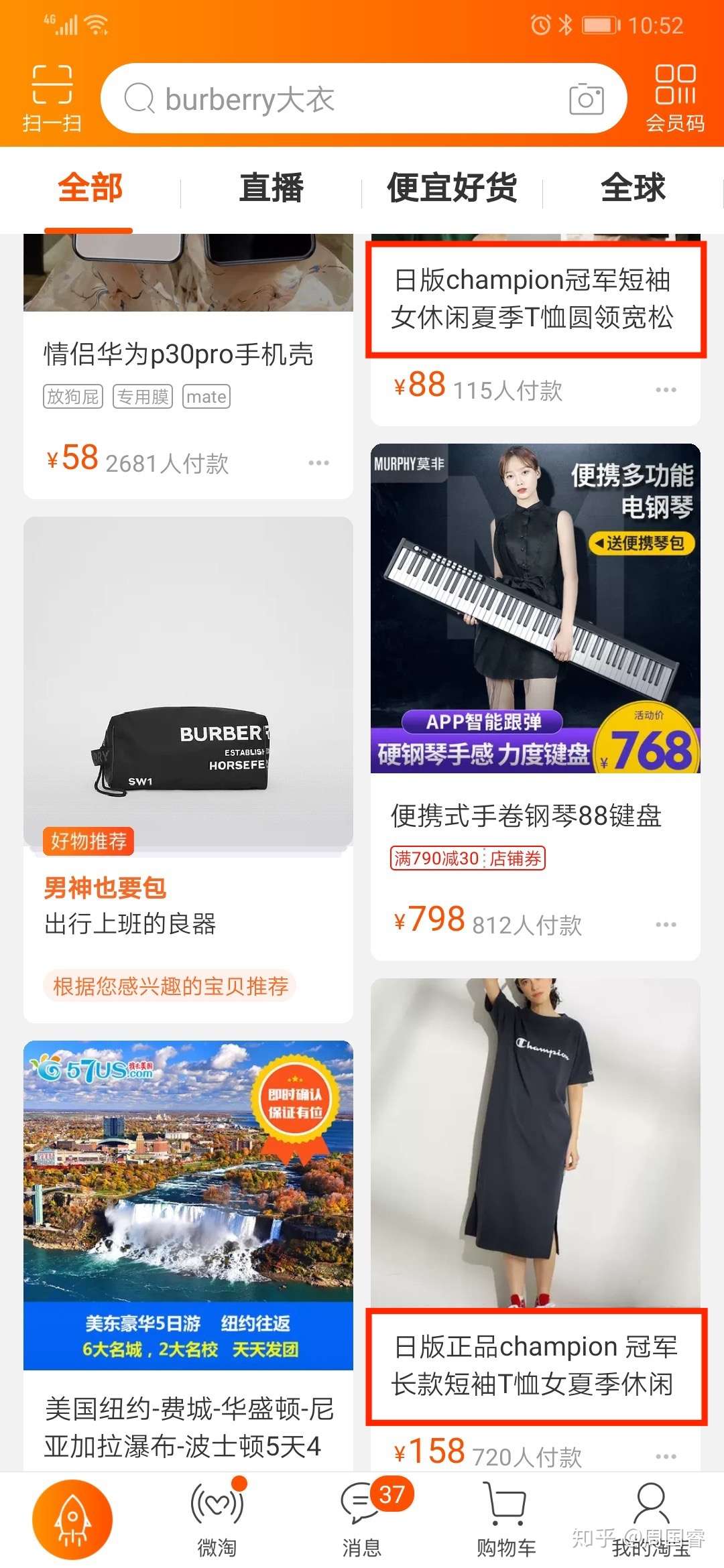
这些标题,在简短的标题中,出现了大量的属性词,可读性并不强。很多时候这些标题可能承载了商家通过标题来影响推荐系统从而获取更多的流量的期望。从用户角度来说,我们就以豆瓣为例,大家对内容是有很强的评价意识的。只是很多场景,我们可能只能通过用户的点击之类的信号来建模推荐价值 。这个时候我们会研(bao)究(yuan)用户的点击信号是带有大量噪声的。但是用户又能怎样呢?是不是很多时候是我们展现给用户的内容具有误导性呢(想象一下商品推荐场景的美女图片)?
