来源:https://mp.weixin.qq.com/s/xA0TTSiIoFlzv0PKQheuWA
一 什么是 Back Pressure
如果看到任务的背压警告(如 High 级别),这意味着 生成数据的速度比下游算子消费的的速度快。以一个简单的 Source -> Sink 作业为例。如果能看到 Source 有警告,这意味着 Sink 消耗数据的速度比 Source 生成速度慢。Sink 正在向 Source 施加反压。
许多情况都会导致背压。例如,GC导致传入数据堆积,或者数据源在发送数据的速度上达到峰值。如果没有正确处理反压力,可能会导致资源耗尽,甚至在最坏的情况下,数据丢失。
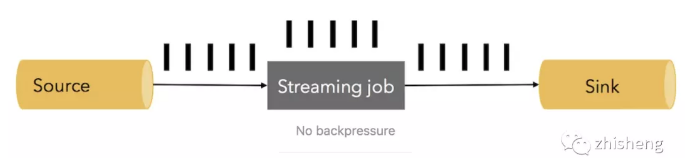
看一个简单的例子。假设数据流 pipeline(抽象为 Source,Streaming job 和 Sink)在稳定状态下以每秒500万个元素的速度处理数据,如下所示正常情况(一个黑色条代表100万个元素,下图表示系统1秒内的快照):
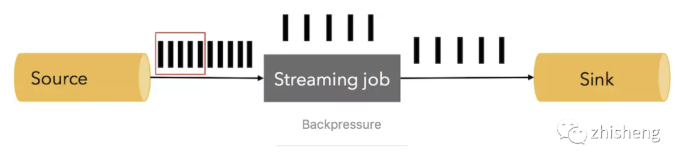
如果 Source 发送数据的速度在某个时刻达到了峰值,每秒生成的数据达到了双倍,下游的处理能力不变:
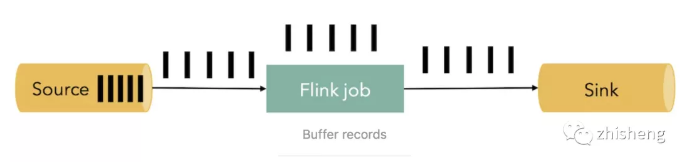
消息处理速度 < 消息的发送速度,消息拥堵,系统运行不畅。如何处理这种情况?
a. 可以去掉这些元素,但是,对于许多流应用程序来说,数据丢失是不可接受的。
b. 将拥堵的消息缓存起来,并告知消息发送者减缓消息发送的速度。消息缓存应该是持久的,因为在发生故障的情况下,需要重放这些数据以防止数据丢失。
二 背压实现
采样线程
背压监测通过反复获取正在运行的任务的堆栈跟踪的样本来工作,JobManager 对作业重复调用 Thread.getStackTrace()。
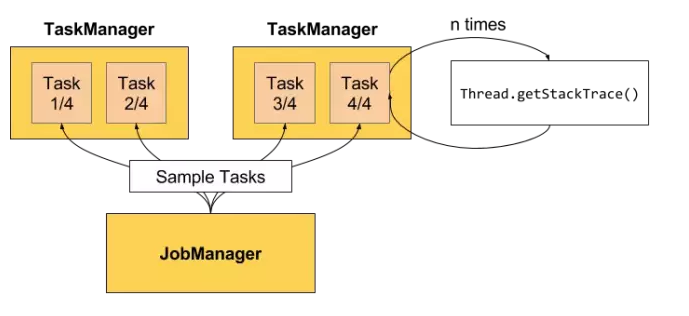
如果采样(samples)显示任务线程卡在某个内部方法调用中,则表示该任务存在背压。
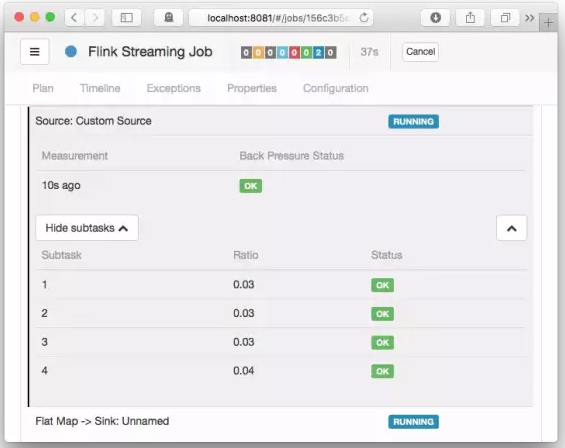
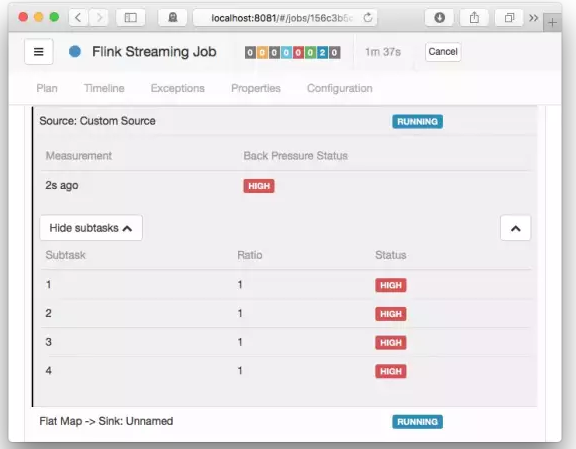
默认情况下,JobManager 每50ms为每个任务触发100个堆栈跟踪,来确定背压。在Web界面中看到的比率表示在内部方法调用中有多少堆栈跟踪被阻塞,例如,0.01表示该方法中只有1个被卡住。状态和比率的对照如下:
OK:0 <= Ratio <= 0.10
LOW:0.10 <Ratio <= 0.5
HIGH:0.5 <Ratio <= 1
为了不使堆栈跟踪样本对 TaskManager 负载过高,每60秒会刷新采样数据。
配置
可以使用以下配置 JobManager 的采样数:
web.backpressure.refresh-interval,统计数据被废弃重新刷新的时间(默认值:60000,1分钟)。web.backpressure.num-samples,用于确定背压的堆栈跟踪样本数(默认值:100)。web.backpressure.delay-between-samples,堆栈跟踪样本之间的延迟以确定背压(默认值:50,50ms)。
三 Web 显示
在 Flink WebUI 的作业界面中可以看到 Back Pressure 选项页面。
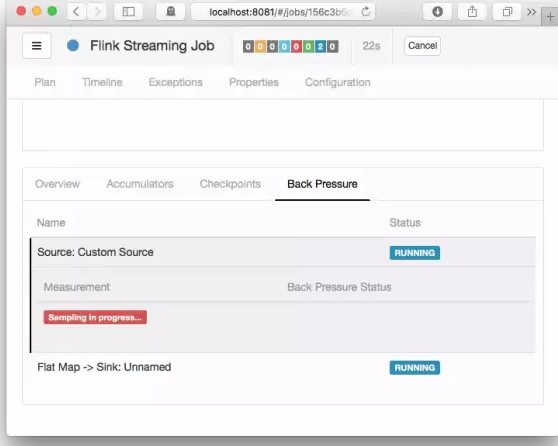
采样中
表示 JobManager 对正在运行的任务触发堆栈跟踪采样。默认配置,大约会花费五秒钟。
背压状态
运行正常状态
背压状态
四 对比 Spark streaming
Spark Streaming 的 back pressure 是从1.5版本以后引入。在之前版本,只能通过限制最大消费速度。这种限速的弊端很明显,假如下游处理能力超过了这个最大的限制,会导致资源浪费。而且需要对每个 Spark Streaming 作业进行压测预估,成本比较高。
从1.5版本开始引入了 back pressure,实现自动调节数据的传输速率,其监听所有作业的 onBatchCompleted 事件,并且基于 processingDelay、schedulingDelay、当前批处理的记录条数以及处理完成事件来估算出一个速率,用于更新流每秒能够处理的最大记录的条数。会随着数据能力进行调整,来保证 Spark Streaming 流畅运行。
对比来看,Spark Streaming 的 back pressure 比较简单,主要是根据下游任务的执行情况等,来控制 Spark Streaming 上游的速率。Flink 的 back pressure 机制不同,通过一定时间内 stack traces 采样,监控阻塞的比率来确定背压的。