为什么可解释性可能是让内容生产者和用户参与到优化推荐系统的桥梁呢?想象一下,如果我们的推荐系统不仅仅是建模了推荐价值 ,而是我们真正建模了用户的兴趣,且这个兴趣我们能白盒化的给出一些人能理解的解释。推荐系统可以实时的去预估未来用户的兴趣。那么如果这些兴趣不再是一串无法理解的数字(embedding),如果是人类可以理解的兴趣,比如比较简单的文字标签。这样一些人类可以理解的兴趣是不是可以指导内容生产者去生产更满足用户需要的内容呢。而更丰富更满足用户需要的内容自然会将整个系统的推荐价值推到更高。同时推荐系统推荐某个商品的逻辑,是不是可以显式的透传给用户,让用户给出对这个推荐逻辑的反馈,而不是仅仅给出对推荐结果的反馈。让我们能更接近感知用户真实的兴趣。这样推荐系统的学习也有可能变得更精准。这两个只是我比较局限的思考给出的两个例子。基本的逻辑是,让推荐系统变得白盒化,或者有白盒化的能力,让内容生产者和用户的力量一起加入到推荐系统的优化中来。而不是仅仅推荐系统自说自话,让这个系统变得越来越不可琢磨,不可理解,让用户和内容生产者都无从入手。
算法对数据Confounding
先用一张简图介绍一下反馈循环(Feedback Loop):
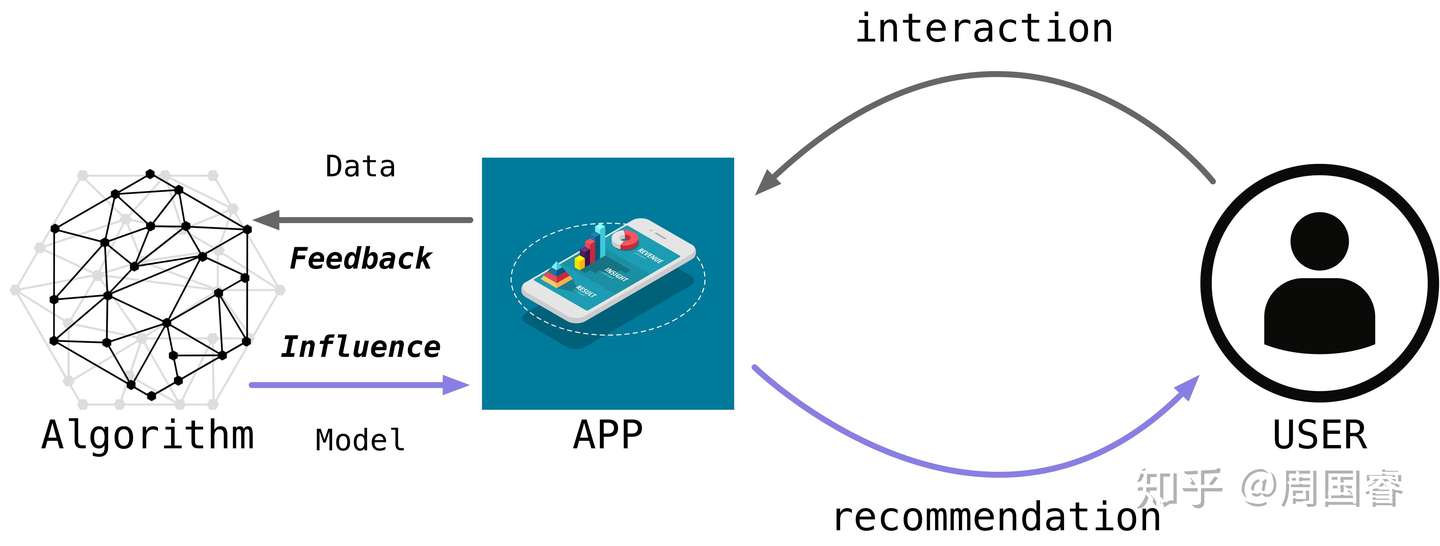 算法决定了模型,模型决定了推荐的结果,推荐的结果会影响用户的决策和行为,最后用户的行为数据又回到影响算法训练出的模型。算法、平台、用户整个形成了一个反馈的循环。
算法决定了模型,模型决定了推荐的结果,推荐的结果会影响用户的决策和行为,最后用户的行为数据又回到影响算法训练出的模型。算法、平台、用户整个形成了一个反馈的循环。 简单来说,算法对数据的confounding就是算法会改变了整个系统能观测到的数据分布,而feedback loop导致算法永远在一份已经被自己confunded(混淆)过的数据上进行训练和观测,无法跳出这一循环。甚至有很大的可能会在这个循环中让整个系统逐步收敛,所能观测的数据分布越来越局限,从而引发一些列问题。
举个例子。有一小部分用户part A,他们的喜好很特别,但是现有算法无法很有效的将part A和其他大部分用户part B区分开。那么这些用户的数据无法很好的影响算法的训练,导致模型最终决定了推荐系统给part A推荐的结果和part B推荐的结果一样。part A的用户不喜欢这些推荐结果,给出了负向的反馈,然而推荐系统的优化目标是整体的准确率或者收益,这部分用户的反馈就被忽视掉,模型继续往part B所在的那部分优化。慢慢的part A用户和平台的交互可能变得越来越少,最终推荐系统成功的挤走了这部分用户。这个时候,即使有一个算法能给part A用户提供好的推荐结果,它也再没有机会为part A的用户服务了,也没有机会证明自己。而这一切发生得是很隐蔽的,可能系统都没意识到自己丢失了这部分价值。
从道德上讲,这样对少数派的忽略是不公平的。从商业价值上讲,可能短期看上去仅仅失去占比很少的少数派代表的价值,然而如果我们的系统这样循环下去,其实是在源源不断的失去一小部分价值,累积起来是非常大的损失。算法对数据的confounding让系统观测的数据分布逐步收敛,让整个系统的收益边界不断缩小,慢慢陷入无法迭代提升的境地。
可能有同学会觉得这就是一个简单的系统需要explore问题。然而推荐系统涉及到商业价值,explore变得不是这么简单。我们需要:1. 衡量explore带来的收益和成本 2. 高效的explore方法。1和2在学术界都有非常多的研究,但是在一个快速迭代的工业系统中,这两个问题变得相当艰难。这要求我们必须在很短的周期内explore产生收益并可以衡量explore的效果,不然就得拥抱系统的变化,很多时候可能还得拥抱人事组织的变化 : )
总结
如果把优化推荐系统的准确率是一个一阶梯度learning方向,可能它吸引了我们过多的精力。优化推荐系统,可以从更多的视角来推动。统一的benchmark、可解释性(透明化)、算法对数据confounding这几个问题的推动可能更像是一种更上层对推荐系统meta-learning。当然了,推荐系统研究发展的环境和氛围并没有我前面表达的那么悲观,还是有很多人在这个领域提出了很多有趣的想法,在一些很tough的问题上持续的努力。最后和大家一起共勉,希望我们能见到更公平、更高效、更满足用户时刻变化需要的推荐系统。